



")















This article is part of our coverage of the latest in AI research.
With machine learning becoming part of many applications we use every day, there is a growing focus on identifying and addressing the security and privacy threats of ML models.
However, security threats vary across different machine learning paradigms, and some areas of ML security remain understudied. In particular, the security of reinforcement learning algorithms has not received much attention in recent years.
A new study by researchers at McGill University, Mila, and the University of Waterloo focuses on the privacy threats of deep reinforcement learning algorithms. The researchers propose a framework for testing the vulnerability of reinforcement learning models against membership inference attacks.
The results of the study show that adversaries can stage effective attacks against deep RL systems and potentially obtain sensitive information used in training the models. Their findings are significant as reinforcement learning is finding its way into industrial and consumer applications.
Membership inference attacks

Every machine learning model is trained on a set of examples. In some cases, training examples include sensitive information, such as health or financial data, or other personally identifiable information.
Membership inference attacks are a series of techniques that try to force ML models to leak data about their training set. While adversarial examples, the better-known type of attack against machine learning, are focused on altering the behavior of ML models and are regarded as a security threat, membership inference attacks are focused on extracting information from the models and are more of a privacy threat.
Membership inference attacks have been thoroughly studied in supervised ML algorithms, where the model is trained on labeled examples.
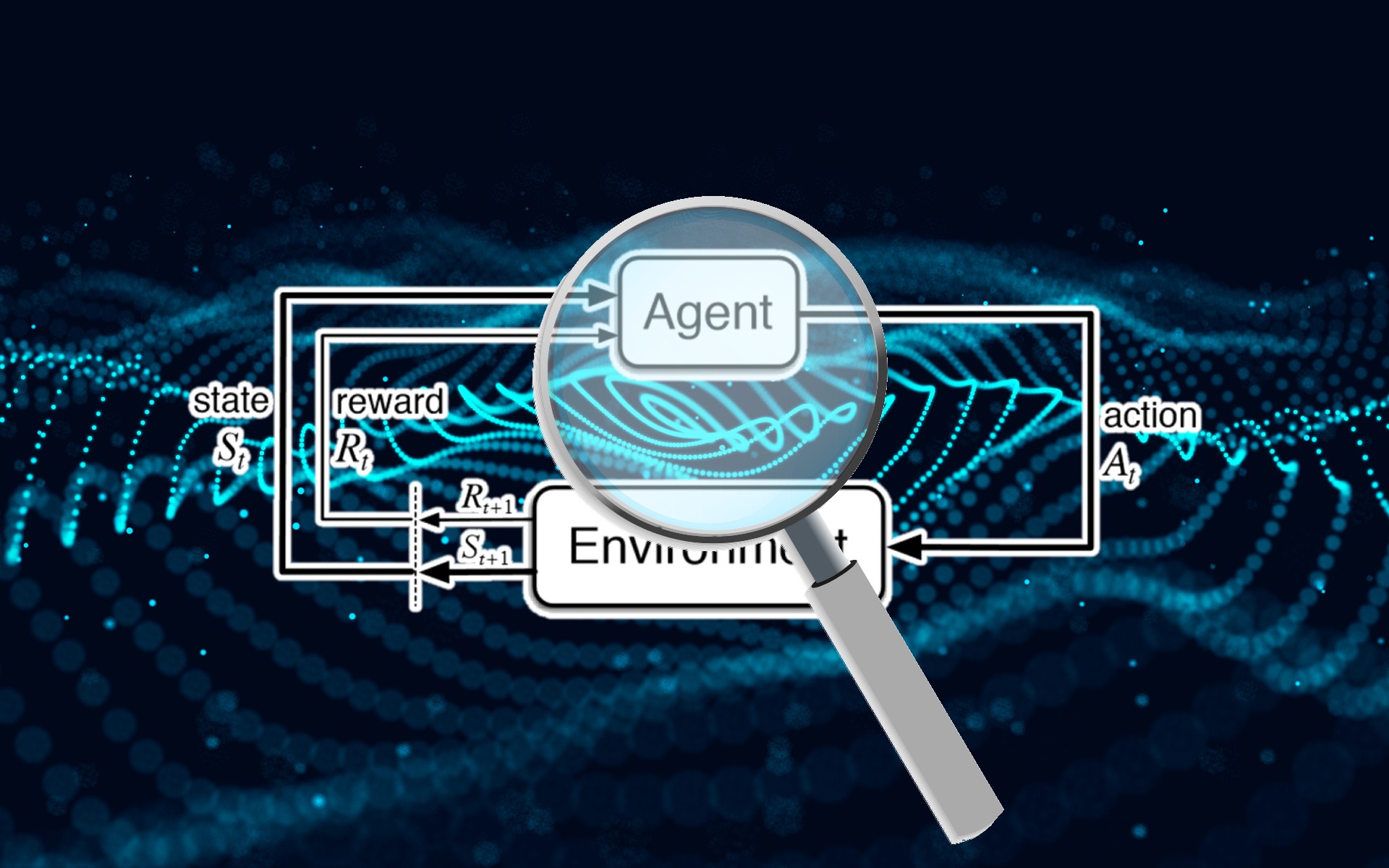
Unlike supervised learning, deep reinforcement learning systems don’t use labeled examples. An RL agent receives rewards (or penalties) from the interactions it makes with the environment. It gradually learns and develops its behavior through these interactions and reinforcement signals.
“The rewards [in reinforcement learning] do not necessarily represent labels; thus, they cannot act as a prediction label often used in membership inference attack design in other learning paradigms,” the authors of the paper told TechTalks in written comments.
In their paper, the researchers write, “There has been no study on the potential membership leakage of the data directly employed in training deep reinforcement learning (deep RL) agents.”
This lack of research is partly due to the limited application of reinforcement learning in the real world.
“Despite the substantial advancements in the deep reinforcement learning domain, e.g., AlphaGo, AlphaFold, and GT Sophy, deep RL models have still not been widely adopted at the industrial scale,” the authors said. “Data privacy, on the other hand, is a very applied field of research, and the lack of real-world industrial application for deep RL models has significantly delayed research in such a fundamental and vital area of research, leading to attacks against RL systems being understudied compared to other related areas.”
With the growing demand for the application of RL algorithms at the industrial scale in real-world scenarios, the need for much greater attention and rigor to frameworks that address the privacy aspects of RL algorithms both from an adversarial and algorithmic standpoint is becoming increasingly evident and relevant.
Challenges of membership inference in deep reinforcement learning

