



")
















“Take”
“Take” refers to the traditional software-as-a-service (SaaS) model where you use the software “as is” off-the-shelf. There are various options available. They include:
Public access: Access to closed tools like OpenAI’s ChatGPT may be viable for some organizations. It is also free (if you believe in such a concept) and frictionless (aside from creating an account).
Power and business accounts: ChatGPT Plus provides priority access during peak times, faster response times, and priority access to new features, models, and higher usage limits at a fee of $20/month per user. Jasper has a similar service for $49/month plus a “teams” account starting at $99/month that includes corporate templates and user management. These services target power users but may not be appropriate for businesses. OpenAI admitted as much when they announced that ChatGPT for Business is coming soon (expected in “the coming months”). It promises corporate data “will not be used to train models by default,” perhaps easing privacy concerns from leaking proprietary business strategies, intellectual property, and personal user data to third parties. The possibility of privacy breaches is particularly important for businesses in regulated industries or jurisdictions with strong data protection laws (e.g., CA, NY, and MA).[1]
API: API access is available for easy and fast development. This is a great option for rapid prototyping, evaluating the effectiveness of generative technology in various use cases, and allowing multiple departments or business units to experiment simultaneously. Small and midsized businesses without training data or technology expertise may find API access optimal for deploying applications. OpenAI recently announced that developers can fine-tune GPT-3.5 Turbo via the API. While the cost is about 8x of generating output from the base GPT-3.5 Turbo model, this may be a better fit for some businesses.[2],[3] It’s important to note that even with a million-dollar investment, it may be challenging to match the general performance and latency of these commercial models.[4]
Private instances: Microsoft Azure provides a private instance of ChatGPT. According to Microsoft, prompts (inputs) and completions (outputs), embeddings, and training data are not available to other customers or to improve any products or services such as OpenAI models, Microsoft Azure, or any other 3rd party.[5],[6] Morgan Stanley is deploying ChatGPT on private servers to prevent data leakage. However, the additional control over your data comes at a higher cost. The dedicated service is expected to cost up to 10 times more than the standard version. This option may appeal to businesses that worry about privacy and do not worry about the cost when evaluating various use cases.
While “take” has attractive aspects, there are causes for concern.
1- Privacy: Privacy concerns exist when employees share sensitive corporate data with public models. Sharing corporate data with a leaky tool that collects all user prompts for training a model that memorizes data and is stored on external servers commingled with other customers without an easy way to access or delete such data is frightening. It was just a few months ago that a bug in ChatGPT revealed data from other users.[7] For industries with strict regulatory requirements, such as healthcare, finance, or defense, private instances and business accounts can address this issue but have a hefty price tag. More realistically, on-premises solutions can offer greater control over data, ensuring that sensitive information never leaves the organization’s physical boundaries.
2- Market factors: Such an adoption strategy depends on another. There may be some loftier calling to pride or just the acknowledgment that your operations will be disrupted if a provider experiences downtimes, raises prices, deprecates technology, changes their terms and conditions, or discontinues their service (e.g., due to regulatory pressures). This is especially problematic if you are actively reducing headcount because of generative technology.[8],[9]
3- Short-termism: AI budgets are increasing, but much of that spending is taken from other business areas. This downward pressure forces AI projects to be less exploratory, less patient (e.g., overlooking safety, security, compliance, and governance), and hastier. These dynamics create short-termism, resulting in companies making rash decisions focusing on immediate results to the detriment of long-term growth. Short-termism is technical debt. Whatever advantages are gained in the short term are lost over the long term because you won’t own the model or the data. Businesses must balance benefits in the near term with sustainable value creation over the long term.
4- Customization: While generative technology is trained on diverse internet text, it may only partially capture a particular business or industry’s context, problems, and preferences. This, in turn, means using the technology “as is” and “off-the-shelf” will produce few competitive advantages.
5- Stateless models: Generative technology should improve with use. You can guide SaaS models like ChatGPT or Copilot toward intended goals and ensure more accurate and valuable responses by providing prompts for training. However, your model remains stateless if your data and prompts are not utilized to influence future performance. Simultaneously, there is no guarantee that sharing prompts will improve performance. User-generated prompts can be highly variable and affect the model’s reliability and performance without proper curation, monitoring, and oversight. Consider that researchers recently found that ChatGPT performance has not improved but worsened.[10] This paradox illustrates an obstacle between stateless models you don’t own (and can’t train or tune) and stateful models you can’t control or monitor.
