



















Nvidia has released the Nemotron 3, a family of open source language models designed for reasoning and multi-agent tasks. Available in Nano, Super, and Ultra sizes, the models feature a hybrid mixture-of-experts (MoE) architecture that delivers high throughput and a massive 1-million-token context window.
Unlike typical open-weight releases, Nvidia has open-sourced the entire development stack, including training data, recipes, and reinforcement learning environments. As an affordable and easy-to-use model, Nemotron 3 might redefine the model landscape and provide Nvidia the chance to crown itself as the king of open-source AI.
Hybrid architecture for efficiency and reasoning
The Nemotron 3 family is built on a hybrid Mamba-Transformer mixture-of-experts (MoE) architecture. The design integrates three technologies into a single backbone to balance speed with intelligence.
Mamba layers handle efficient sequence modeling, which tracks long-range dependencies with minimal memory overhead. Transformer layers provide the detailed attention mechanisms required for precision reasoning in tasks like coding or math. Finally, MoE routing ensures scalable compute efficiency by activating only a subset of parameters for each token.
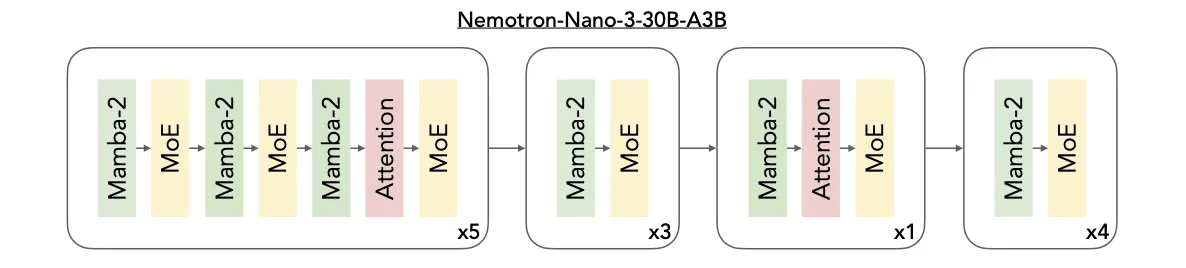
Currently, the Nemotron 3 Nano is available, featuring 30 billion parameters with approximately 3.6 billion active parameters per token. The larger reasoning engines, Nemotron 3 Super (approx. 100 billion parameters) and Ultra (approx. 500 billion parameters), are expected to arrive in the first half of 2026. This staggered release allows developers to begin building high-throughput agentic systems now with Nano, while preparing for the higher reasoning depth of the larger models later.
Nemotron 3 supports a native 1-million-token context window. This capacity allows agents to maintain entire evidence sets, history buffers, and multi-stage plans in a single window without relying on fragmented chunking heuristics. The hybrid Mamba-Transformer architecture enables the processing of these large sequences efficiently, while MoE routing keeps per-token compute low enough to make such long contexts practical during inference.
The model also features “Reasoning ON/OFF” modes and a configurable “thinking budget,” giving developers precise control over how many tokens the model consumes for reasoning versus standard generation, ensuring predictable inference costs.
Innovations in the super and ultra models
While the Nano model focuses on high throughput, the upcoming Super and Ultra models introduce deeper architectural changes to handle complex reasoning at scale. One such innovation is the Latent MoE mechanism. Standard MoE models often face memory and communication bottlenecks because moving massive expert weights and routing data between GPUs is slow. To mitigate this, Latent MoE compresses the input token from a large hidden dimension to a smaller latent dimension before routing it to experts.
