")




















AI lab Poetiq has officially topped the ARC-AGI-2 leaderboard with an approach that hints at a significant shift in how AI systems solve complex reasoning tasks. On November 20, 2025, the company announced preliminary results that have now been verified by the ARC Prize team. The Poetiq system achieved a score of 54% on the Semi-Private Test Set, significantly outperforming the previous state-of-the-art held by Gemini 3 Deep Think, which scored 45%.
Beyond the accuracy gains, Poetiq’s system reached this milestone at a cost of $30.57 per problem, compared to the $77.16 per problem cost of Gemini 3 Deep Think. This result suggests that progress in AI reasoning is moving away from purely scaling model size and reasoning tokens and toward the implementation of well-engineered systems that optimize performance at the application layer.
The challenge of ARC-AGI
To understand the significance of this achievement, one must look at the benchmark itself. ARC-AGI-1 (previously called ARC Challenge) is based on the Abstract Reasoning Corpus (ARC) introduced by François Chollet in 2019 to measure intelligence defined as efficient skill acquisition rather than the mastery of fixed tasks.
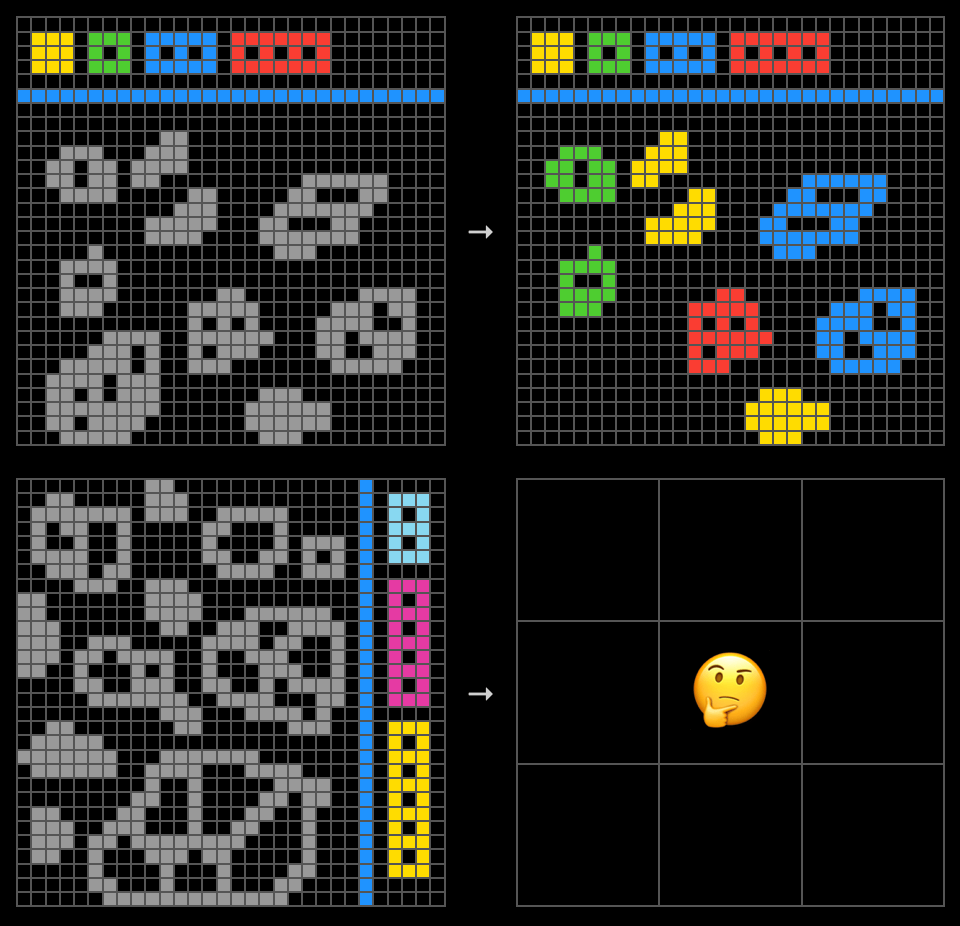
The benchmark consists of grid-based visual puzzles where the solver must infer an underlying rule from a few example input-output pairs and apply it to a new test grid. This format aims to test “core knowledge priors” and generalization, avoiding the pitfalls of benchmarks that can be solved through the memorization of vast training datasets.

The updated ARC-AGI-2, released in March 2025, increased the difficulty to challenge a new generation of hybrid reasoning systems. It includes 1,000 training tasks and targets more complex phenomena such as symbolic interpretation and compositional reasoning. The design explicitly resists brute-force methods. In technical reports from early 2025, leading AI models scored under 5% on ARC-AGI-2, reinforcing the series’ ethos of being easy for humans, hard for AI.
Refinement loops over raw reasoning
Poetiq’s success relies on a move away from standard chain-of-thought (CoT) prompting toward an iterative process known as “refinement.” In this approach, the prompt acts as an interface rather than the sole driver of intelligence. The system does not simply ask a question and accept the output; instead, it generates a potential solution, receives feedback, analyzes that feedback, and uses the underlying large language model (LLM) to refine the answer. This creates a multi-step, self-improving loop that incrementally builds the correct solution.
