



















Anthropic has launched Claude Sonnet 4.5, positioning “the best coding model in the world” as it is in lockstep with other contenders like OpenAI in the breakneck competition to dominate the AI coding market.
Claude Sonnet 4.5 builds on the success of its predecessor, providing incremental improvements and better token efficiency, with an impressive ability to accomplish coding tasks that require hours of work.
Claude Sonnet 4.5 architecture and data
Unfortunately, like other leading AI labs, Anthropic is very secretive about the architecture of their models and the data used to train them. From the blog post, model card, and documentation, what we know is that Claude Sonnet 4.5 is a “hybrid reasoning model,” which means it uses a single model for fast responses and an extended thinking mode that uses chain-of-thought (CoT) reasoning to solve more difficult problems. To their credit, Anthropic currently shows the full CoT sequence as opposed to OpenAI and Google, which show a summarized version of the model’s reasoning chain.
Sonnet 4.5 supports a 200K token context window and a maximum output capacity of 64K tokens, which puts it at the lower end of the top-tier AI models such as Grok-4 Fast (2 million token context window), Gemini 2.5 Pro (1 million tokens), and GPT-5 (400K tokens) . It was trained on a proprietary mix of publicly available internet data from up to July 2025, along with non-public and user-provided data.
Anthropic also positions Sonnet 4.5 as its “most aligned frontier model yet.” The company reports significant reductions in concerning behaviors like deception and power-seeking and has made considerable progress in defending against prompt injection attacks. The model is released under Anthropic’s AI Safety Level 3 protections, which include filters to detect potentially dangerous inputs related to chemical, biological, radiological, and nuclear weapons.
Performance on key benchmarks
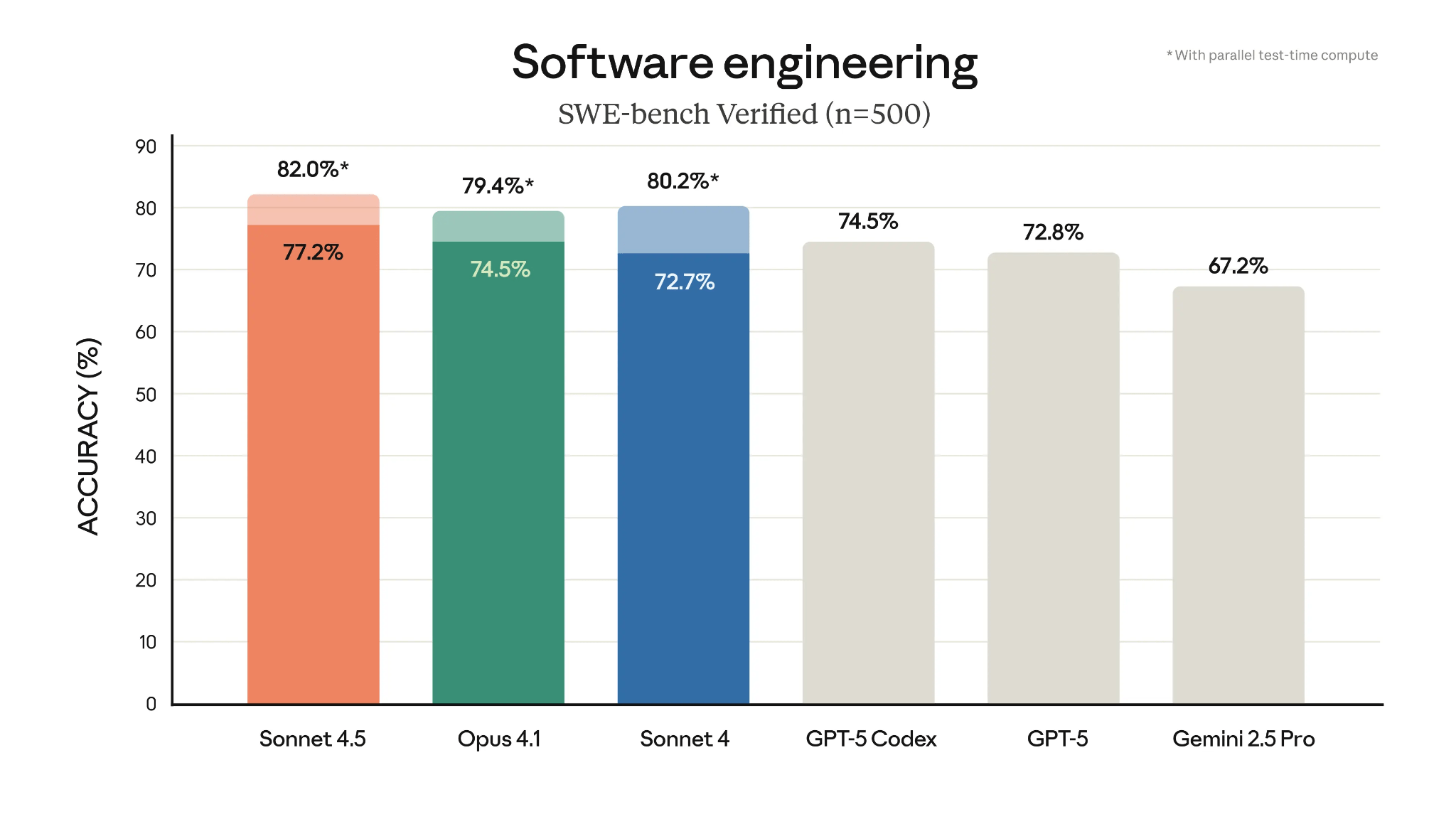
Anthropic claims state-of-the-art performance for Sonnet 4.5 on the SWE-bench Verified evaluation, scoring 77.2% on the test of real-world software engineering abilities. The company also reports that the model leads on OSWorld, a test for computer tasks, with a score of 61.4%. This is a significant increase from the 42.2% achieved by its predecessor, Claude Sonnet 4, just four months prior.
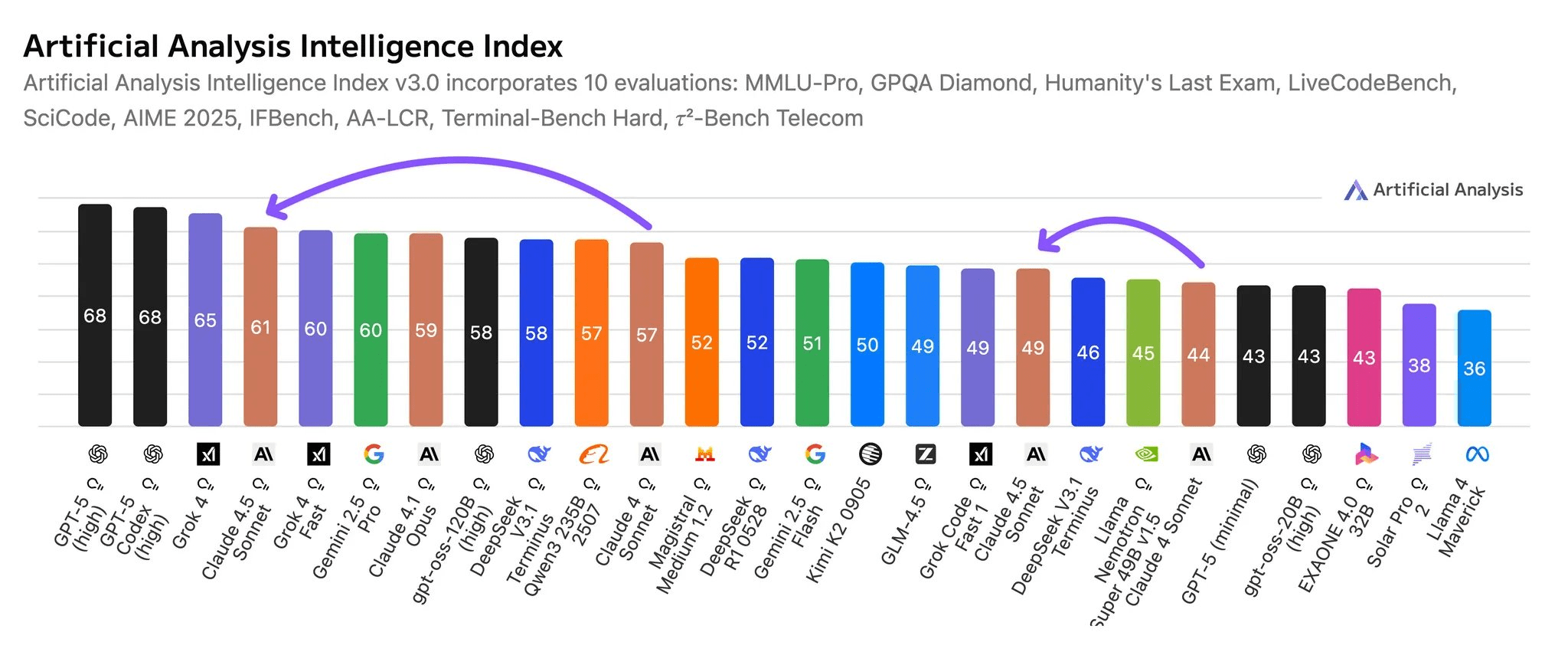
Independent analysis provides a broader perspective. On the Artificial Analysis Intelligence Index, Sonnet 4.5 scores 61 in its reasoning mode, placing it as the fourth most intelligent model overall. This score is ahead of Google’s Gemini 2.5 Pro but behind models like GPT-5 and Grok 4. While the model doesn’t achieve the highest score in any single evaluation within the index, its most significant improvements are in areas like tool use, making it useful for agentic applications.
