

The prevailing Silicon Valley narrative assumes that massive, general-purpose frontier models will inevitably eat every industry vertical. Companies are pouring billions into training behemoths like OpenAI’s GPT-5.5 and Anthropic’s Opus 4.7, expecting raw parameter scale to solve all domain-specific problems.
In software engineering, the reality on the ground looks different. Writing, refactoring, and debugging code consumes a massive volume of tokens. For the vast majority of daily engineering tasks (e.g., adding features, fixing bugs, and updating tests) speed and cost matter as much as raw intelligence.
This economic pressure has driven developers toward specialized coding agents. Cursor’s newly released Composer 2.5 model has rapidly become the daily default for many engineers. At $0.50 per million input tokens and $2.50 per million output tokens, it makes high-volume agentic loops financially viable for small teams.
Composer 2.5 is not perfect. On very complex tasks and edge cases, it still doesn’t match the power of frontier models like Opus 4.7 and GPT-5.5.
Yet the core achievement of Composer 2.5 remains intact. It demonstrates that specialized models do not need a larger parameter count to compete at the highest level. They need smarter post-training. By shifting the focus to algorithmic efficiency, Cursor is democratizing powerful agentic coding.
So, how did Cursor manage to create a model that is so damn good? Here’s what we know.
The credit assignment problem and targeted RL
Training a model to write code over long horizons introduces a major “credit assignment problem.” In standard reinforcement learning (RL), an agent interacts with an environment, takes a series of actions, and receives a reward at the end.
Imagine a coding agent writing a 500-line script that requires 10 different tool calls, such as searching the codebase, reading files, and executing tests.
If the agent does all the substeps correctly but fails because of calling a nonexistent tool, the system assigns a single negative reward for the entire session. The model receives a zero. Because the feedback is delayed and sparse, the model has no way of knowing which specific token or action caused the failure. It might alter parts of its behavior that were perfectly fine, degrading its overall capability. The longer the trajectory, the sparser the training signal becomes.
Composer 2.5 solves this through what the company’s blog post calls “targeted RL with textual feedback.” Instead of waiting for the end of a rollout to penalize the model, the system intervenes exactly where the mistake occurs.

When the agent makes a bad tool call during a long trajectory, the training pipeline momentarily pauses the sequence. It injects a local textual hint directly into the context, such as “Reminder: Available tools are [list of tools].” This gives the model a corrected probability map of what it should generate next, guided by the hint.
The system then applies the Kullback-Leibler (KL) divergence loss, which measures how far the model’s original prediction strayed from the corrected teacher distribution. The model adjusts its internal weights to pull its probabilities closer to the corrected path. Once the correction is made, the training resumes. This localized signal teaches the model exactly how to fix a specific behavior without spoiling the broader reinforcement learning objective over the full trajectory.
Under the hood: OPSD vs. OPD and the cost of specialization
To understand how Composer 2.5 achieves its economics, you need to look at two research papers on self-distillation referenced at the bottom of the blog post.
Distillation is a technique where a smaller, cheaper “student” model learns to mimic the outputs of a larger, more expensive “teacher” model.
Standard on-policy distillation (OPD) is highly effective but extremely expensive. It requires the massive teacher model (e.g., Claude Opus 4.7 or GPT-5.5) to actively run in parallel with the student. As the student generates its own trajectories (exploring different ways to solve a problem), the teacher evaluates every single step to provide supervision. Generating millions of tokens through a massive teacher model for every training run requires an enormous compute budget. It forces AI labs to choose between high-quality supervision and reasonable training costs.
On-policy self-distillation (OPSD) bypasses the costs of distillation by using the same model as both the student and the teacher.