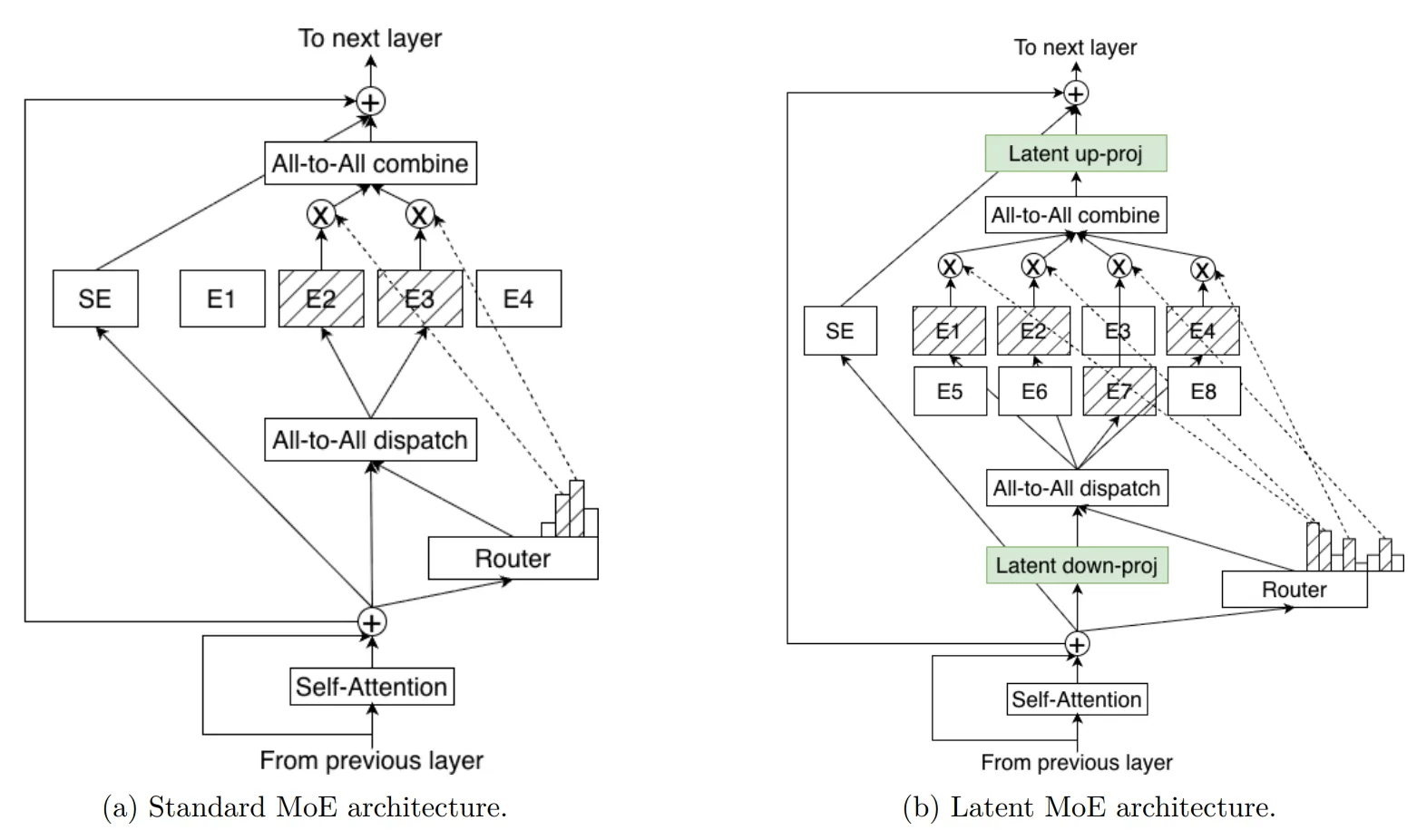
This compression significantly reduces the communication payload, allowing the model to consult more experts without a drop in speed. For example, instead of sending a large data packet to six experts, the system sends a compressed packet to 22 active experts. This results in a smarter model that applies more model capacity to a compressed representation, scoring consistently higher on coding and math benchmarks while maintaining the same inference cost as simpler models.
