



















In partnership with 123RF
In recent months, generative artificial intelligence has created a lot of excitement with its ability to create unique text, sounds, and images. But the power of generative AI is not limited to creating new data.
The underlying technology of generative AI, including transformer and diffusion models, can power many other applications. Among them is the search and discovery of information. In particular, generative AI can revolutionize image search and enable us to browse visual information in ways that were previously impossible.
Here is what you need to know about how generative AI is redefining the image search experience.
Image and text embeddings
Classic image search relies on textual descriptions, tags, and other metadata that accompany images. This limits your search options to information that has been explicitly registered with the images. People who upload images must think hard about the kind of search queries users will enter to make sure their images are discovered. And when searching for images, the user who is writing the query must try to imagine what kind of description the uploader might have added to the photo.
However, as the saying goes, an image is worth a thousand words. There is only so much that can be written about an image, and depending on how you look at a photo, you can describe it in many different ways. Sometimes, you are interested in objects. Other times, you want to search images based on style, lighting, location, etc. Unfortunately, such rich information rarely accompanies images. And many images are just uploaded with little or no information, making it very difficult to discover them.
This is where AI image search comes into play. There are different ways to perform AI image search, and different companies have their own proprietary technology. However, some things are common across all of them.
At the heart of AI image search (and many other deep learning systems) are embeddings. Embeddings are numerical representations of different data types. For example, a 512×512 resolution image contains around 260,000 pixels (or features). An embedding model tries to learn a low-dimensional representation of visual data by training on millions of images. Image embeddings can have many useful applications, including compressing images, generating new images, or comparing the visual properties of different images.
The same mechanism works for other modalities such as text. A text embedding model is a low-dimensional representation of the contents of a text excerpt. Text embeddings have many applications, including similarity search and retrieval augmentation for large language models (LLM).

How AI image search works
But things get even more interesting when image and text embeddings are trained together. Open-source datasets like LAION contain millions of images and their corresponding text descriptions. When text and image embeddings are jointly trained or fine-tuned on these image/caption pairs, they learn associations between visual and text information. This is the idea behind deep learning techniques such as contrastive image-language pre-training (CLIP).
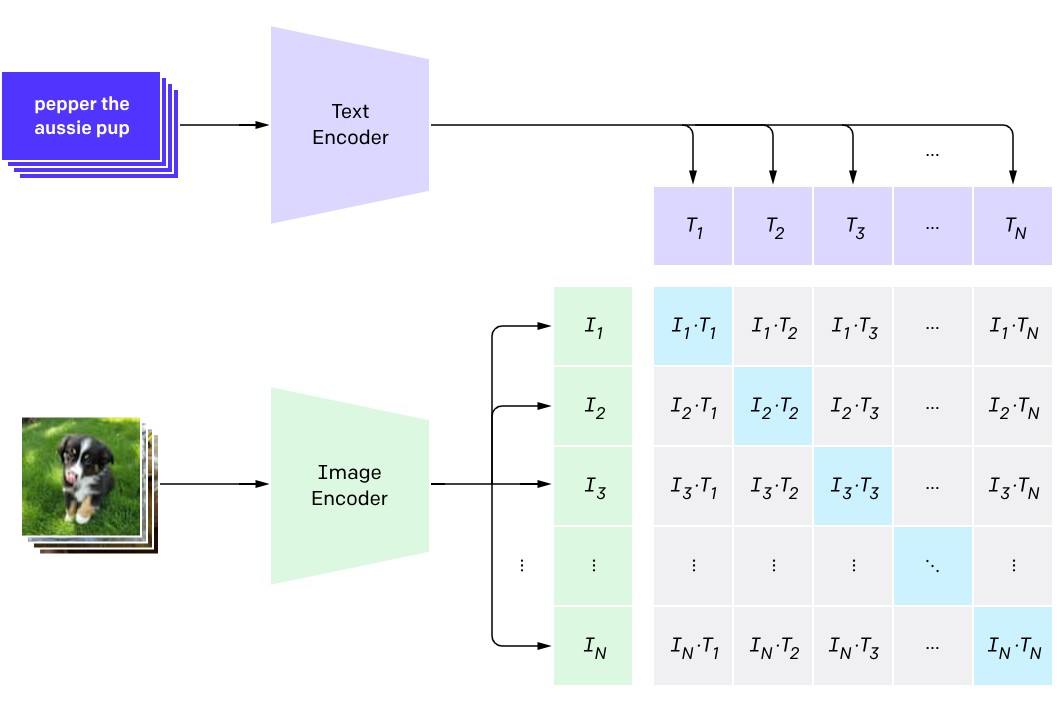
You now have a tool that can go from text to visual embeddings. When you provide this joint model with a textual description, it creates the text embedding and its corresponding image embedding. You can then compare the image embedding to those of the images in your database and retrieve the ones that are the most closely related to it. This is basically how AI image search works.
The beauty of this mechanism is that you’ll be able to retrieve images based on the textual description of their visual features, even if that description is not registered in their metadata. You can use rich search terms that weren’t possible before, such as “a lush forest with morning mist, tall pines with lens flare, with mushrooms on a grass-covered floor.”

In the example above, the AI search returned a set of images whose visual features matched my query. The text descriptions of many of them do not contain the keywords of my query. But their embeddings are similar to the embedding of my query. Without AI image search, it would have been much more difficult—if not impossible—to find a suitable image.
From discovery to creation
Sometimes, the image you are looking for does not exist and even AI search will not find it for you. In this case, generative AI can help you achieve the desired results in one of two ways.
The first is to create a new image from scratch based on your query. In this case, a generative model (e.g., Stable Diffusion or DALL-E) creates the embedding for your query and uses it to create the image for you. Generative models take advantage of joint embeddings models such as CLIP and other architectures (such as transformers or diffusion models) to transform the numerical values of embeddings into stunning images.

The second approach is to take an existing image and use a generative model to edit it to your liking. For example, in the above images, the mushrooms are missing. I can use one of the images that I find suitable as a starting point and use a generative model to add mushrooms to it.

Generative AI creates a totally new paradigm that blurs the line between discovery and creativity. In a single interface, you can go from finding images to editing them or creating totally new ones.