



















This article is part of our coverage of the latest in AI research.
Apple has been late to the game on large language models (LLM) but is making interesting moves lately. The company’s researchers recently unveiled a method that significantly reduces the memory requirement for running LLMs. This breakthrough hinges on novel storage and memory management techniques that dynamically transfer the model’s weights between flash memory and DRAM while keeping latency impressively low.
Their approach makes it possible to run these large models with decent throughput, even when it is partially loaded on the device’s RAM. This could be significant for Apple, which does not have a hyperscaler business and would benefit immensely from on-device AI. The technique could enable future iPhones and Macs to harness the power of LLMs without overwhelming the system’s memory.
Memory requirements of LLMs
LLMs are notorious for their large memory requirements. For example, a 7-billion-parameter model at half-precision requires over 14 gigabytes of RAM. Such requirements exceed the capacity of most edge devices.
One method to address this is quantization, compressing models by converting parameters into 8-bit or 4-bit integers. However, quantization often requires modifications to the model or even full retraining. In some cases, quantized LLMs remain too large for on-device inference.
Apple’s research tries to tackle the problem from a different angle: How can we deploy a model on hardware that lacks the necessary memory?
Loading LLMs from flash memory
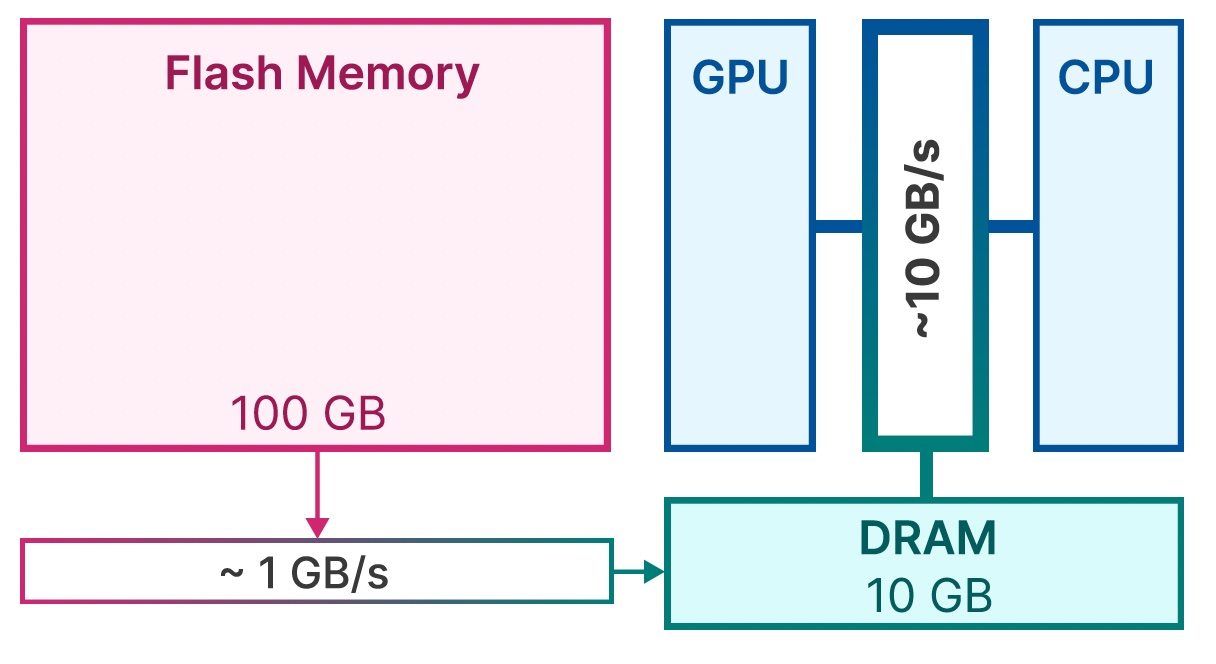
One strategy to solve the memory bottleneck is to store the LLM on flash memory and load it into RAM incrementally for inference tasks. While flash memory is more abundant on devices than DRAM, it is slower by at least an order of magnitude.
A naive inference approach using flash memory could require reloading the entire model for each forward pass. This process is slow—often taking seconds even for compressed models—and energy-consuming.
In their paper, Apple’s researchers introduce a suite of optimization techniques designed to streamline the process of loading the model from flash memory to DRAM. These methods aim to preserve the speed of inference while keeping memory consumption low.
Leveraging model sparsity
Language models hinge on transformer blocks, which consist of two critical elements: the attention mechanism and the feedforward (FFN) network. Studies indicate that FFNs in LLMs have high sparsity—many of their values become zero or near-zero post-activation, rendering them irrelevant for inference. Astonishingly, sparsity in some FFN layers can exceed 95%.
Apple’s researchers suggest harnessing this sparsity to optimize model inference. By finding and loading only the non-sparse elements during inference, memory costs could be dramatically reduced. Their strategy involves fully loading the comparatively smaller attention layers, while selectively loading only the non-sparse segments of the FFN into DRAM.
“Our approach involves the iterative transfer of only the essential, non-sparse data from flash memory to DRAM for processing during inference,” the researchers write.

