



















Chinese lab Moonshot AI has released a new leading open-weights model from, Kimi K2 Thinking, which achieves an intelligence score that competes with the leading closed models from U.S. companies. The model is built as a “thinking agent” specifically trained to reason step-by-step while using tools, a design that puts it in direct competition with the capabilities of top proprietary systems. This release can mark a significant moment where open-source models are not just catching up to the closed-source frontier, but directly challenging its performance on complex, agentic tasks.
Architecture and training
Kimi K2 Thinking shares several of the architectural traits of DeepSeek-R1. It is based on a Mixture-of-Experts (MoE) architecture with a massive 1 trillion total parameters, of which 32 billion are active for any given token.
Its MoE architecture is similar to R1, where it uses multiple fine-grained experts per token and a single shared expert that is applied to all tokens and accounts for general knowledge and skills that apply to all tasks. K2 Thinking also uses the Multi-Head Latent Attention (MLA), a mechanism that compresses the attention values of the model to reduce the KV cache size.
Kimi K2 Thinking is among the largest models publicly detailed. It can process information over a 256K context window, enabling it to handle extensive documents and maintain coherence in long conversations. It is a reasoning-focused variant of the earlier Kimi K2 Instruct model, having undergone specific post-training to enhance its capabilities for agentic workflows involving long-horizon tool use.
A core feature of the model is its ability to perform what is known as “interleaved thinking,” where it generates reasoning steps between executing actions. This allows it to coherently execute up to 200–300 sequential tool calls without human intervention, a significant leap for an open-weights model. This is especially useful for multi-step reasoning and research tasks, where the model must gather new information, update its reasoning and explore different tools.
To make this power practical for deployment, Moonshot AI trained the model using Quantization-Aware Training (QAT), releasing it natively in INT4 precision. This technique roughly doubles generation speed and reduces memory requirements, making the large model more efficient to run, especially on older hardware that lacks support for newer precision formats.
Kimi K2 Thinking only supports text input and output, which puts it at a disadvantage against multimodal models such as GPT-5.
Performance closes the gap, but with a catch
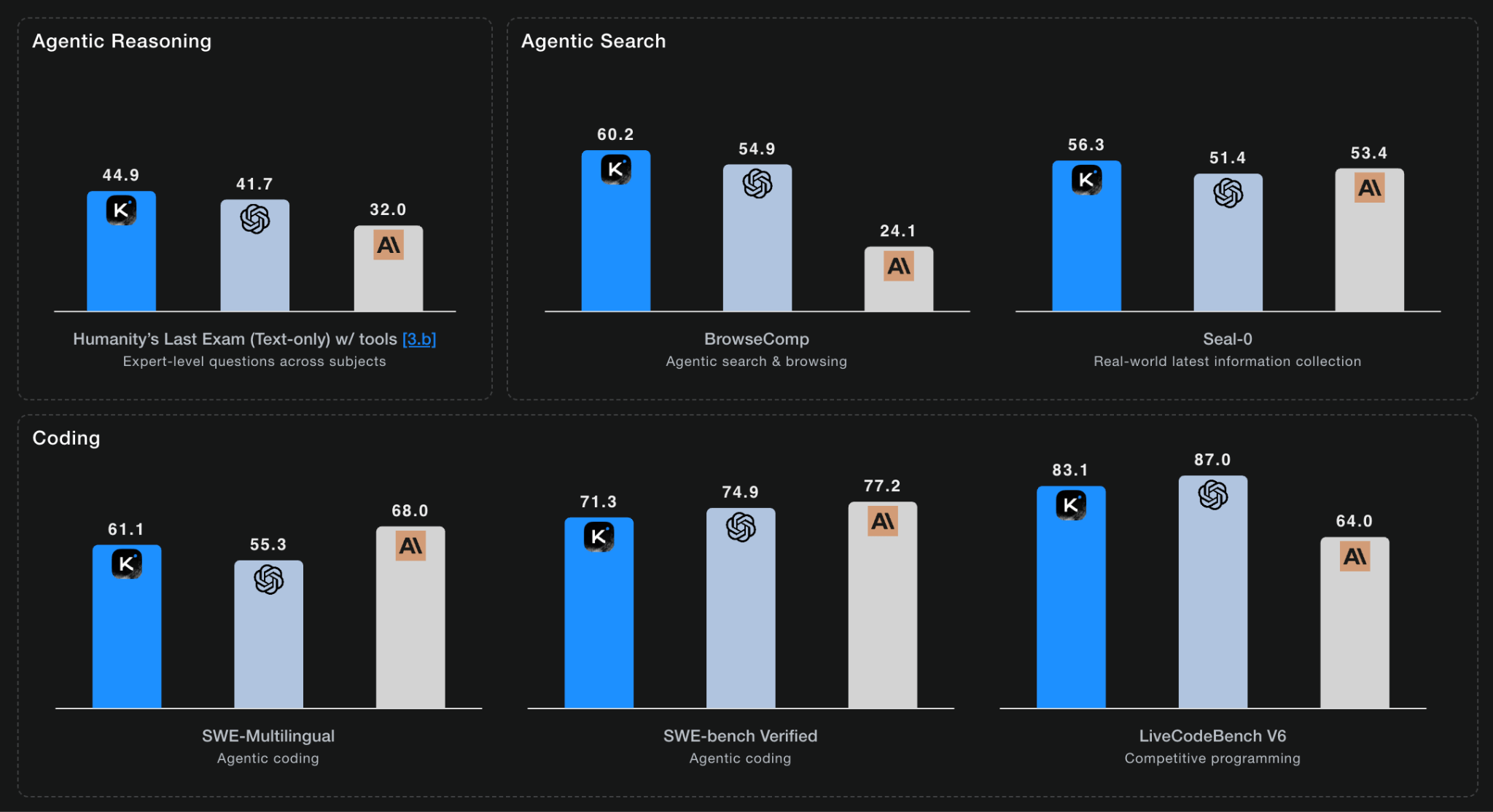
Moonshot AI’s own evaluations show Kimi K2 Thinking setting new records on benchmarks that require tool use, scoring 44.9% on Humanity’s Last Exam (HLE) with tools and 60.2% on BrowseComp. Independent analysis corroborates its strength. It achieved a score of 67 on the Artificial Analysis Intelligence Index, the highest yet for an open-weights model. Even without tools, it set a new open-weights record on HLE with a score of 22.3%, demonstrating powerful base knowledge and reasoning.
Some of the examples shared by Moonshot shows Kimi K2 Thinking generating complicated applications with a single prompt, such as a Word clone and a virus simulator. (It is worth noting that models are more likely to correctly generate applications that are identical or similar to their training data.)