Importantly, Claude Sonnet 4.5 reportedly supports coding tasks that require up to 30 hours development time, which means it can accomplish huge chunks of tasks autonomously. There are two key caveats to consider. First, the model’s context window cannot possibly support such long horizons, so it is using some behind-the-scenes tricks (distributing work across multiple instances, summarizing the context regularly, etc.). Second, as a long-time programmer, I would prefer a coding assistant that helps me accomplish coding tasks in small bits, where I can review and verify the code. I don’t want to get a huge, million-line body of code that I will never review and can only pray will work properly.
Pricing and availability
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
Anthropic is holding its pricing steady for the new model, charging the same $3 per million input tokens and $15 per million output tokens as Claude Sonnet 4. This decision comes as OpenAI pursues an aggressive pricing strategy with GPT-5, creating pressure on Anthropic’s premium market position.
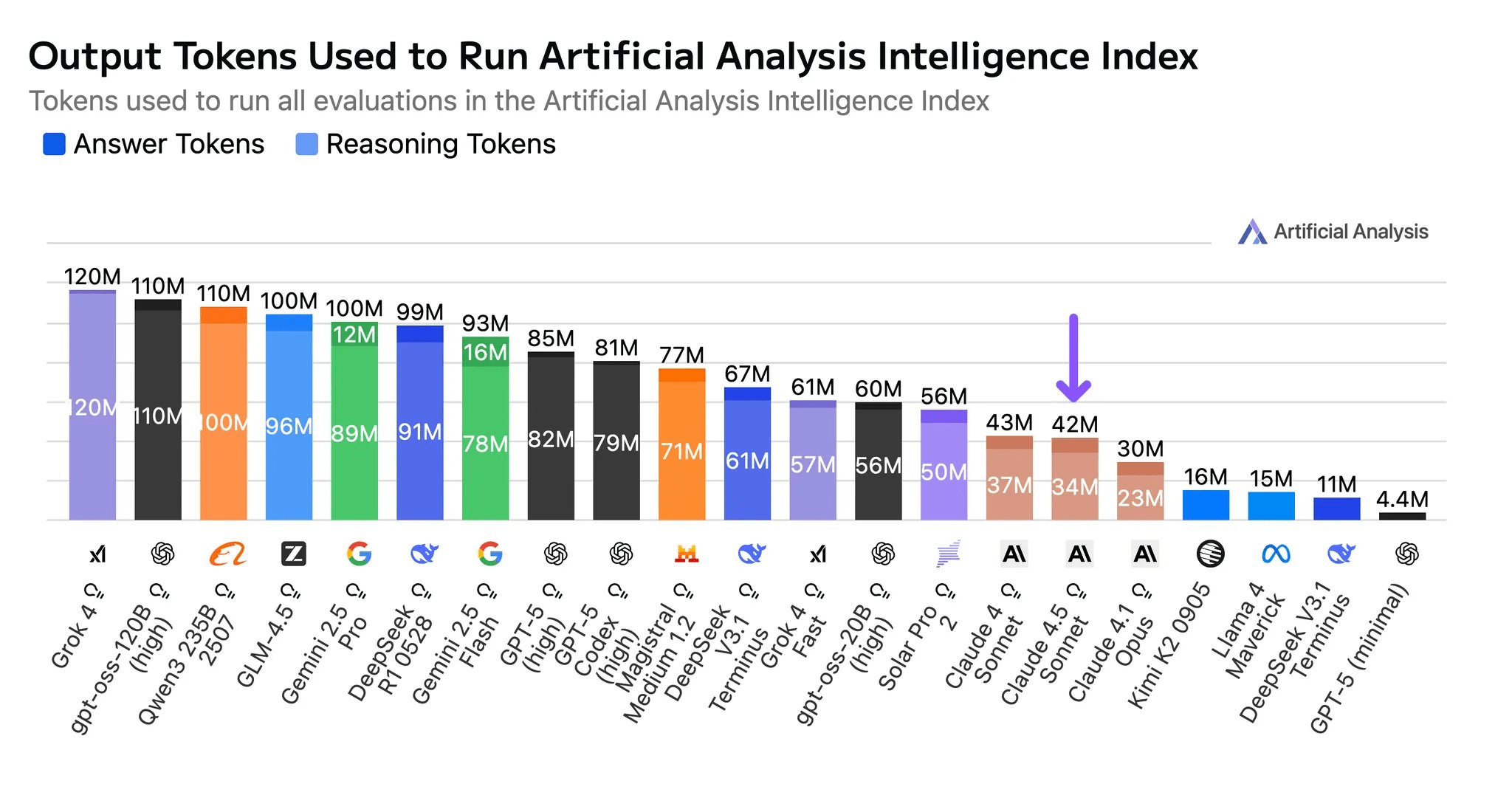
Anthropic’s answer to this pressure is superior token efficiency. Sonnet 4.5 achieves its higher intelligence scores without increasing its output token usage, a key difference from other model upgrades. This makes Claude models more efficient than other leading reasoning models. For enterprises, this efficiency means that even if the upfront token price is higher, the total cost for completing complex tasks can be lower, offering a better trade-off between intelligence and operational cost.
Winning the developer market
With Sonnet 4.5, Anthropic is solidifying its focus on the enterprise coding market, where it already holds a 42% share, more than double that of OpenAI. This strategy targets a profitable and established use case and one of the most lucrative markets for LLMs (improving the productivity of a software developer by even 1% can be worth thousands of dollars per year, which more than justifies the price of paying for a Claude subscription).
However, the battle for the developer market is not won. Anthropic relies on development tools like Cursor and GitHub Copilot for a large part of its revenue. And those are tools where models from OpenAI and other providers are readily available and a dropdown list away. Following the release of GPT-5, there was a general vibe in the developer community that OpenAI has taken the lead in AI coding. Anthropic might have repositioned itself as the leader again with Claude Sonnet 4.5. But with Google and xAI waiting in the wings, we might witness another reshuffling of the leaderboard very soon.