6- Regulations and Compliance: The Research on Foundation Models and Institute for Human-Centered Artificial Intelligence at Stanford University recently assessed the adherence to the AI Act by generative model providers, including OpenAI, Cohere, Stability.ai, Anthropic, Google, HuggingFace, Meta, AI21 Labs, Aleph Alpha, and EleutherAI. (Figure 1) The evaluation revealed considerable inconsistency in compliance between models, with some scoring below 25% and only one achieving at least 75% (i.e., HuggingFace’s BLOOM).[11] For enterprise adoption, this means there is regulatory, ethical, and legal risk associated with using third-party models pretrained on third-party inscrutable datasets. Businesses must perform due diligence when integrating such technologies. Moreover, the FTC has clarified that you can’t plead ignorance using someone else’s model, which is especially serious in high-risk domains like healthcare and finance. Companies must complete their own risk analysis and exercise due diligence.[12]

Final thoughts on “Take”
These state-of-the-art models offer insight into what is possible with generative technology, making them perfect for education and evaluating various use cases.
However, you may not want to pay for restricted access to closed models you can’t train, tune, or audit to achieve compliance when free, unrestricted alternatives you can control are available with comparable quality.
What you need to know about these models:
Size: They’re massive, 100B+ parameters (some are 1T+ parameters). They require specialized hardware and millions of dollars to train. Moreover, they will require massive datasets (i.e., trillions of tokens).
Purpose: These large models will excel at zero-shot learning. The term “zero-shot” refers to the ability of a model to perform a task it hasn’t been explicitly trained on.
Consideration: Large models are useful when you lack specific training data for a task or want to test whether they can handle a task without specific training. These large models are generally used when no data is available for fine-tuning or probing whether a task is feasible zero-shot.
Applications: Large models are ideal for complex tasks that require substantial reasoning capabilities or highly specialized zero-shot learning. However, their size is a critical development and deployment challenge (even for the companies that develop them). GPT-4 has an estimated 1.7 trillion parameters and has not been retrained since September 2021.[13] The reason is that retraining large models every few months is not a mere “inconvenience.”
“Shape”
Pretrained generative models are trained on uncurated samples of the internet—consequently, pretrained models are raw and need to be transformed into something refined and specific. Domain-specific training is often necessary, especially if your project contains specialized language and knowledge. If you’re developing an app to assist lawyers, you’ll encounter domain-specific terms like “res judicata.” Such words are unlikely to be heavily represented in the training data for initializing foundational models. Similarly, healthcare, finance, and automotive terms might be underrepresented in general web content. Thus, fine-tuning a model for specialized fields like law, medicine, finance, or scientific research yields superior results to pretrained models. However, to whatever extent possible, machine “understanding” arises from foundational training. Foundational training is initializing a generative model from scratch with corporate data instead of generic data scraped from the Internet. This section will examine both use cases (i.e., training from scratch and fine-tuning pretrained models) and briefly discuss a third way.
Train from Scratch:
Training from scratch is the hard path to adoption. Take, for instance, BloombergGPT.[14] The model was designed at a foundational level for the financial sector and combined an internal financial dataset (named “FinPile” with 363 billion tokens) with public data (345 billion tokens from general-purpose datasets). By training a model from scratch, Bloomberg created a domain-specific language model that makes future adaptations faster and more nuanced. The reason for using a mixture of domain-specific and public data is a model that excels in financial assessments while also performing well on standard benchmarks.

Bloomberg used a guideline called the Chinchilla scaling principles to decide on the smallest viable model for their goals. Bloomberg wanted to train a model on all their corporate data (5B tokens or ~3.75B words) and “still leave ~30% of the total compute budget as a buffer for unforeseen failures, retries, and restarts.” Figure 2 shows the best size for a model based on computer power and how much data is required for training. The result was a 50B parameter model that roughly adheres to the Chinchilla optimal size for their compute budget of 1.3 million GPU hours (or approximately $1m).[15] The 30% “buffer” demonstrates how much slack there is (at least today) in adopting generative technology from scratch.[16] Figure 3 shows the benefit of a trained model that outperforms larger but general models with the largest difference for specialized in-domain categories like “Filings.”