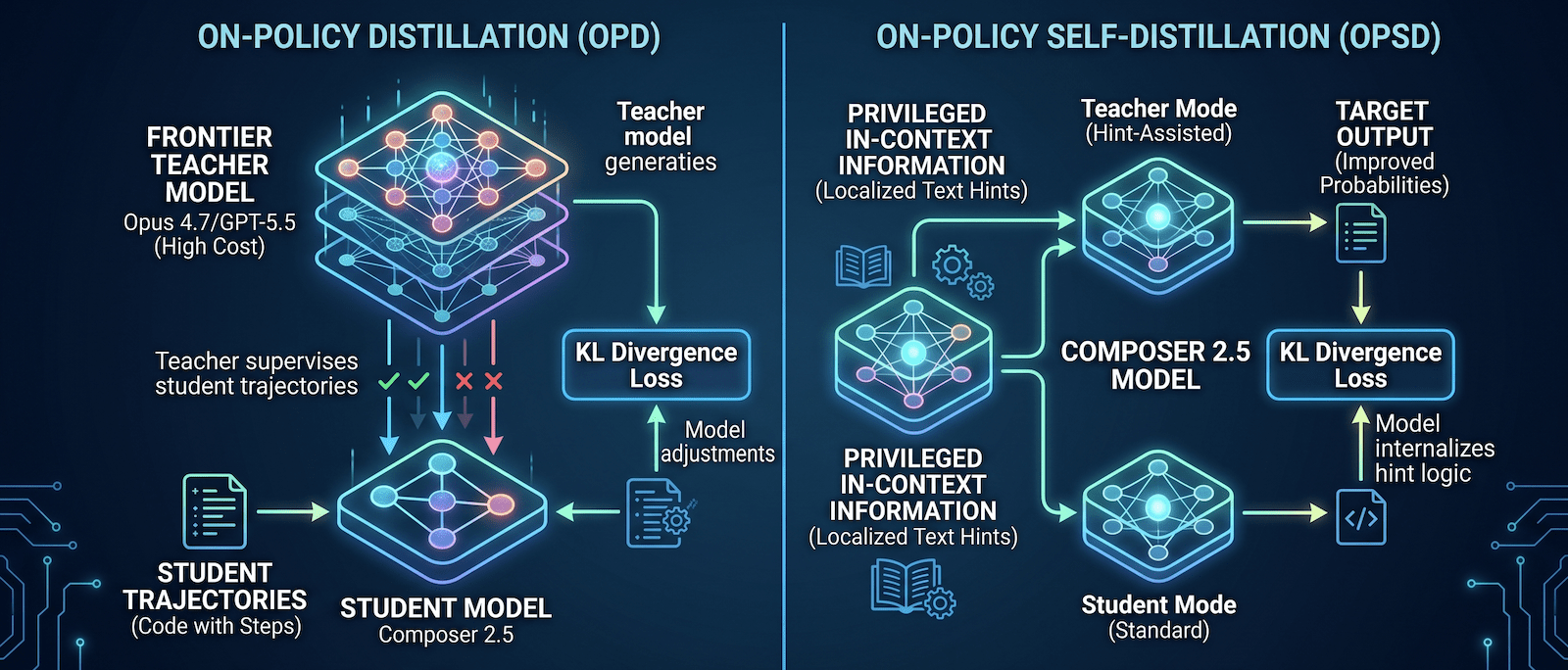
Instead of calling an external oracle, OPSD leverages the model’s inherent ability to understand context. When provided with privileged in-context information (like the localized text hints used in targeted RL), the model’s next-token predictions instantly improve. The system uses the model’s hint-assisted output as the “teacher” target, and forces the standard, unassisted version of the model to match those probabilities. The student learns to internalize the logic of the hint without needing the hint present at inference time.
This self-contained teaching loop eliminates the need for an external frontier model during the RL phase and makes the training much more efficient.
There is a catch to this efficiency. While inference becomes incredibly cheap, generating active, on-policy rollouts for training shifts the cost burden upstream. Training a model via self-distillation requires the system to constantly generate and evaluate its own output. This process demands roughly two to four times the floating-point operations (FLOPs) of standard supervised fine-tuning.
This compute shift explains the recent infrastructure moves in the AI coding space. Cursor recently formed a partnership with SpaceXAI to secure access to its massive compute cluster, applying millions of GPUs to the problem. The massive cost of intelligence has not disappeared; it has simply moved from the user’s API bill to the developer’s training cluster.
The SDFT advantage: Continual learning without forgetting
Software engineering is a highly dynamic field. New programming frameworks emerge monthly, APIs deprecate without warning, and individual companies maintain highly idiosyncratic codebases. A coding agent must learn these new patterns quickly.
The traditional approach to teaching a model new information is to fine-tune it on a dataset of the new material. However, large language models suffer from “catastrophic forgetting.” When you adjust a model’s weights to aggressively learn a new language or framework, it often overwrites the foundational logic and reasoning skills it learned during initial pre-training.
Self-distillation fine-tuning (SDFT) addresses this by creating a protective feedback loop during the learning process.