To achieve this, they employ a “low-rank predictor” network that determines which parts of the FFN will be non-sparse and reduce the volume of data that needs to be loaded. The predictor’s identified active neurons are then transferred into memory.
Sliding windows
Apple’s researchers have also devised a “Sliding Window Technique” to manage the loading and unloading of neurons during model inference. This method keeps only the neuron data for a recent subset of input tokens in memory, releasing the space of older tokens as new ones come in. Their research reveals that with each new token, only a minimal number of neurons need to be swapped, streamlining the data transfer from flash memory to RAM.
“This strategy allows for efficient memory utilization, as it frees up memory resources previously allocated to neuron data from older tokens that are no longer within the sliding window,” the researchers write.

The sliding window’s size can be configured according to the memory limitations of the device running the model.
Optimizing storage and loading
The Apple team’s research shows that neuron activations across different layers follow patterns that can be leveraged for storage optimization. They suggest reorganizing model weight storage based on which neurons would need to be loaded together. This arrangement allows the system to fetch a single contiguous data block in one read operation.
The researchers also examined the benefits of storing coactivated neurons together. This method would permit the system to pull from one large segment of flash memory. Although the outcomes from this particular experiment fell short of expectations, the insights hold promise for guiding future research endeavors.

Further, the team has engineered a novel data structure and dynamic memory allocation algorithm. This innovation reduces the frequency of memory allocations and allows the model to access approximately 25% of the FFN neurons without significant performance degradation.
Faster LLMs on low-memory devices
Apple’s research team put their techniques to the test on two different models, OPT 6.7B and a sparsified variant of Falcon 7B, across two hardware setups. The first platform was an Apple M1 Max with a 1TB SSD serving as flash memory. The second set of tests was on a Linux machine with a 24 GB NVIDIA GeForce RTX 4090 graphics card. In their experiments, they only loaded around 50% of the model’s weights into memory at any given time.
On the M1 Max, a naive loading of the model from flash memory to RAM for each inference would result in a latency of 2.1 seconds per token. However, by implementing their novel techniques—sparsity prediction, windowing, and intelligent storage—the team slashed this latency to approximately 200 milliseconds. The improvements on GPU-equipped systems were even more pronounced.
“We have demonstrated the ability to run LLMs up to twice the size of available DRAM, achieving an acceleration in inference speed by 4-5x compared to traditional loading methods in CPU, and 20-25x in GPU,” the researchers write.
The researchers believed that their findings could have important implications for future research and highlight the “importance of considering hardware characteristics in the development of inference-optimized algorithms.”
“We believe as LLMs continue to grow in size and complexity, approaches like this work will be essential for harnessing their full potential in a wide range of devices and applications,” they write.
I really liked this paper because it brings together both insights from machine learning models as well as deep knowledge of hardware and memory design. This can be a prelude to the kind of practical and applicable research we can expect from Apple in the future. We can expect these innovations to be integrated into future Apple products and bring advanced AI capabilities to consumer devices.
Please consider supporting TechTalks through a one-time, monthly, or yearly donation
Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.
DonateDonate monthlyDonate yearly