")




















This article is part of our coverage of the latest in AI research.
Researchers at Stanford University and Nvidia have developed a new model architecture and training technique for language models to handle very long context tasks without blowing up memory and compute costs. Their technique addresses the issue of “continual learning,” where models are designed to adapt to changing information in dynamic environments rather than remaining static after their initial training.
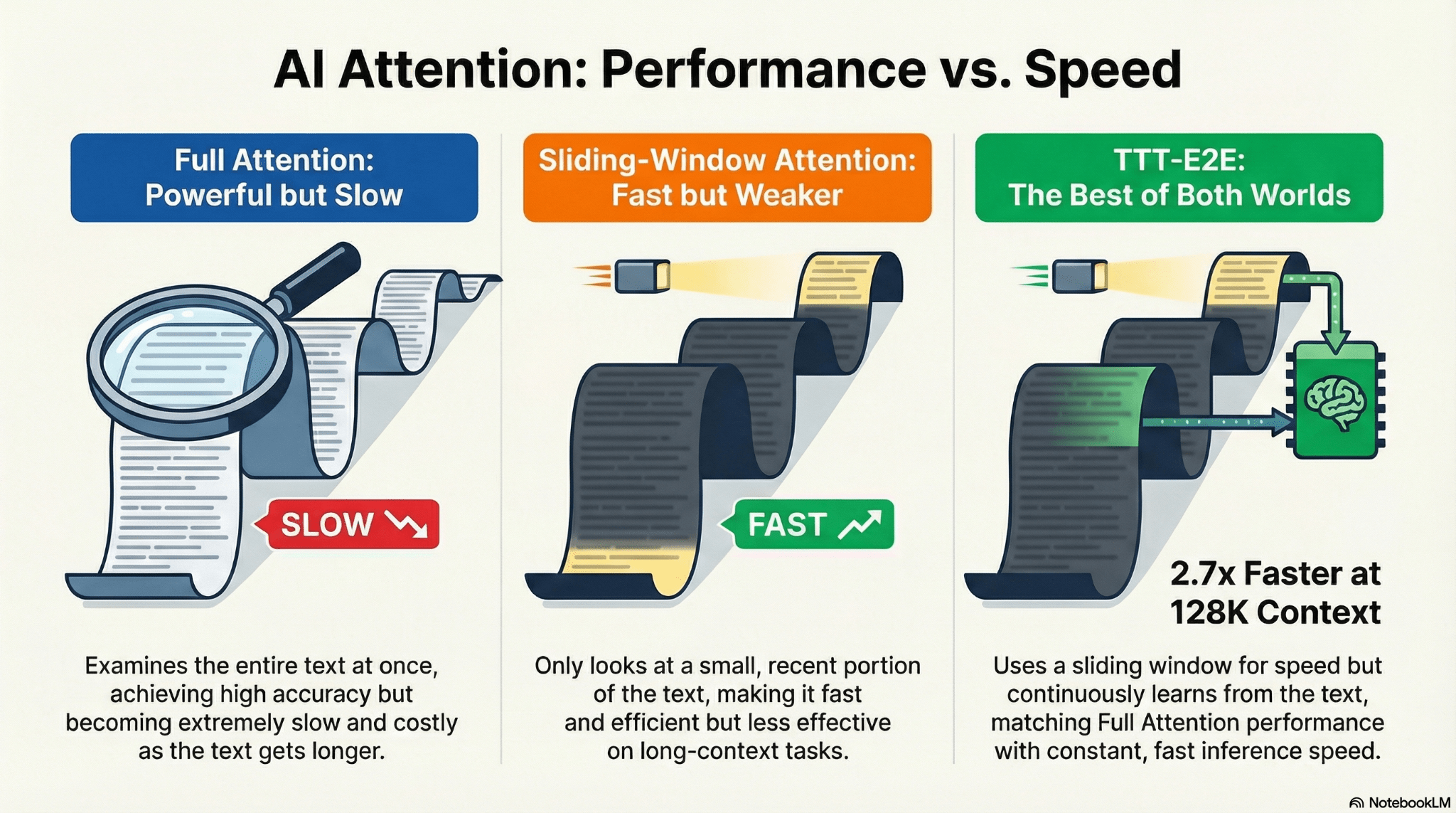
Their method, which they describe as “End-to-End Test-Time Training for Long Context” (TTT-E2E), defines language modeling as a continual learning problem where the model actively updates its own parameters during inference. The technique also makes changes to the transformer architecture in a way that doesn’t require caching the attention value of every token in the input sequence. This adjustment creates a best-of-both-worlds situation. Their experiments show that on 128k context tasks, the model achieves the accuracy of full-attention transformers while being 2.7x faster, matching the speed of linear-attention models such as Mamba 2.
