






")
 with LlamaIndex and ChatGPT")





?")






Pre-trained large language models (LLM) like Llama 2 are versatile tools, capable of performing a wide array of tasks straight out of the box. However, you can improve their performance on bespoke tasks by fine-tuning them with custom data. The idea of having multiple, fine-tuned versions of an LLM for different use cases is appealing. But it comes with a significant memory and compute overhead required to run them.
A solution is low-rank adaptation (LoRA), a fine-tuning technique that significantly reduces the memory footprint of your fine-tuned models. To further streamline this process, developers can utilize LoRAX, a framework that automates the management and operation of multiple LoRA models, minimizing technical overhead and maximizing efficiency.
How LoRA works
The conventional method of fine-tuning a deep neural network for a specific task involves training the model on new examples. Depending on the similarity between the original and fine-tuning training data, some or all of the model’s layers are modified during this process, while the rest remain frozen.
However, a significant drawback of this classic fine-tuning approach is that the model undergoes irreversible modifications, possibly reducing its performance on the original task.
In this regard, LoRA offers two key benefits. First, instead of modifying the entire parameter space of the original model, LoRA identifies and adjusts only a subset of the original model’s parameters that are crucial for learning the new task. This targeted approach ensures efficient and low-cost fine-tuning.
Second, LoRA functions as an adapter. It is trained as an independent model and plugged into the original model during inference. This feature allows developers to train multiple LoRA models for different downstream tasks and choose the one to attach to the main LLM at runtime.

For instance, you could have a LoRA model fine-tuned for customer support, another for writing assistance, and yet another for semantic search. These can all be used on the same base model, depending on which application feature a user activates.
Once trained, each LoRA model adds minimal overhead to the original model’s operation. This means you can leverage the power of multiple fine-tuned models at virtually no additional cost.
Using LoRAX to serve LoRA models at scale
While low-rank adaptation offers compelling features, managing an array of LoRA models can introduce technical complexities and costs. This is where LoRAX, a framework developed by Predibase, comes into the picture. Built on top of Ludwig, a low-code framework by Uber AI designed for creating deep learning model pipelines, LoRAX simplifies the process of managing multiple LoRA models.
LoRAX can load a base LLM along with one or more LoRA adapters. Depending on the user’s request, LoRAX seamlessly combines the base LLM with the appropriate LoRA adapter to generate the response.
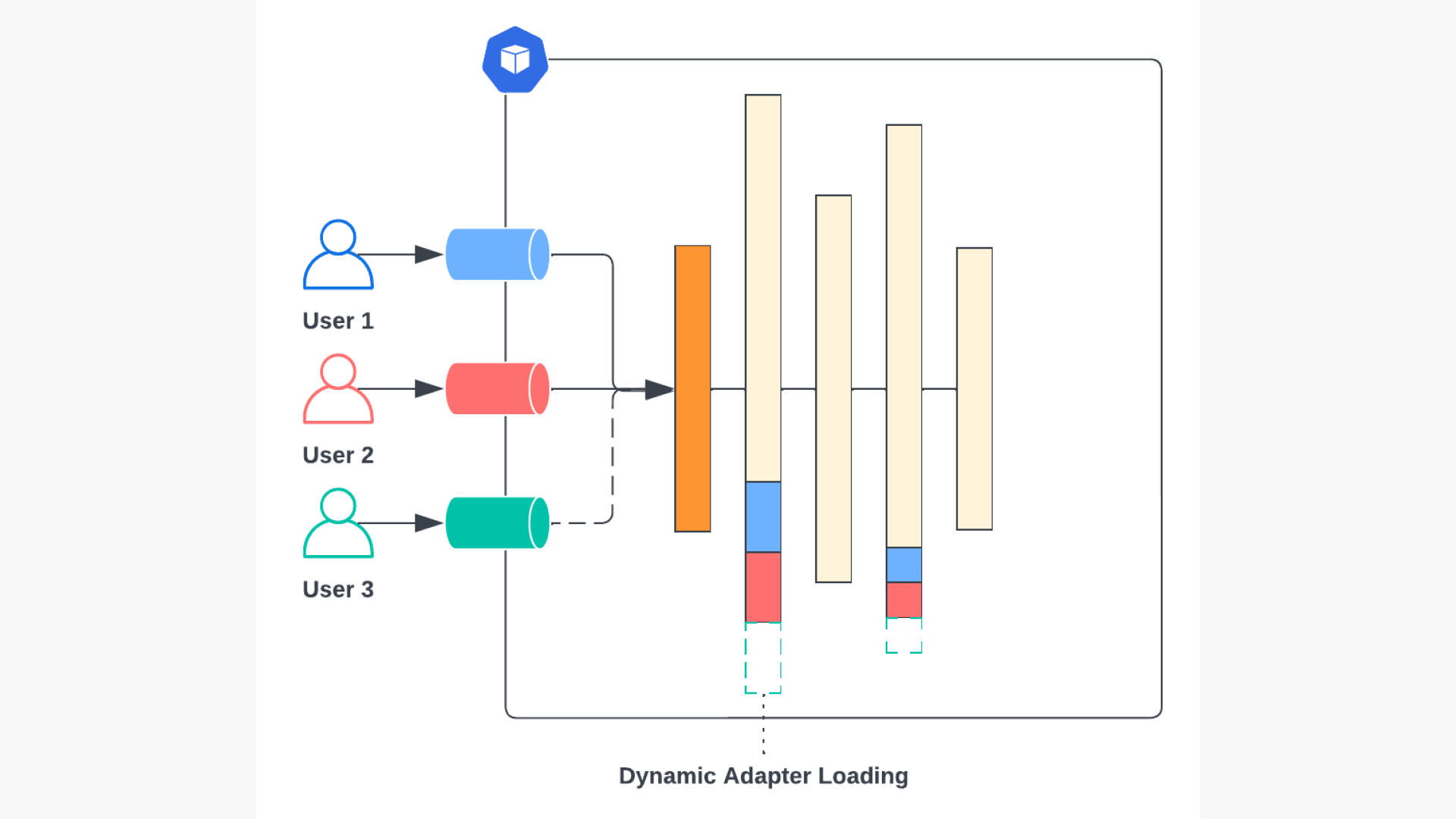
Furthermore, LoRAX dynamically manages your LoRA stack, ensuring smooth operation even if the number of adapters exceeds your server’s GPU memory capacity. It achieves this through a multi-layered caching system that can swap different LoRA adapters between GPU, RAM, and disk memory, ensuring all requests are served without causing significant latency for users.
Predibase offers a cloud service for running your models online, as well as a Python SDK that allows you to create LoRA adapters with just a few lines of code, enabling easy integration into your applications. The platform supports several popular open-source models, including Llama 2, Mistral, and Falcon, providing a versatile solution for developers looking to leverage the power of fine-tuned LLMs.