



















This article is part of our coverage of the latest in AI research.
A new study from Google DeepMind reveals a fundamental, mathematical limit to what single-vector embeddings can achieve in retrieval tasks, regardless of how large the model is or how much data it’s trained on. The paper provides a theoretical proof for these limitations and demonstrates them with a deceptively simple benchmark that stumps even state-of-the-art models.
These findings have significant implications for developers building advanced retrieval-augmented generation (RAG) systems, suggesting that for complex queries, the popular single-vector approach may not be enough.
Pushing vectors beyond their breaking point
Vector embeddings are the backbone of modern AI search. They are created by encoder models that map data like text or images into a dense list of numbers, or a vector. In the high-dimensional space of embeddings, proximity equals semantic similarity (technically, if you take the dot product of the embeddings of two pieces of text, higher numbers indicate higher semantic similarity). In RAG applications, a vector store is created that contains the embeddings of knowledge documents. During inference, these embeddings are used to match queries with documents that might contain relevant information.

Recently, the demands on these models have exploded. Developers are now tasking them with “instruction-following retrieval,” where they must understand complex queries with nuanced relevance criteria. For example, a system might be asked to find all Leetcode problems that share a specific sub-task, such as those that use dynamic programming. This requires the model to understand the abstract relationship between documents, not just their surface-level content.
This shift has pushed embedding models beyond simple keyword matching toward representing the full semantic meaning of language. They must now be able to group previously unrelated documents into a single set of relevant results for a given query.
The authors of the new work wanted to understand this challenge at a foundational level. As they state, “Rather than proposing empirical benchmarks to gauge what embedding models can achieve, we seek to understand at a more fundamental level what the limitations are.”
The paper connects a model’s retrieval capacity to a concept from communication complexity theory called “sign-rank.” In simple terms, for any given embedding dimension, there is a hard cap on the number and complexity of query-document relationships a model can represent. As the number of documents and the variety of possible query combinations grow, a model with a fixed dimension will inevitably fail to distinguish between all of them.
Finding the limit in a perfect world
