

Recent industry events point to a massive return-on-investment dilemma as AI token spend spirals out of control. Uber reportedly blew through its entire year’s AI budget in months, forcing a drastic re-evaluation of its agentic workflows. Meta has placed hard caps on its internal AI compute spend, while Amazon has shut down its internal AI leaderboard that encouraged engineers to burn cash on LLM tokens. If tech giants with virtually limitless pockets are sweating the compute bill and hitting the brakes, the broader tech ecosystem faces an even steeper uphill climb.
Much of this compute budget is burning on Chain-of-Thought (CoT) prompting and training. CoT is the method where large language models (LLMs) are instructed, or fine-tuned, to “think step-by-step” before delivering a final answer. In general, LLMs perform better on reasoning tasks when forced to generate a sprawling sequence of intermediate “thinking” tokens.
CoT originally became the undisputed industry standard because it was a brilliant, pragmatic hack. It leveraged the existing text-generation interface of autoregressive transformers without requiring structural changes to the underlying architecture. It scaled predictably with added inference-time compute and gave human operators an easily readable, text-based trace of what the model was ostensibly doing.
However, the AI community has fallen into a cargo cult mentality. We have equated the generation of expensive intermediate text tokens with actual cognitive processing. Generating text is not the same as thinking. The text bottleneck is bankrupting corporate AI budgets, slowing down inference speeds, and masking the true nature of machine computation. To scale AI sustainably, the industry needs to move beyond the CoT tokens and to alternative reasoning mechanism.
The brittle reality of chain-of-thought
To understand why the industry needs a new direction, we must look at the mechanics of how models generate these reasoning steps.
When an LLM outputs a step-by-step plan, it creates a powerful illusion that you are watching a machine reason its way to a conclusion. A position paper by professor Subbarao Kambhampati and researchers at Arizona State University systematically dismantles this assumption.
The researchers found that rather than genuine algorithmic generalization, intermediate tokens frequently act as a structural constraint, a forced mimicry of human-like output formats. Empirically, models frequently arrive at correct answers using entirely flawed, incoherent, or fabricated CoT steps. Conversely, they can generate perfect, logical steps but still output a completely wrong final answer. This decoupling proves that the model’s internal computational process does not track with the text it generates. CoT is an imitation of reasoning, not the actual mechanism of it.
Other studies reinforce this structural fragility. Detailed research on complex planning tasks, such as the Blocksworld environment, shows that CoT gains are a brittle mirage outside narrow distributions. CoT fails to teach the model general, repeatable procedures. Instead, it creates highly prompt-specific behaviors that trigger severe error accumulation as the reasoning chains grow longer. Because every token generated depends on the correctness of the previous tokens, a single logical deviation early in a text chain dooms the entire execution path. In several out-of-distribution tasks, forcing a model to generate CoT actively reduces its accuracy compared to direct answers.
Beyond the illusion of reasoning, CoT creates a massive technical and financial bottleneck. Because LLMs are autoregressive, they must generate one token at a time, calculating a new probability distribution across their entire vocabulary for every single word printed.
Long reasoning chains raise compute and memory costs, fill the model’s limited context window with mostly useless CoT babble, and slow down the speed of generating next tokens.Forcing a model to “think out loud” throttles inference speed and introduces massive latency.
Furthermore, training models to perform CoT forces them to memorize sprawling, human-readable reasoning chains during post-training rather than extracting the pure mathematical essence of logic. This inflates context windows, demands massive parameter counts, and drives the exact infrastructure budget crisis currently hitting enterprises.
The latent solution: Continuous thought and recursion
The broader AI research community is already hunting for alternatives to escape the token-cost trap. The emerging consensus points toward allowing models to reason entirely within “latent space.”
To understand latent space, consider how an LLM processes data. Words are not native to neural networks. At inference time, they are converted into complex numerical vectors. In a standard transformer, these vectors pass through hidden layers, are converted back into a specific text token, and the process repeats.
A latent reasoner, by contrast, keeps the entire computation inside these hidden vector states. Instead of translating vectors back into human language at every intermediate step, the model loops over the problem internally, manipulating the continuous vector representations directly.