“Our efforts in developing the first generation of privacy-preserving deep reinforcement learning algorithms made us realize the fundamental structural differences between classic machine learning (ML) algorithms and reinforcement learning algorithms from the privacy point of view,” the authors said.
More critically, the fundamental differences between deep reinforcement learning and other learning paradigms pose serious challenges in deploying deep RL models for real-world applications, given the potential privacy ramifications, the researchers found.
“Motivated by this realization, the big question for us was: How vulnerable are deep RL algorithms to privacy attacks such as membership inference attacks?” the authors said. “Existing MIA attack models are designed particularly for other learning paradigms, and so how vulnerable DRL algorithms are to this class of attacks is largely unknown. This curiosity for the unknown and the need to bring awareness to the research and industrial communities, given the serious privacy ramifications with deployment in the world, was the primary motivation behind this study.”
During training, reinforcement learning models go through episodes, each of which consists of a trajectory or sequence of actions and states. Therefore, a successful membership inference attack algorithm for reinforcement learning must learn both the data points and trajectories used in training the model. On the one hand, this makes it substantially more difficult to design membership inference algorithms against RL systems, while on the other, it makes it difficult to assess the robustness of RL models against such attacks.
“MIA is difficult in RL compared to other types of ML because of the sequential and temporally correlated nature of data points that are used in the training process. The many-to-many relationships between the training and prediction data points fundamentally differ from other learning paradigms,” the authors said.
The fundamental differences between RL and other ML paradigms make it crucial to think in new ways when designing and evaluating membership inference attacks for deep reinforcement learning.
Designing membership inference attacks against RL systems
In their study, the researchers focus on “off-policy” reinforcement learning algorithms, in which the data collection and model training processes are separated. Off-policy reinforcement learning uses “replay buffers” to decorrelate input trajectories and make it possible for the RL agent to explore many different trajectories from the same set of data.
Off-policy RL is especially crucial to many real-world applications, where training data exists in advance and is provided to the ML team that is training the RL model. Off-policy RL is also crucial to creating membership inference attack models.