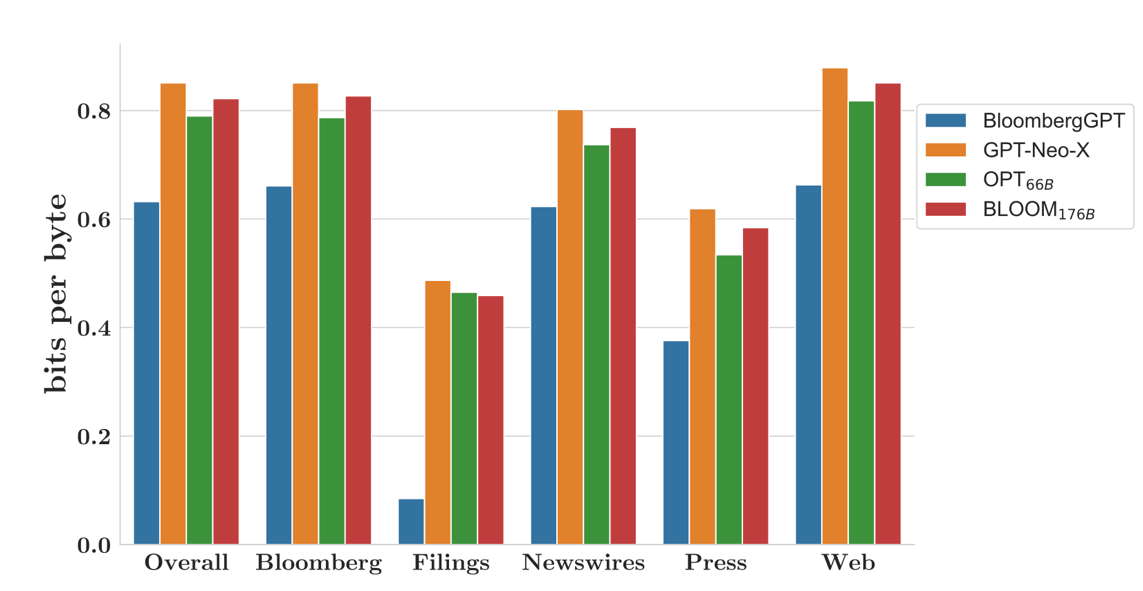
Ultimately, specialized models will outperform bigger (and more expensive) models created for another purpose (or a general purpose) as long as data exists. Moreover, humans can’t always differentiate between a small model and ChatGPT, which has been optimized for aesthetics. A recent study conducted by Berkeley compared the human preferences for Koala (a 13B parameter model that costs around $100 to tune) and ChatGPT. Although ChatGPT was slightly more preferred, more than 50% of users either preferred Koala or had no preference at all.[17] This indicates that humans may not care or even notice the differences in appearance between small models and large models.
Adapt an existing model:
If training a model from scratch is the hardest path, then an easier (though nontrivial) option is to adapt an existing model with fine-tuning. This process trains the model to perform better on various tasks by using examples that show how it should respond to specific instructions. For instance, you will create a dataset with instructions to summarize text to make a model better at summarizing text. This is tedious (and requires considerable resources), but fortunately, developers have created template libraries that can turn existing datasets, like product reviews, into instruction prompt datasets for fine-tuning.[18],[19],[20]
Fine-tuning can be used for a single task or multiple tasks. Summarization, for instance, is a single task that can yield good results with fewer examples, usually hundreds of samples instead of billions of tokens required for training. A potential downside to fine-tuning is known as catastrophic forgetting. While fine-tuning can improve performance for a given task, it can also impair performance on other (previously tuned) tasks. An example is when a model forgets how to perform sentiment analysis while being fine-tuned for summarization. Catastrophic forgetting can be useful if the model is designed to do one thing, such as Gorilla (Figure 4), which is a model tuned to generate code for API calls.

