

This article is part of our coverage of the latest in AI research.
Self-distillation has emerged as an effective post-training paradigm for large language models, often improving performance while shortening reasoning traces. However, recent research by Microsoft Research, KAIST, and Seoul National University reveals a major flaw in this approach.
In mathematical reasoning, self-distillation inadvertently suppresses behaviors that allow models to explore alternative hypotheses and self-correct during complex problem-solving. As a result, the models become significantly less accurate on out-of-distribution problems.
The key takeaway is that optimizing post-training solely to reinforce concise, correct reasoning traces can quietly destroy a model’s ability to generalize. Across various open-weight models, researchers found that self-distillation can cause performance drops of up to 40% on unseen tasks.
For models to maintain their robust reasoning abilities, they must be exposed to different levels of uncertainty during training.
What is self-distillation?
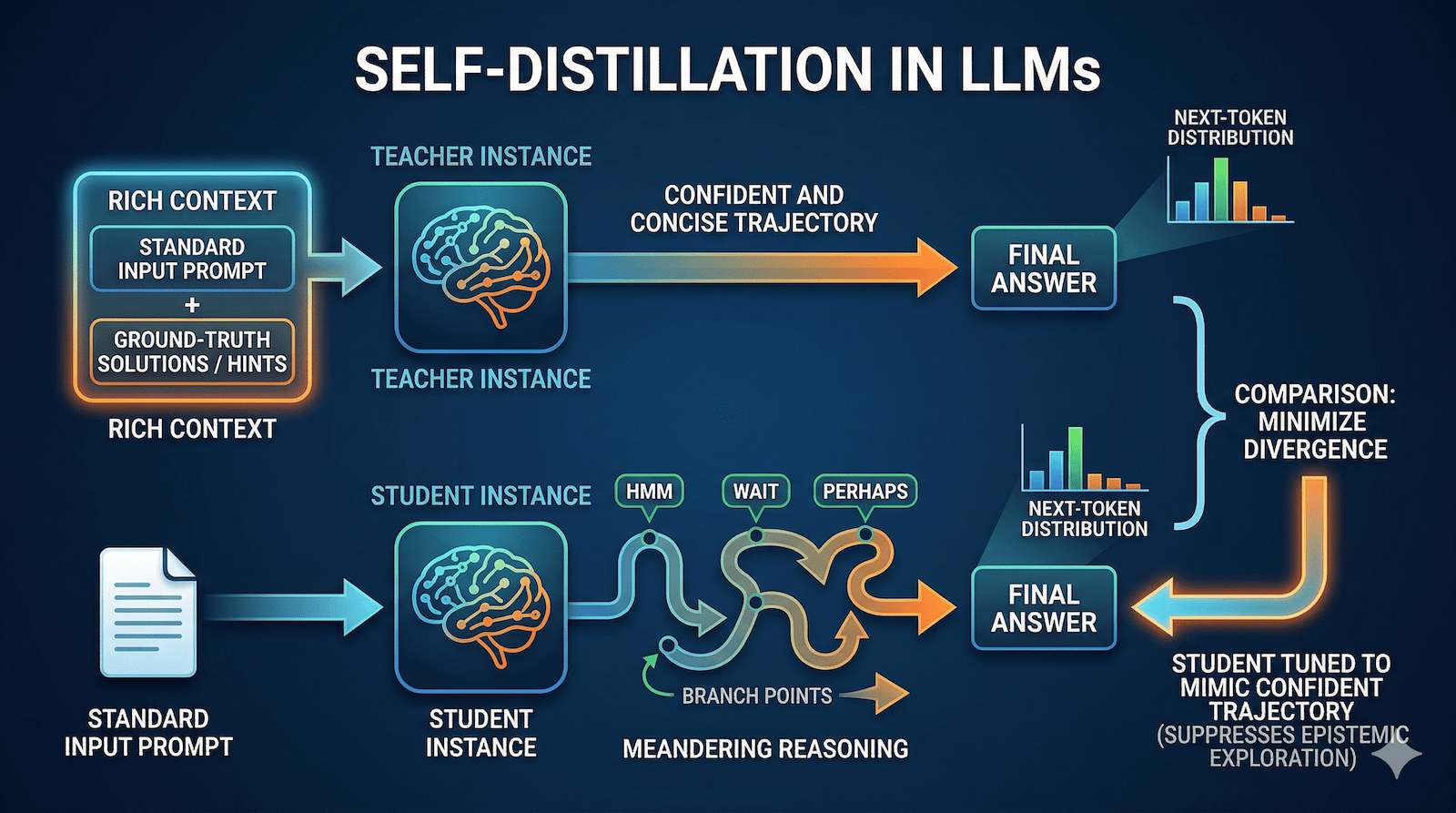
In standard distillation pipelines, a massive teacher model provides training signals to a smaller, more efficient student model. Self-distillation alters this formula by employing two instances of the exact same model as both teacher and student.
The student model generates reasoning sequences based solely on a standard input prompt. Meanwhile, the teacher model receives a much richer context, such as the ground-truth solution, environment feedback, or other auxiliary signals.
The training process tries to minimize the divergence between the student and teacher’s next-token distributions. Because the teacher is guided by privileged information, it naturally produces highly concise and confident reasoning trajectories with minimal uncertainty. By training the student to match these predictions, the model is encouraged to internalize the hints derived from the rich context. The model distills information available at training time without requiring an external teacher.