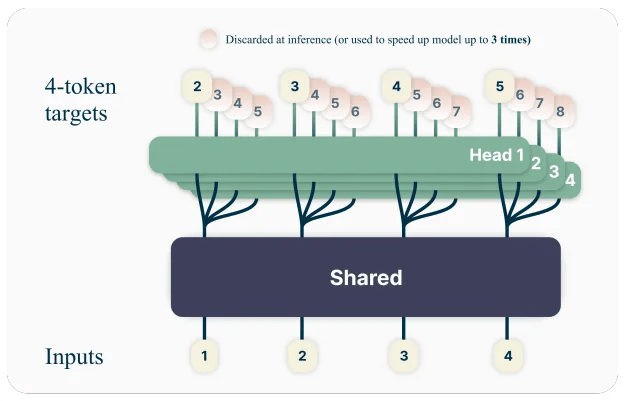
Another key innovation is Multi-Token Prediction (MTP), a technique that was first suggested by researchers at Meta in 2024. Standard large language models (LLMs) typically predict only the immediate next token. The Super and Ultra models are trained to predict multiple future tokens simultaneously. This training method forces the model to plan several steps ahead, improving its reasoning capabilities and common sense understanding. During inference, the MTP module acts as a high-speed drafter, allowing the model to validate and accept a batch of words at once, which accelerates generation.
To support these massive architectures efficiently, the models use NVFP4, Nvidia’s 4-bit floating-point training format. NVFP4 is designed to quantize models to low precision while minimizing the loss in accuracy on tasks. While reducing numbers to 4 bits generally causes information loss, Nemotron 3 employs a hybrid precision recipe. The bulk of the network uses 4-bit compression for speed, but sensitive components (e.g., such as Mamba output layers and MTP projections) are kept in higher precision (BF16 or MXFP8). This approach reduces memory requirements and speeds up training without compromising the intelligence of the model.
Performance in the agentic sweet spot
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
The currently available Nemotron 3 Nano scores 52 on the Artificial Analysis Intelligence Index. This places it well above the average for comparable models, matching OpenAI’s gpt-oss-20b and surpassing Nvidia’s previous Nemotron Nano 9B V2 by 15 points. Crucially for real-time agent interactions, it is also highly efficient, achieving output speeds of approximately 380 tokens per second on serverless endpoints.
This combination of speed and intelligence addresses the specific needs of multi-agent systems. Nano delivers up to 4x higher throughput than its predecessor, Nemotron 2 Nano. It is optimized for tasks such as software debugging, content summarization, and information retrieval.
To ensure reliability in complex workflows, Nvidia trained the model using Reinforcement Learning from Verifiable Rewards (RLVR) across multiple environments simultaneously. By training on diverse tasks, including math, coding, and question answering, at the same time, the model improves uniformly across domains. This reduces “reasoning drift,” a common issue where an agent’s performance degrades as it moves between different types of tasks in a long workflow.
A comprehensive open source ecosystem
Nvidia is releasing more than just model weights; it is providing the infrastructure required to build and train agents. The release includes the NeMo Gym, an open-source library for building and scaling reinforcement learning environments. This allows developers to access the same environments used to train Nemotron 3, including those for competitive coding and advanced math. By decoupling RL environments from training frameworks, NeMo Gym enables developers to test agents, capture edge cases, and perform RL on their own models.
The open release also includes comprehensive data assets. Nvidia has made available 3 trillion tokens of new pre-training data, which includes richer coverage of code and math. Additionally, the release features the Nemotron Agentic Safety Dataset, a collection of nearly 11,000 real-world telemetry traces designed to help researchers evaluate and mitigate safety risks in agentic systems.
Developers can access Nemotron 3 Nano today through Hugging Face or via inference service providers such as Baseten, DeepInfra, and AWS Bedrock. The model is moderately priced at approximately $0.06 per 1 million input tokens and $0.24 per 1 million output tokens.
This full open source release was a power move by Nvidia. Leading AI labs such as OpenAI and Anthropic are all selling models behind paid API services. If they release open source models, it will eat into their market share. Giving away their models for free would be like setting fire to their money at a time where they are already burning cash and have yet to turn in a profit.
Nvidia, on the other hand, stands to gain from the propagation of its models. The more they are adopted, the more AI chips will be needed to run them. And as the main supplier of AI accelerators, Nvidia will benefit the most as the pie for open source models grows. And these models are designed to run optimally on Nvidia hardware, which is in a way also a response to the growing slate of competing AI accelerators that have been cropping up in the recent years.
Well played, Jensen.