






")
 with LlamaIndex and ChatGPT")





?")






This article is part of our coverage of the latest in AI research.
When using large language models (LLM) for domain-specific applications, you must usually use retrieval-augmented generation (RAG) or fine-tune the model for your purpose. However, both RAG and fine-tuning have limitations that prevent LLMs from achieving optimal performance.
In a new paper, researchers at the University of California, Berkeley, introduce Retrieval Augmented Fine Tuning (RAFT), a new technique that optimizes LLMs for RAG on domain-specific knowledge. RAFT uses simple but effective instructions and prompting techniques to fine-tune a language model in a way that helps it both gain knowledge on the specialized domain and be able to better extract information from in-context documents.
RAFT can be very useful for enterprises that customize LLMs for applications that work with their proprietary data.
The limitations of fine-tuning and RAG
“The idea of RAFT was driven by a limitation in LLMs—their inability to respond to queries outside their training domain, such as enterprise private documents, time-sensitive news, or recently updated software packages. This limitation has been a significant barrier to employing LLMs in various real-world scenarios,” Tianjun Zhang and Shishir Patil, PhD students at UC Berkeley and co-authors of the paper, told TechTalks.
Foundational LLMs are trained on a vast corpus of knowledge that covers a wide range of topics. However, in domain-specific settings and applications, general knowledge is less critical. Instead, the model must have maximum accuracy on a narrow range of topics and documents such as recent news or private enterprise documents.
RAG pipelines use a retrieval mechanism to provide the LLM with documents and data that are relevant to the prompt. However, RAG does not train the LLM on the basic knowledge required for that application, which can cause the model to miss important information in the retrieved documents.
“Our investigations revealed that many open-source models struggle with [RAG], particularly with the following issues: a) dealing with in-accurate retrievers, b) answer style mismatch and c) extracting incorrect information from the retrieved context,” Zhang and Patil said.
On the other hand, fine-tuning an LLM on domain-specific data can improve its knowledge. However, it still limits the model’s knowledge to the data included in the training dataset. Meanwhile, combining fine-tuned models and RAG also has limitations. For example, it might miss relevant information in the retrieved documents or fail to account for imperfections in the retrieval mechanism.

In their paper, the researchers compare RAG methods to “an open-book exam without studying” and fine-tuning to a “closed-book exam” where the model has memorized information or answers questions without referencing the documents. In contrast, a RAFT-trained model is like a student who has studied the topic and is sitting at an open-book exam. The student will have ample knowledge of the topic and will also know how to get more precise information from available documents.
Retrieval Augmented Fine Tuning (RAFT)
Retrieval Augmented Fine Tuning (RAFT) combines supervised fine-tuning (SFT) with RAG to incorporate domain knowledge in LLMs while also improving their abilities to use in-context documents.
“RAFT aims to not only enable models to learn domain specific knowledge through fine-tuning, but also to ensure robustness against inaccurate retrievals,” according to the paper. “Our approach is analogous to studying for an open-book exam by recognizing relevant, and irrelevant retrieved documents.”
In RAFT, each training example contains a question, a set of documents, and a corresponding Chain-of-thought (CoT) answer generated from one of the documents. There are a few things that make the RAFT dataset interesting:
First, training examples contain “oracle” and “distractor” documents. Oracle documents have information that is relevant to the prompt, while distractor documents are not related to the question. By being trained on both oracles and distractors, the fine-tuned model will be able to perform better if the retrieval module returns irrelevant documents.
Second, in some of the training examples, the oracle document is removed but the correct answer is retained. This forces the model to learn domain knowledge independently from the retrieved documents. “By removing the oracle documents in some instances, we are compelling the model to memorize answers instead of deriving them from the context,” the researchers write.
Third, adding the CoT segment enhances the model’s ability to cite sources from the context and explain its answers. The RAFT code has been designed to use GPT-4 by default to generate CoT reasoning steps for the training examples.