To isolate this theoretical limit, the researchers designed a best-case experiment using what they call “free embeddings.” Instead of being constrained by natural language, the query and document vectors were directly optimized with gradient descent to solve a retrieval task. This setup reveals the highest possible performance any embedding model could achieve for a given dimension.
The experiment aimed to find the “critical-n point”: for a given embedding dimension d, what is the maximum number of documents n for which the model can successfully retrieve every possible top-2 combination? The results showed a clear and predictable breaking point. The relationship between the embedding dimension and the number of documents it could handle followed a third-degree polynomial curve, demonstrating that while a larger dimension helps, it does not solve the underlying combinatorial problem.
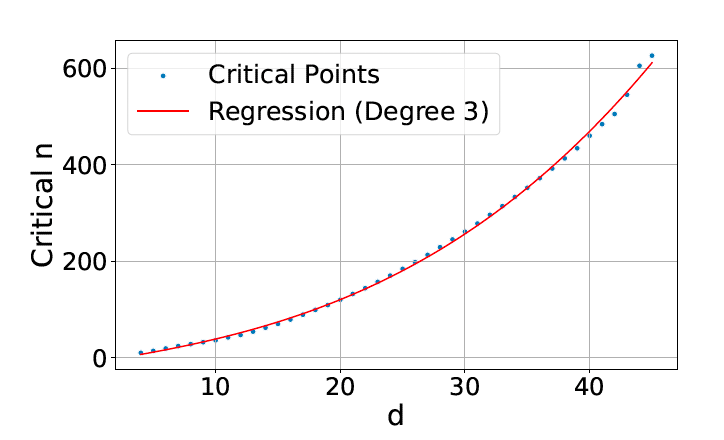
Extrapolating this curve reveals a stark reality for real-world applications. The paper notes that “for web-scale search, even the largest embedding dimensions with ideal test-set optimization are not enough to model all combinations.” If an idealized model with perfectly optimized vectors can’t handle the task, a real-world model constrained by the complexities of language has no chance.
The benchmark that breaks state-of-the-art models
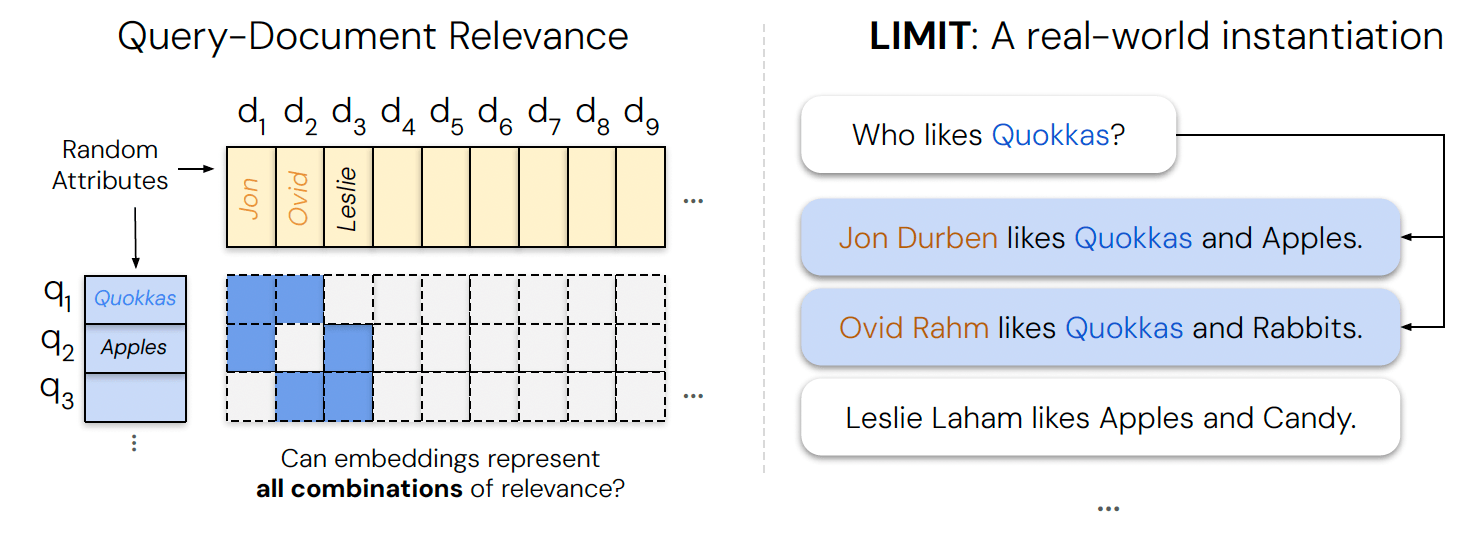
The researchers argue that existing benchmarks don’t expose this weakness because they test only an “infinitesimally small part” of the possible query-document combinations. For example, the popular QUEST dataset has 325,000 documents, which allows for more than 7.1e+91 (71 followed by 90 zeros) unique sets of 20 documents. However, its evaluation set contains just 3,357 queries, barely scratching the surface of what a user could ask.
To address this gap, they created the LIMIT dataset. It uses a simple, natural-language premise: documents are profiles of people and the things they like (e.g., “Jon Durben likes Quokkas and Apples”), and queries ask who likes a specific item (e.g., “Who likes Quokkas?”). The dataset is synthetically generated to include queries for every possible pair of documents from a core set, forcing models to confront the combinatorial explosion of relationships.
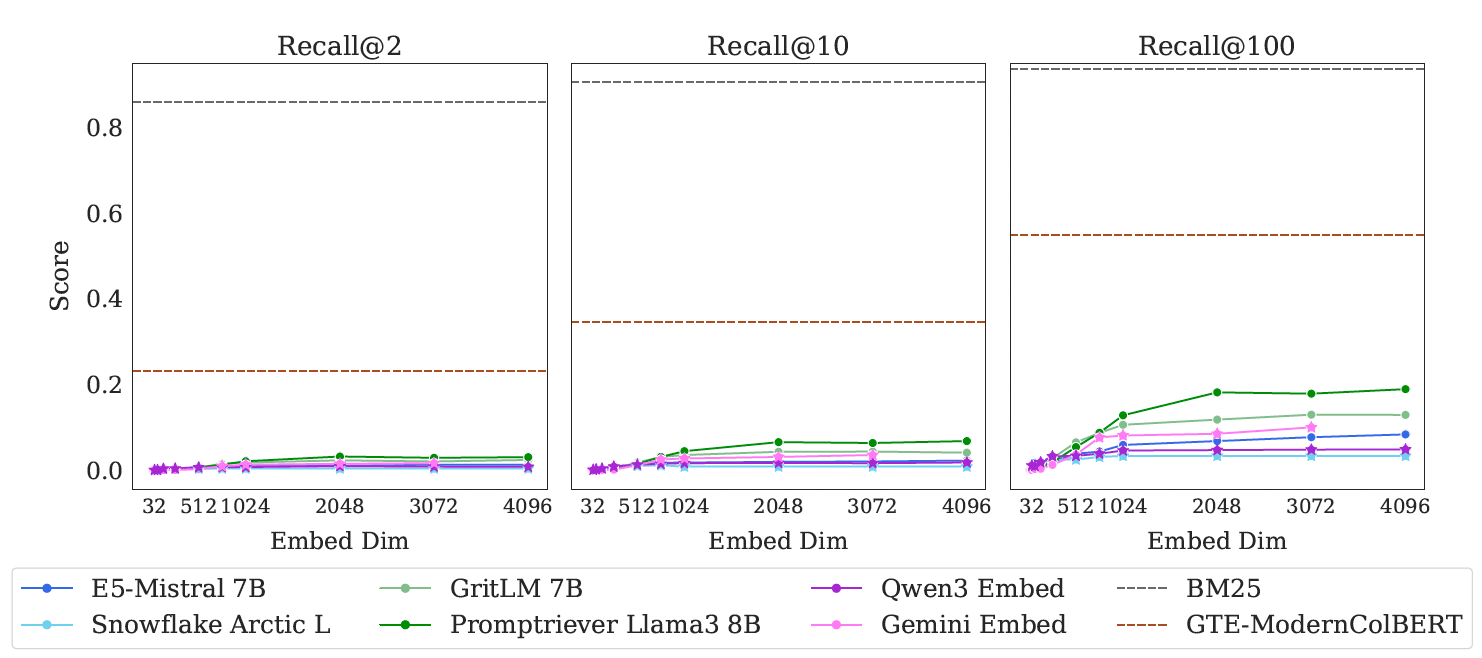
The results are surprising. Top-tier models like Gemini Embeddings and GritLM “severely struggle,” with the best models failing to reach even 20% recall@100 on the full task. In contrast, the decades-old lexical method BM25, which can be thought of as a very high-dimensional sparse vector model, performs exceptionally well. Further experiments showed this is not a simple “domain-shift problem” (i.e., the dataset the model was trained on is very different from the dataset it is being tested on). Fine-tuning an embedding model on a training set of similar examples provided almost no performance gain, proving the difficulty is intrinsic to the single-vector architecture.

Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.