Fine-tuning can also be done simultaneously on various tasks. Multitask fine-tuning trains a model to carry out various tasks using a mixed dataset on all the tasks simultaneously, mitigating the risk of catastrophic forgetting. This method requires a large amount of data, typically from 50,000 to 100,000 examples. If you need good performance for multiple tasks, multitask fine-tuning may be worth the effort. FLAN (Fine-tuned LAnguage Net) is a specific set of instructions to fine-tune different models.[21] Since it is the final step in the training process, Hyung Won Chung et al. referred to it as the “metaphorical dessert to the main course.”[22]
When fine-tuning a generative model, it’s important to remember that it requires more than just memory for storing the model itself. You also need resources for storing optimizer states, gradients, forward activations, and temporary memory throughout the training process. These additional components can be larger than the model itself. When you fine-tune the entire model for a new task, it creates a new version of the model that’s just as large as the original. However, parameter-efficient fine-tuning involves training a small number of task-specific adapter layers and parameters while freezing most model weights.[23] This process reduces the number of trained parameters, making memory requirements more manageable. Parameter-efficient fine-tuning also reduces the risk of catastrophic forgetting during full fine-tuning since the original model is only slightly modified.
There are several methods for parameter-efficient fine-tuning, each with trade-offs on parameter efficiency, memory efficiency, training speed, model quality, and inference costs.
– Selective methods tune a subset of the original parameters.
– Additive methods introduce new trainable layers without changing the original weights.[24]
– Soft prompts add trainable parameters to the prompt embeddings, keeping the input fixed and retraining the embedding weights.
– Reparameterization methods reduce the number of parameters to train by creating new low-rank transformations of the initial network weights. A commonly used technique of this type is low-rank adaptation (LoRA), which shows some flexibility to scaling laws (e.g., Chinchilla scaling principles). [25],[26]
Another fine-tuning option is training a smaller model to mimic the behavior of a larger (proprietary) model, such as ChatGPT, using a smaller data set of outputs generated by the larger model. This process is called model imitation. As the name suggests, the hope is to imitate the proprietary model’s behavior and (hopefully) performance using a less powerful (likely smaller) open-source model. However, any urge to use larger models for fine-tuning is generally a bad idea. First, commercial models prohibit this kind of training, violating the terms of use.[27] Second, Gudibande et al. find that the imitation models fail to close the general performance gap between the base model and ChatGPT, particularly on tasks not heavily represented in the imitation data.[28],[29],[30] They highlight that the “imitation models are adept at mimicking ChatGPT’s style but not its factuality.” The disparities in capabilities between smaller (often less capable) open-source and large (proprietary) models cannot be effectively addressed by imitating proprietary models, except through an impractical amount of imitation data or by utilizing more capable (i.e., larger) base models.
If you’re clever, you may consider fine-tuning a smaller model to mimic the behavior of a larger (open-source) model. This does not address the fundamental issues with imitation, but it avoids violating the terms of use of Bard, ChatGPT, and Claude. However, the creators of open-source models like Meta prohibit (for example) using the LLaMA 2 model to train other models. This example highlights the complexity of licensing for generative technology, even when it is “open-source.” Rather than taking shortcuts, the most effective strategy for improving the performance of smaller models lies in training a foundational model from scratch in your domain with foundational knowledge or fine-tuning a model with specialized language for specific tasks.
While “shape” has attractive aspects, there are causes for concern.
1- If your team lacks technical expertise, these options may be out of reach or require external support.
2- By “shaping” models, you must evaluate them anew, and choosing the correct evaluation dataset is crucial. Benchmark datasets like GLUE and SuperGLUE cover various tasks and scenarios.[31],[32] MMLU and BIG-Bench are benchmarks that evaluate world knowledge and problem-solving ability.[33] HELM takes a multimetric approach, measuring seven metrics across 16 core scenarios, including fairness, bias, and toxicity metrics. The Robustness Gym is an evaluation toolkit aimed at assessing the performance and robustness of real-world applications by integrating four evaluation methodologies: subpopulations, transformations, evaluation sets, and adversarial attacks. BloombergGPT used some standard language model benchmarks, open financial benchmarks, and a suite of internal benchmarks that reflected their intended business application.