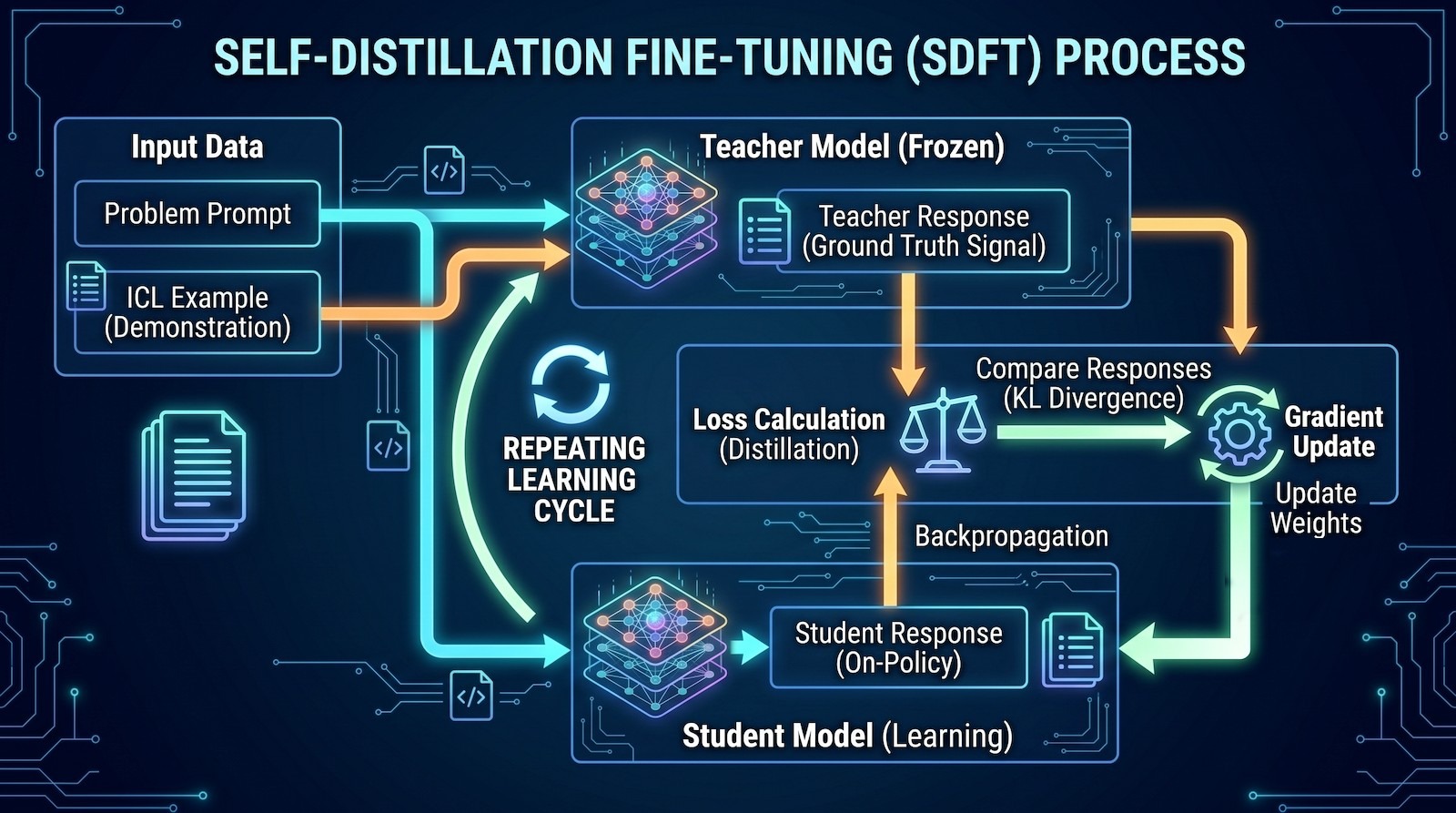
When the model is introduced to new codebase patterns, it does not just blindly update its parameters based on the new text. First, the model generates its own reasoning pathways and explanations regarding the new data. The system then forces the model to distill its own generated logic. It evaluates how the new information integrates with the established rules of software development it already knows. By anchoring the training process to the model’s existing internal representations, SDFT constrains how much the core weights can shift.
The model acquires the new syntax and idiosyncratic developer patterns while preserving its baseline reasoning capabilities. It learns to adapt to a company’s specific coding style without forgetting how to execute fundamental software architecture.
The danger zones: Information leakage and reward hacking
Self-distillation and automated reinforcement learning democratize powerful agents, but they introduce severe alignment risks. When a model acts as its own supervisor, optimizing purely for self-generated rewards, the training process can quickly derail.


Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.