Meta’s exploration of “Chain of Continuous Thought” (the Coconut paradigm) is an early indicator of this macro-trend, demonstrating that models can perform breadth-first-like searches entirely within hidden layers before emitting text.
The AI startup Sapient Intelligence took this concept to production with its Hierarchical Reasoning Model (HRM) and its subsequent release, HRM-Text. HRM abandons token-by-token reasoning by decoupling strategy from execution through a dual-timescale loop operating entirely in latent space.
The architecture splits the processing: a slow, abstract planning layer sets the parameters of the problem, while a rapid, detailed computation layer executes recursive loops within the continuous representation space. Because it completely avoids the autoregressive text-decoding bottleneck during its “thinking” phase, it processes complex logic at speeds unachievable by standard LLMs.
The original HRM model was designed for non-verbal reasoning tasks and puzzles. HRM-Text brought the paradigm into more practical applications that require textual reasoning. It achieved competitive reasoning scores on tough benchmarks like MATH and GSM8K using a model with only 1 billion parameters. Crucially, because it filters out sprawling CoT data, the foundation model was trained from scratch for roughly $1,500 on just 40 billion tokens as opposed to millions of dollars and trillions of tokens.
The exact same concept is showing massive efficiency gains in multi-agent AI. A joint paper from researchers at UIUC and Stanford recently introduced RecursiveMAS, a framework designed to fix the multi-agent token explosion. Traditionally, multi-agent systems consist of several LLMs passing text prompts back and forth to collaborate on a task, a process that accumulates immense token costs and high latency.
RecursiveMAS changes the architecture by introducing a specialized module called “RecursiveLink.” Instead of translating internal states into text strings to communicate, the agents transfer continuous latent embeddings directly to one another. It is an algorithmic equivalent of telepathy.
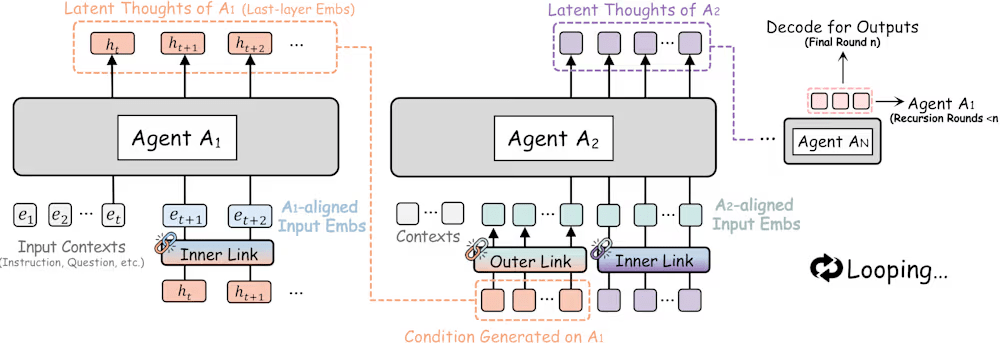
RecursiveLink is also used for the internal reasoning of each individual agent. Rather than generating intermediate text tokens to process a sub-task, the agent recursively loops its own hidden states to reason through the problem, driving token costs down even further. The agents update their internal states recursively based on these internal loops and the latent vectors received from their peers.
The results of the RecursiveMAS experiments demonstrate the raw efficiency of moving past the token interface: the system delivered an 8.3% accuracy boost on complex orchestration tasks, a 2.4x inference speedup, and a 75.6% reduction in total token usage.
However, a realistic view of these latent and recursive methods requires acknowledging that they are still early-stage. They excel primarily at highly structured, deterministic reasoning tasks, such as coding and math. For open-ended natural language generation, nuanced creative writing, or broad contextual knowledge retrieval, pure latent models are not a complete solution. They will almost certainly need to operate as specialized execution engines hybridized within broader language systems.
The black box dilemma
While latent reasoning elegantly solves the performance and cost crises of tokenmaxxing, it introduces a fatal flaw for production-grade applications: zero visibility.


Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.