3- There is a third way to improve performance in addition to training a foundational model from scratch or fine-tuning a model with specialized language. So-called grounded generation inserts external knowledge (e.g., information stored in task-specific databases) into generated responses.[34] See note below.[35]
4- None of these suggestions address congenital defects that result from generative models inexplicably memorizing training data and inadvertently exposing sensitive, copyrighted, or private information. Despite the quality of training data, model architecture, or fine-tuning procedure, generative technology is prone to attacks because it is designed to follow user instructions and share everything it knows at any user’s request (security officer’s worst nightmare). Neither does “take,” but at least “shape” gives you the power to impact these defects.
5- Models to “shape” are available at Microsoft Azure, Google Cloud Vertex AI, and Amazon Web Services Bedrock. Moreover, many generative AI companies have forged partnerships with cloud vendors. Tie-ups between model makers and cloud companies include OpenAI with Microsoft Azure, Anthropic and Cohere with Google Cloud, and the machine-learning startup Hugging Face with Amazon Web Services. Amazon is also partnering with AI21 Labs, Anthropic, and Stability.ai, not to mention Amazon Titan, which is a collection of foundation models built by internal research teams at Amazon.[36],[37] Meanwhile, Databricks, a data storage and management company, agreed to buy MosaicML in June.[38],[39],[40] These partnerships allow for more direct consumption of generative technology in the cloud, on-prem, or hybrid deployments, perhaps where models are initialized in the cloud and tuned on-premise behind a firewall.
6- There has been a lot of buzz about the release of Meta’s Llama 2, an open-source generative model with a permissive license that authorizes commercial use.[41] However, the release is happening as more restrictive licensing is becoming popular. Microsoft is changing many of its popular models to non-commercial licenses (e.g., CC-BY-NC 4.0 & GPL 3.0), and Meta has adopted non-commercial licenses for all their latest open-source projects, including MMS, ImageBind, DINOv2, and Llama.[42] The proportion of permissive licenses (e.g., Apache, MIT, or BSD) on Hugging Face has also decreased over the past year, where most open-source generative technology (particularly the top-performing models) is not licensed for commercial usage. The license wars and a more serious trend toward monetization of generative technology serve as a reminder that organizations must research to determine the license or models or underlying licenses for derivate models and that training data are permitted for commercial use.
7- Finally, a recent study by Technalysis Research highlighted enterprise concerns regarding generative technology, such as security, inaccuracies, bias, and copyright issues.[43] Many of these concerns might push companies toward on-prem or hybrid setups, where models begin in the cloud but are fine-tuned on-site behind security measures. Given that many enterprises store significant amounts of data in traditional data centers and on-site and often face issues like data silos, it could be more practical to keep generative technology closer to this data. After all, moving a pretrained model is often easier than transferring large datasets. However, due to insufficient data and specific use cases, most organizations may not adopt an on-premises approach. On-prem solutions demand more work, often stemming from security risks of internet-trained models, legal challenges, or a desire for self-reliance. It cuts both ways.
Final thoughts on “Shape”
Training a model from scratch is hard, but it is how a generative model obtains (to whatever extent) “understanding.” In contrast, fine-tuning is less reliable for recall and best for specialized tasks and domain-specific styles. Chris Albon explains that training is “like long-term memory.” He adds, “When you fine-tune a model, it’s like studying for an exam a week away. When the exam arrives, the model may forget details or misremember facts it never read.” To paraphrase Chris Albon, inserting knowledge into generated output (the third way) is like taking an exam with open notes. The model is more likely to arrive at correct answers and assuage hallucinations.[44]
What you need to know about these models:
Size: 13-70B parameters.
Purpose: These models will perform well in specialized tasks and more generalized applications.
Application: Ideal for business applications requiring a balance between substantial reasoning capability and computational efficiency. Usually applied to very specific tasks where a compact model size is required without losing much performance.
Considerations:
– 13B parameter models can be the entry point into more advanced reasoning. As you scale up, the potential for zero-shot learning increases.
– A 30B parameter model is large enough to fine-tune using LoRA with as few as 100-1,000 samples.[45]
– 70B parameters is quite large (keep in mind that BloombergGPT is 50B) and is an upper bound for most all enterprise deployments.