“The exploration and exploitation phases are decoupled in true off-policy RL models. Thus, the target policy does not influence the training trajectories,” the authors said. “This setup is particularly preferred in designing MIA frameworks in a black-box setting, where neither the internal structure of the target model nor the exploration policy used to collect the training trajectories is known to the adversary.”
In black-box MIA attacks, the attacker can only observe the behavior of the trained reinforcement learning model. In this particular case, the attacker assumes that the target model has been trained on trajectories generated from a private set of data, which is how off-policy RL works.

In their study, the researchers chose “batch-constrained deep Q learning” (BCQ), a state-of-the-art off-policy RL algorithm that has shown remarkable performance in control tasks. However, they state that their membership inference attack technique can be extended to other off-policy RL models.
One way to stage MIA attacks is to develop a “shadow model.” This is a classifier ML model that has been trained on a mix of data that come from the same distribution as the target model’s training data and elsewhere. Once trained, the shadow model can discriminate between data points that belong to the target ML model’s training set and new data that the model hasn’t seen before. Creating shadow models for RL agents is tricky because of the sequential nature of the training of the target model. The researchers accomplished this through several steps.
First, they provide the RL model trainer with a new set of non-private data trajectories and observe the trajectories generated by the target model. The training and output trajectories are then used by an attack trainer that trains an ML classifier to detect input trajectories that were used in the target RL model’s training. Finally, the classifier is provided with new trajectories, which it classifies as training members or novel data examples.

Testing MIA against RL systems
The researchers tested their membership inference attacks in different modes, including different trajectory lengths, single trajectories vs multiple trajectories, and correlated vs decorrelated trajectories.
“The results show that our proposed attack framework is remarkably effective at inferring the RL model training data points… the obtained results demonstrate high privacy risks in employing deep reinforcement learning,” the researchers note in their paper.
Their findings show that attacks with multiple trajectories are more efficient than single trajectories, and the accuracy of the attacks increases as trajectories become longer and correlated to each other.
“The natural setting is, of course, the individual model, where the adversary is interested in identifying the presence of a particular individual (in RL setting the entire trajectory) in the training set used to train the target RL policy,” the authors said. “However, the better performance of MIA in the collective mode suggests that apart from the temporal correlations captured by the features of the trained policy, the adversary can also exploit the cross-correlation between the training trajectories of the target policy.”
Of course, this also implies that an attacker needs a more complex learning architecture and more sophisticated hyper-parameter tuning to exploit the cross-correlation among the training trajectories and the temporal correlation within a trajectory, according to the researchers.
“Understanding these different modes of attack gives us deeper insights into the implications on the security and privacy of the data as it allows us to better understand the different perspectives from which an attack can occur and the degree of impact on privacy breaches,” the researchers said.
Membership inference attacks against RL systems in the real world
The researchers tested their attack on RL models trained on three tasks based on the OpenAI Gym and MuJoCo physics engine.
“Our current experiments cover three high-dimensional locomotion tasks, Hopper, Half-Cheetah, and Ant,” the researchers said. “These tasks are all under the umbrella of robotics simulation tasks that primarily motivate the extension of experiments to real-world robot learning tasks.”
Another exciting direction to apply membership inference attacks is dialogue systems, such as Amazon Alexa, Apple Siri, and Google Assistant, the researchers of the paper say. In these applications, a data point is presented by a full trajectory of interactions between the chatbot and the end user. In this setting, a chatbot is the trained RL policy, and the user interactions with the bot form the input trajectory.
“In this scenario, the collective mode is the natural setting. In other words, the user’s presence in the training set can be inferred by the adversary if and only if the attacker correctly infers a batch of trajectories that represents the user in the training set,” the authors said.
The team is exploring other real-world applications where these kinds of attacks could impact RL systems. They might also look at how these attacks apply to reinforcement learning in other settings.
“An interesting extension to this line of research is to investigate MIAs against Deep RL models in a white-box setting where the internal structure of the target policy is also known to the adversary,” the authors said.
The researchers hope that their findings will shed light on the security and privacy concerns of reinforcement learning applications in the real world and raise awareness among the ML community to conduct more studies in this area.