However, this high performance comes with a significant trade-off: verbosity. The model produces very long outputs, using 140 million total tokens to complete the Artificial Analysis evaluation suite. This is roughly two-and-a-half times the tokens used by a competitor like DeepSeek V3.2. Such high verbosity directly impacts its practical application by increasing both the cost to run queries and the time it takes to receive a complete response, offsetting some of the benefits of its low per-token price.
The business case: a pricing puzzle and a permissive license
Kimi K2 Thinking is available for download on Hugging Face. Given that it has been quantized to 4 bits, you need about 500 GB of memory to run it. One user was able to deploy it on two Mac M3 Ultra processors with 512 GB of memory, getting around 15 tokens per second.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
Kimi K2 Thinking is also accessible on Moonshot’s own cloud service via an API service that is compatible with OpenAI and Anthropic interface, making it easy for developers to integrate.
Moonshot offers two pricing tiers that create a choice between cost and speed. The base endpoint is very inexpensive at $0.60 per million input tokens and $2.50 per million output tokens. But according to Artificial Analysis, the base endpoint is also very slow, generating around 8 output tokens per second.
A much faster “turbo” endpoint operates at about 50 tokens per second but comes at a considerably higher price at $1.15 per million input tokens and $8.00 per million output tokens. This structure, combined with the model’s high verbosity, presents a dilemma for developers: the cheap tier may be too slow for real-time applications, while the turbo tier’s total cost can quickly escalate.
For enterprise adoption, the model’s licensing is a clear advantage. It is released under a modified MIT license, which is permissive for almost all commercial uses. The only restriction applies to very large-scale services: if a product using the model has more than 100 million monthly active users or over $20 million in monthly revenue, it must prominently display “Kimi K2” in its user interface. This approach removes a significant barrier for businesses looking to build on top of a powerful foundation model.
The pressure mounts on proprietary AI
The release of Kimi K2 Thinking solidifies the position of Chinese labs like Moonshot AI, DeepSeek, and Qwen as creators of frontier AI models, shifting a growing share of industry mindshare. According to a CNBC report, unverified figures show that Kimi K2 was trained on a $4.6 million budget (though that might not be the entire picture, as was shown with DeepSeek-R1).
It shows that near-state-of-the-art performance is no longer exclusive to a handful of heavily funded Western labs, intensifying the pressure on proprietary models and suggesting that raw AI intelligence could become a commodity. For the established leaders, the path forward requires evolving beyond benchmark scores. Their competitive advantage may now depend less on raw performance and more on the reliability, user experience, and unique product integrations they can offer to retain their market position in an increasingly crowded field.