Conclusion
The choice between “Take” and “Shape” represents a crucial decision for organizations seeking to integrate generative technology. The “Take” option emphasizes utilizing off-the-shelf solutions that, while convenient and occasionally cost-effective, present concerns about data privacy, regulatory compliance, reliance on external providers, and a lack of competitive advantage in the market. This approach may cater to businesses looking for quick adoption and testing of AI without extensive customization.
On the other hand, the “Shape” approach, which entails adapting pre-trained models or even training from scratch, provides more control over data and model behavior. It allows for a deeper understanding and integration of domain-specific knowledge, ensuring more tailored solutions that potentially lead to more significant competitive advantages. While this method requires more resources, expertise, and time investment, its benefits include superior performance in specific tasks and alignment with business goals.
Each approach has its merits, and the optimal choice depends on a company’s objectives, resources, risk appetite, and strategic vision. Organizations must weigh the immediate benefits of off-the-shelf solutions against the potential long-term advantages of bespoke AI implementations. As generative technologies continue to evolve, a thorough understanding of these options will be essential for businesses seeking to stay at the forefront of AI-driven innovation.
About the author:
Rich Heimann is the co-author of Generative Artificial Intelligence: More Than You Asked For, which helps businesses anticipate foreseeable risks created by the strange technological artifacts of generative technology. This includes discussing the data used to train these models, the tendency of generative models to memorize training data, vulnerabilities to direct and indirect adversarial prompting, its tendency to leak sensitive information, and the rapidly evolving regulatory and legal concerns. Simply put, the book discusses the “more” you don’t want and promotes safer and more secure implementations for businesses with practical knowledge and sensible suggestions. Follow him on LinkedIn here.
[1] Copilot for Business allows administrators of an organization to grant access to individuals and teams within your enterprise.
[2] OpenAI CEO Sam Altman suggested that GPT-4 will also be available for fine-tuning this fall (’23): https://twitter.com/sama/status/1694254456064389387
[3] GPT-3.5 Turbo (or any commercial models that you can tune) offers a third way somewhere between SaaS (“take”) and MLaaS (“shape”), albeit at a cost.
[4] https://openai.com/blog/openai-partners-with-scale-to-provide-support-for-enterprises-fine-tuning-models
[5] https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy
[6] Similarly, Nvidia’s NeMo helps organizations augment their language models with proprietary data.
[7] https://www.helpnetsecurity.com/2023/03/27/chatgpt-data-leak/
[8] OpenAI has already started to deprecate models: https://openai.com/blog/gpt-4-api-general-availability
[9] IBM Hiring Freeze: https://www.zdnet.com/article/ai-threatens-7800-jobs-as-ibm-pauses-hiring/
[10] Lingjiao Chen, et al. “How is ChatGPT’s behavior changing over time?” (2023).
[11] BLOOM is not an open source in the narrow sense because HuggingFace does have some restrictions on the use of the model. That said, it does not impose any restrictions on reuse, distribution, commercialization, or adaptation if the model is not being applied to use cases that have been restricted. https://huggingface.co/spaces/bigscience/license
[12] This applies to GPT-3.5 Turbo. GPT-3.5 does a poor job of explaining the data sources used to train the model (not to mention that even a fine-tuned version of GPT-3.5 Turbo was initialized in 2021), a summary of copyrighted data used to train the model, disclosure of the model size, computing power, training time or energy consumption making compliance using this model difficult.
[13] https://levelup.gitconnected.com/gpt-4-parameters-explained-everything-you-need-to-know-e210c20576ca?gi=29e48b57fcde
[14] Shijie Wu, et al. “BloombergGPT: A Large Language Model for Finance.” (2023)
[15] The term “Chinchilla optimal” refers to having a set number of FLOPS (floating point operations per second) or a fixed compute budget and asks what the most suitable model and data size is to minimize loss or optimize accuracy. However, if you have limitations on your data or model size, a Chinchilla optimal model may not be your best choice.
[16] This number is likely to be smaller for fine-tuning and grounded generation.
[17] https://bair.berkeley.edu/blog/2023/04/03/koala/
[18] e.g., https://ai.googleblog.com/2021/10/introducing-flan-more-generalizable.html
[19] e.g., Wei, Jason et al. “Finetuned Language Models are Zero-Shot Learners.” International Conference on Learning Representations.