When combined with methods like Reinforcement Learning from Verifiable Rewards (RLVR) (a popular training technique that rewards the model when its final output matches an objectively correct answer) self-distillation leads to highly efficient performance gains in agentic environments and scientific reasoning domains. In these domains, the approach achieves higher accuracy while compressing the reasoning process, leading to shorter and more effective model responses.
Yet, these impressive gains do not translate uniformly across all cognitive tasks, as the experiments of the new study show.
Testing the limits of self-distillation
To investigate the impact of self-distillation on mathematical problem-solving, the researchers ran extensive experiments with several open-weight language models, including a distilled 7B version of DeepSeek-R1, Qwen3-8B, and Olmo3-7B-Instruct.
The models were trained using the DAPO-Math-17k dataset, which contains thousands of mathematical problems. To test out-of-distribution generalization, they evaluated the fine-tuned checkpoints on unseen or more challenging math benchmarks, including AIME24, AIME25, AMC23, and MATH500.
The researchers compared Group Relative Policy Optimization (GRPO) against Reinforcement Learning via Self-Distillation (SDPO). They also conducted off-policy supervised fine-tuning experiments, contrasting models trained on standard unguided responses against models trained on concise, solution-guided responses.
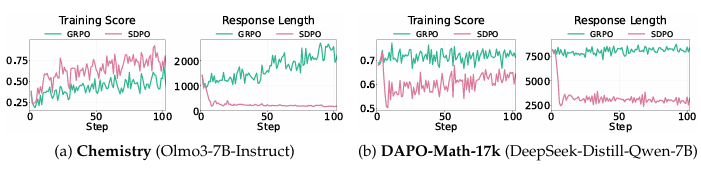
The baseline GRPO consistently yielded modest performance gains on the out-of-distribution benchmarks. It also prompted a slight increase in response length.
SDPO resulted in a sharp drop in response length and led to substantial performance degradation. Performance dropped by roughly 40% on the AIME24 benchmark and 15% on AMC23. The off-policy experiments mirrored this trend. Training on concise, solution-guided trajectories drastically degraded benchmark scores, despite the training dataset consisting entirely of correct mathematical traces.
The researchers also observed very different outcomes when they manipulated the size and diversity of the training tasks. When trained on a small number of questions, ranging from 1 to 128 problems, SDPO proved highly efficient. It achieved high training scores while compressing response lengths by up to eight times compared to GRPO.
However, as the task coverage expanded to include hundreds or thousands of diverse problems, the dynamic entirely reversed. GRPO’s out-of-distribution performance scaled consistently as the dataset grew. SDPO struggled to accommodate the broader range of reasoning patterns, resulting in severe performance drops on evaluation benchmarks when trained on the larger problem sets.
The importance of expressing uncertainty
To understand the root cause of these performance drops, the researchers focused on “epistemic verbalization,” the model explicitly expressing uncertainty during its reasoning process with tokens such as “wait,” “hmm,” “perhaps,” and “maybe.”
Large language models do not plan their entire answer in advance; they calculate probabilities sequentially. Tokens like “wait” or “perhaps” act as functional computational steps for the model.
When a model verbalizes uncertainty, it successfully maintains alternative hypotheses and supports a gradual reduction of uncertainty. Conversely, when this behavior is artificially suppressed, the model loses the capacity to iteratively refine its beliefs. It prematurely commits to incorrect hypotheses with limited opportunity for recovery or self-correction.

The researchers found that self-distillation inherently suppresses these epistemic signals due to the highly informative context provided to the teacher model. When the teacher possesses the final correct solution, it generates a reasoning trajectory filled with strong hints and minimal expressed uncertainty.
By forcing the student model to mimic this output, the training process encourages the student to imitate a highly confident reasoning style that presupposes information it lacks at inference time. As the conditioning context becomes richer, the model generates answers more confidently and systematically strips away its own epistemic verbalizations.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
This trained removal of uncertainty has implications for out-of-distribution generalization. The value of epistemic verbalization scales directly with the generalization demands of a task. When task coverage is narrow and repetitive, suppressing uncertainty enables rapid optimization and efficiency.
Yet, as task diversity increases, the aggressive removal of epistemic markers actively interferes with the model’s ability to optimize across diverse tasks. Stripped of its exploratory mechanisms, the model cannot successfully navigate unseen and challenging problems.
Practical implications
If you want to train a self-distilled model or use one, the core tradeoff you must consider is response efficiency versus generalizable reasoning capability. Self-distillation can impressively compress a model’s response length, as shown in the experiments. It filters out unnecessary verbosity and significantly drives down inference compute costs. But this compression directly risks eliminating the vital signals that models rely on to self-correct and adjust hypotheses mid-generation.
You can comfortably apply self-distillation in narrow, well-defined domains where the task coverage is limited, familiar, or highly repetitive. For instance, the researchers found that self-distillation is very effective in specific scientific domains like chemistry or specialized coding environments. In these datasets, the underlying problem structures remain very similar, even if surface details change. In these precise scenarios, explicit expressions of uncertainty are largely redundant. They can be safely removed to make responses faster and potentially more accurate.
Conversely, developers should avoid relying heavily on self-distillation in broad, complex domains that demand strong out-of-distribution generalization beyond the initial training examples. When a model must handle a vast array of unseen, non-overlapping problem types, preserving its ability to express uncertainty and iteratively refine its beliefs is critical for success. If self-distillation is applied to these broad problem sets, the aggressive, trained removal of epistemic signals acts as a straitjacket. It actively interferes with the model’s ability to adapt to new challenges, fundamentally capping its reasoning potential.