A key component of Poetiq’s architecture is its “Self-Auditing” feature. The system monitors its own progress and decides when it has gathered enough information or produced a satisfactory solution. This capability allows the system to terminate the process at the optimal moment, preventing wasteful computation. As a result, the system makes fewer than two requests on average per problem, contrasting with the two attempts permitted by the ARC-AGI rules.
Redrawing the Pareto frontier
This method enables Poetiq to construct a “meta-system” that builds intelligence on top of existing frontier models without the need to build or fine-tune new models from scratch. For their winning entry, Poetiq integrated Gemini 3 and GPT-5.1 within hours of their release. By programmatically addressing problems using multiple model calls, the system redrew the Pareto frontier for cost versus performance, delivering higher accuracy at lower costs across the board.
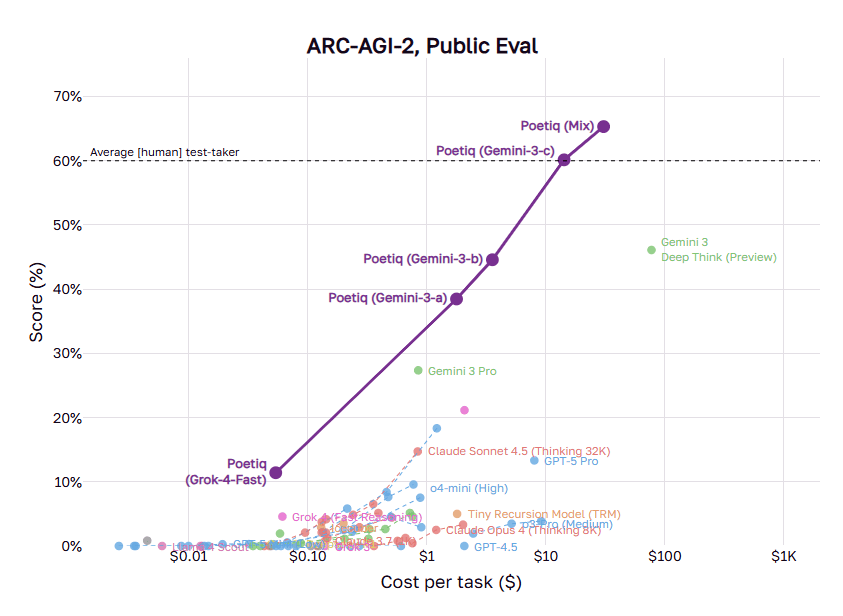
The meta-system is notably LLM-agnostic, proving that the refinement approach generalizes beyond a single model family. Poetiq demonstrated this by applying their technique to models from OpenAI, Anthropic, and xAI. For instance, the “Poetiq (Grok-4-Fast)” configuration achieved accuracy rivaling models that are orders of magnitude more expensive, while “Poetiq (GPT-OSS-b)” delivered strong results for less than one cent per problem. This flexibility indicates that the system adapts to the specifics of the task and the model rather than relying on a single architecture.
The year of the refinement loop
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
The ARC Prize team has characterized 2025 as the “Year of the Refinement Loop.” While raw model knowledge remains a necessary foundation, industry progress is currently being driven by systems that can verify and refine outputs at the application layer.
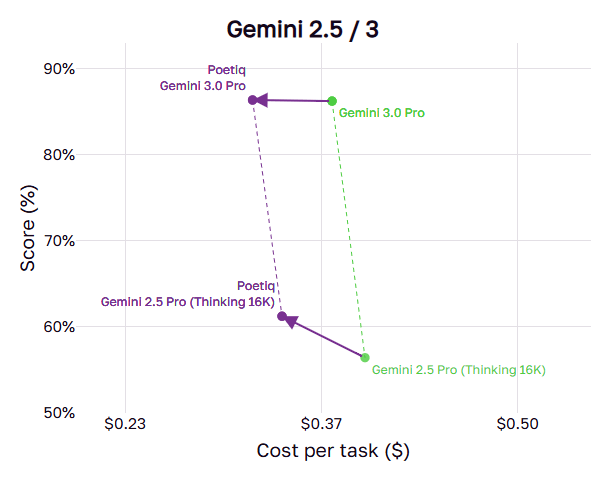
The success of Poetiq’s open-source refinement solution on Gemini 3 Pro (improving performance from a baseline of 31% to 54%) demonstrates the potential of this approach to push AI reasoning further without waiting for new scientific breakthroughs in model training.
Looking ahead, Poetiq intends to expand the application of its meta-system beyond abstract puzzles. The company is exploring how these recursive architectures can solve long-horizon tasks by leveraging the world knowledge already present in frontier models. If the underlying knowledge extraction mechanisms can be transformed to be more “LLM friendly,” it may be possible to solve complex reasoning and retrieval tasks without resorting to updating the models themselves.