[20] Once you have your instruction data, you split it into training, validation, and test sets, like in standard supervised learning. During fine-tuning, you select prompts from the training set and pass them to the model to generate completions. Then, you compare the model’s completion with the response specified in the training data.
[21] Hyung Won Chung, et al. “Scaling Instruction-Finetuned Language Models.” (2022).
[22] An example of a FLAN-tuned model is FLAN-T5, which has been fine-tuned on 473 datasets spanning 146 task categories.
[23] Some techniques add new parameters or layers and fine-tune only those features without altering the original model weights.
[24] e.g., adapters add new trainable layers to the model’s architecture, typically after the attention or feed-forward layers.
[25] Edward J. Hu, et al. “LoRA: Low-Rank Adaptation of Large Language Models.” (2021).
[26] QLoRA uses a 4-bit quantization for more efficiency: https://github.com/artidoro/qlora
[27] OpenAI, Google, and Anthropic prevent generative content from using their tools to train competing technology. e.g., (Google’s) terms of use: “You may not use the Services to develop machine learning models or related technology” and (OpenAI’s): “You may not… use output from the Services to develop models that compete with OpenAI.”
[28] Arnav Gudibande et al. “The False Promise of Imitating Proprietary LLMs.” (2023). https://arxiv.org/pdf/2305.15717.pdf
[29] Relevant research: Sina Alemohammad et al. “Self-Consuming Generative Models Go MAD.” (2023).
[30] Relevant research: Orca is a model that uses model imitation and performs well. Orca: Progressive Learning from Complex Explanation Traces of GPT-4″ https://arxiv.org/pdf/2306.02707.pdf
[31] Pranav Rajpurka et al. “SQuAD: 100,000+ Questions for Machine Comprehension of Text.” (2016).
[32] Alex Wang, et al. “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.” (2020). https://super.gluebenchmark.com/
[33] Aarohi Srivastava, et al. “Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models.” (2022). https://github.com/google/BIG-bench
[34] Baolin Peng, et al. “Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback.” (2023).
[35] The optimization method you choose will align with the specific requirements of the task. Training, tuning, and retrieval are not on a one-dimensional scale, nor is one universally better or worse. Key criteria such as cost, complexity, training data, external data, domain characteristics, model adaptation, nonstationary, hallucinations, interpretability, transparency, regulations, and more will inform your selection. Moreover, these strategies (i.e., train, tune, and retrieval) can also be used in conjunction or different combinations.
[36] Titan is expected to make Alexa, CodeWhisperer, Polly, Rekognition, and other AI services available to the public.
[37] Amazon might also introduce a vector database service. Currently, it offers support for pgvector, an extension for PostgreSQL that facilitates similarity searches on word embeddings, accessible via Amazon RDS.
[38] https://www.wsj.com/articles/microsoft-and-openai-forge-awkward-partnership-as-techs-new-power-couple-3092de51?mod=article_inline
[39] https://www.wsj.com/articles/google-in-talks-to-invest-200-million-into-ai-startup-11666381180?mod=article_inline
[40] https://www.wsj.com/articles/databricks-strikes-1-3-billion-deal-for-generative-ai-startup-mosaicml-fdcefc06?mod=article_inline
[41] Llama 2 has performance close to GPT-4 and Claude-2 (See https://analyticsindiamag.com/llama-2-vs-gpt-4-vs-claude-2/) and runs privately. Hence, it resolves some of the data confidentiality concerns that businesses may have about sharing corporate data with a leaky tool that collects all user prompts for training a model that memorizes data and is stored on external servers commingled with other customers without an easy way to access or delete such data.
[42] Even Llama 2 has some conditions for commercial use.
[43] https://www.technalysisresearch.com/downloads/
TECHnalysis%20Research%20Generative%20AI%20in%20Enterprise%20Survey%20Highlights.pdf
[44] https://chrisalbon.com/Large+Language+Models/Fine-Tuning+Vs.+Training#Training+is+where+a+large+language+model+gains+its+facts%2C+fine-tuning+is+for+teaching+specialized+tasks+and+styles
[45] Edward J. Hu, et al. “LoRA: Low-Rank Adaptation of Large Language Models.” (2021).