“RAFT addresses [the problems with classic RAG] by training the model to not only understand the context documents but also to disregard irrelevant content,” Zhang and Patil said. “Our training approach involves incorporating both relevant (gold) documents and distractor documents in the prompt, and if necessary, crafting answers in a specific format.”
RAFT in action
The researchers fine-tuned the 7-billion-parameter version of Llama-2 with RAFT on diverse domains including Wikipedia, Coding/API documents, and question-answering on medical documents. They then compared it with baseline versions, including LlaMA2-7B-chat, LlaMA2-7B-chat model with RAG (Llama2 + RAG), domain-specific fine-tuning with zero-shot prompting (DSF), and domain-specific fine-tuning with RAG (DSF + RAG).
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
Their findings show that RAFT consistently and significantly outperforms the baseline models on all benchmarks. Interestingly, the RAFT-trained Llama-2 7B model even outperformed GPT-3.5 with RAG on most benchmarks.
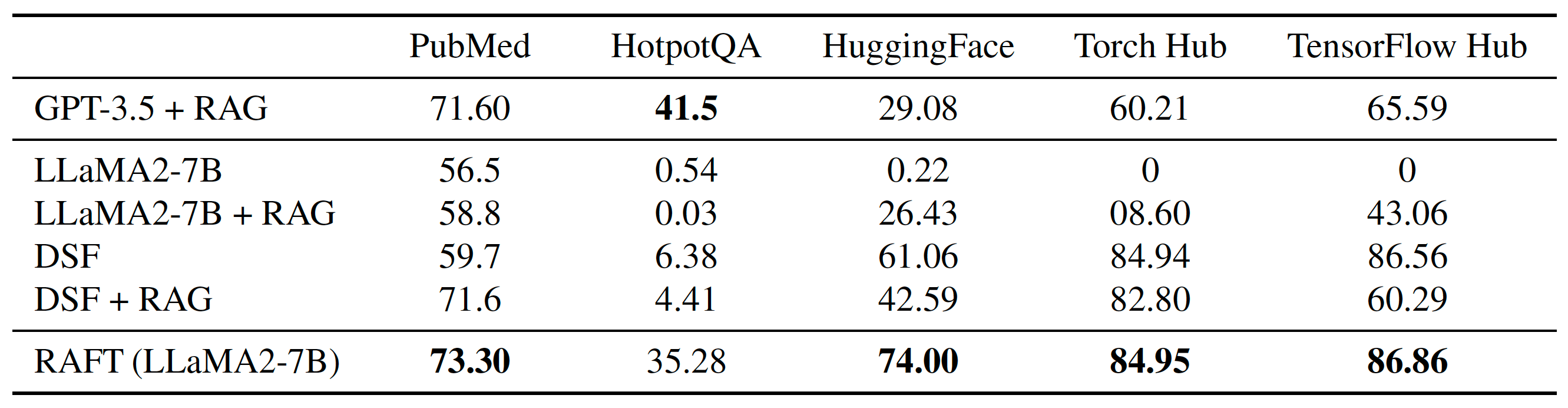
One interesting observation from the findings is that on some benchmarks, the performance of DSF models decreased when used with RAG. “This might indicate that the model lacks training in context processing and extracting useful information from it,” the researchers write in their paper. In contrast, RAFT trains the model not only to match the required answer style but also to improve its document processing capabilities.
“If you are doing RAG—you should be doing RAFT,” Zhang and Patil said. “RAFT is versatile, enabling functionalities such as document-oriented QA chatbots or API calls for LLMs.”
The researchers are currently developing an open-source function-calling model called Gorilla-Openfunctions-v2 that uses the RAFT algorithm.
The researchers released the source for RAFT on GitHub along with instructions on how to use it. In the future, they will continue working on methods to improve LLM training and fine-tuning for RAG-related tasks, particularly enhancing the handling of long-context documents.