Accuracy vs efficiency
To understand the significance of this approach, it is necessary to look at the current tradeoff between accuracy and efficiency when working on longer contexts. Full-attention transformers are currently the gold standard for accuracy because they are designed to recall every token in the input sequence.
However, they are inefficient because they need to calculate and store the attention value of every token, making them computationally expensive and slow on tasks with very long input sequences.
On the other hand, linear-attention models with RNN-based architectures, such as Mamba 2 and Gated DeltaNet, have a constant cost per token. While faster, they are generally less accurate on long-context tasks and tend to miss important information. There are also mid-way alternatives, such as sliding window attention (SWA), which calculate attention for a fixed number of tokens, and hybrid models that combine transformer and RNN layers. While these somewhat address the efficiency problem, they still lag behind full attention transformers in language modeling performance.
The researchers argue that to achieve better performance in longer contexts without the prohibitive cost of recalling every detail, we need a compression mechanism. They draw a parallel to human cognition, noting that humans “compress a massive amount of experience into their brains, which preserve the important information while leaving out many details.”
Modifying the architecture for compression
To adapt the Transformer architecture for this compression-based approach, the researchers introduced several key modifications. First, they replaced the computationally expensive full attention mechanism with “Sliding Window Attention.” Instead of looking at every previous token in a document, the model looks back at a fixed window of recent tokens. This ensures the cost of processing a new token remains constant rather than growing as the model’s context gets longer.
However, a sliding window normally implies that any information falling out of the window is lost. To prevent this, the researchers introduced a targeted weight update mechanism. Standard models have frozen weights during use, but this new architecture keeps most of its weights frozen while designating specific components (MLP layers in the final 25% of the model’s blocks) to be mutable.
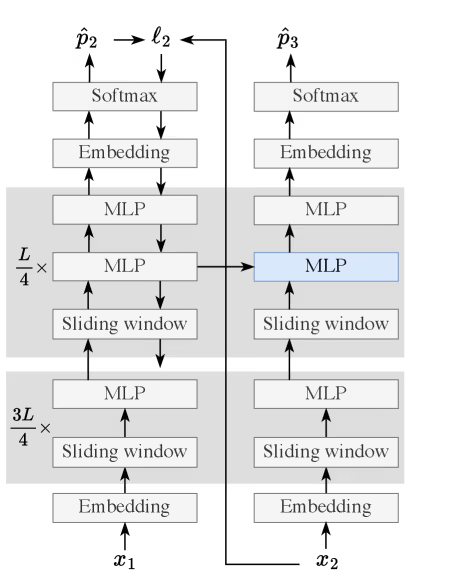
To prevent the model from forgetting its original training when these updates occur, the architecture uses a dual-track storage system. Each updateable block contains two MLP layers: one static layer to hold general pre-trained knowledge, and one dynamic layer that updates in real-time to store the current document’s context.
This results in a dual memory architecture that the researchers claim mimics biological memory. The Sliding Window Attention acts as a “working memory,” handling immediate syntax and local references. Meanwhile, the weight updates act as “long-term memory,” consolidating the gist and facts of the earlier parts of the document into the model’s structure via next-token prediction. And the immutable MLPs preserve the static knowledge the model acquired during pre-training.
Learning to learn
The core engine of this system is the concept of Test-Time Training (TTT). In standard machine learning, models are optimized to reduce their loss during the training phase and are then frozen. They are not designed to update themselves during inference. The researchers address this by preparing the model’s initialization via meta-learning instead of standard pre-training.

Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.