



















In some ways, AI research is like fashion: What’s old is new again. The AI industry continuously revisits and recycles old ideas as it archives new breakthroughs and hits new obstacles. In the past couple of years, we’ve seen it with recurrent networks (which are now seeing a resurgence in hybrid models such as Mamba and state space models) as well as reinforcement learning (with models such as o1 and DeepSeek-R1). (If you go back, you can see the same cycle with other fundamental ideas such as deep neural networks, which were dismissed for decades after a brief surge in interest and funding.)
But reinforcement learning, which is at the heart of the new generation of reasoning models, is also seeing a resurgence of older concepts as we hit the limits of the current paradigms, particularly reinforcement learning with verifiable rewards (RLVR). It turns out that while highly effective, outcome-based rewards can only take you so far. Advanced applications and problem-solving require more than just feedback on the final answer. And the research community is exploring new directions, some of which are reminiscent of the older ideas.
Why reinforcement learning works in LLMs
Before the rise of reasoning models, the LLM training pipeline was mostly reliant on self-supervised pretraining and supervised post-training (e.g., instruction-following and reinforcement learning from human feedback). In post-training, the model usually uses human-labeled datasets to fine-tune its behavior for specific tasks (e.g., coding) and preferences (e.g., avoiding harmful output).
The problem with previous post-training methods was that they relied heavily on supervised fine-tuning (SFT), which requires human-labeled examples, creating a bottleneck for scaling the process.
DeepSeek-R1 proved that for problems where the answer is well-defined, you can formulate the training process as a reinforcement learning problem. In this formulation, the current state is the sequence of tokens the model has generated, actions are the possible set of tokens the model can generate, and the reward is determined by whether the model’s output achieves the desired state.
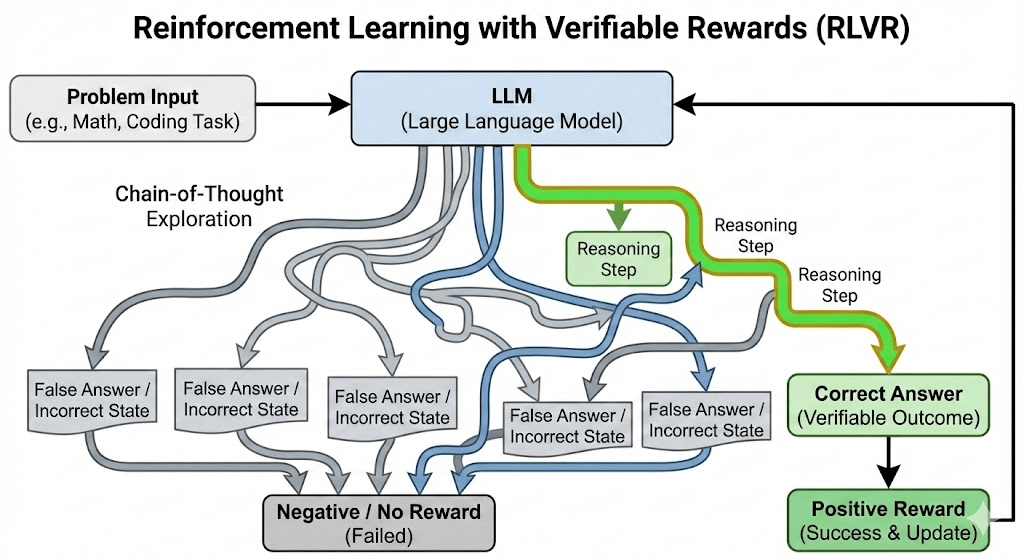
This approach, which has become known as reinforcement learning with verifiable rewards (RLVR), works well for problems where the answer is known in advance, such as math (i.e., the result should be a specific number) and coding (i.e., the resulting code should perform a certain task or produce a specific output or pass a set of tests). Basically, during training, the model is allowed to generate a longer chain-of-thought (CoT), the intermediate tokens between the input and the final answer, which allows it to reason about the problem and the way it was solving it (or at least create the impression that it is reasoning).
DeepSeek-R1 was only rewarded on the final outcome without any evaluation of the intermediate CoT. And it proved that the model could learn quite a lot through pure RLVR and without the need for any training on SFT datasets. Given all the knowledge it had absorbed during pretraining, it had the core knowledge required to solve the tasks. RL helped it focus its generation process on finding the solution faster.
This created a lot of excitement around the potential of RLVR and ushered in a new generation of reasoning models and test-time scaling techniques.
Where RLVR doesn’t work
However, the pure outcome-based RL paradigm is not without its limitations. One key problem it faces is “sparse rewards.” The model only receives feedback at the end of each rollout (i.e., the entire sequence it generates from the input to the final answer). This makes sense when the model finds the answer within a considerable number of attempts. But when the problem and the environment become increasingly complicated, it takes hundreds or even thousands of attempts before the LLM finds the correct answer and gets a positive reward to help it update its parameters. In other words, the model learns nothing from its failed attempts.
This makes the training process very inefficient and prohibitive. Moreover, it prevents the model from learning from partial answers, where it completes a few correct steps to solving the problem but gets derailed in later stages.
Another problem is inference inefficiency. Models that only receive outcome-based rewards tend to generate longer chain-of-thought sequences, going around in unnecessary circles in their reasoning, becoming slower and more expensive. If the model could get more granular signals on where it is going right or wrong, it could better adjust its CoT to make it more efficient.
This becomes especially problematic with agentic applications and complex tasks that require tool-use and multiple interactions with users and other external systems. In these cases, using the classic outcome-based RL paradigm leads to limited gains and often fails to create robust systems that can work in the messy and unpredictable environments of real-world applications.
What’s next for LLM reinforcement learning
There are several works of research and frameworks that are addressing the inefficiencies of outcome-based RL. In most cases, they use some form of process reward models (PRMs) that provide feedback not only on the outcome but also on the process the LLM goes through as it solves the problem. (Going back to what I said at the beginning of this article, PRMs were kind of out-of-vogue after DeepSeek-R1, but now they’re cool again.)
But this obviously poses a challenge: How do we evaluate the reasoning chain and model trajectory in a scalable way that minimizes the need for human-labeled data?

Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.