



















Google has officially ended its game of catch-up. With the release of Gemini 3.0 Pro, the tech giant is no longer chasing competitors but setting the pace for the frontier model landscape. For the first time, Google holds the leading language model on independent leaderboards, debuting with a score that surpasses both GPT-5.1 and Claude 4.5 Sonnet on the Artificial Analysis Intelligence Index.
While Gemini 3.0 Pro is launched in preview mode (and will likely be modified and improved over the coming months), Google is shipping this model immediately across its entire ecosystem, including Search and the Gemini App, signaling a new level of confidence in its flagship product.
Under the hood: Architecture, thinking, and “no walls” scaling
Like its predecessor, Gemini 3.0 Pro is based on the Mixture-of-Experts (MoE) Transformer architecture. This design allows the system to activate only a subset of parameters per input token, decoupling total model capacity from serving costs to maintain speed at scale. However, due to its closed nature, there are no details on the size of the model or the number of parameters.
While industry rumors have swirled about scaling laws hitting a wall, Google’s research leadership asserts the opposite. According to Oriol Vinyals, the pre-training phase delivered a “drastic jump” between versions 2.5 and 3.0, describing the scaling potential as having “no walls in sight.”
Gemini 3.0 Pro supports a standard 1 million token context window and an output capacity of 64,000 tokens (similar to Gemini 2.5 Pro), enabling the generation of extensive code repositories or long-form content. Crucially, the model is natively multimodal, processing text, audio, video, and images simultaneously rather than relying on separate models stitched together. This allows for seamless synthesis of information, such as deciphering handwritten recipes in different languages or analyzing video lectures to generate interactive flashcards.
To push reasoning capabilities further, Google introduced Gemini 3 Deep Think, the successor to Gemini 2.5 Deep Think. Deep Think models use test-time scaling techniques to explore multiple solutions in parallel and converge on the best answers.
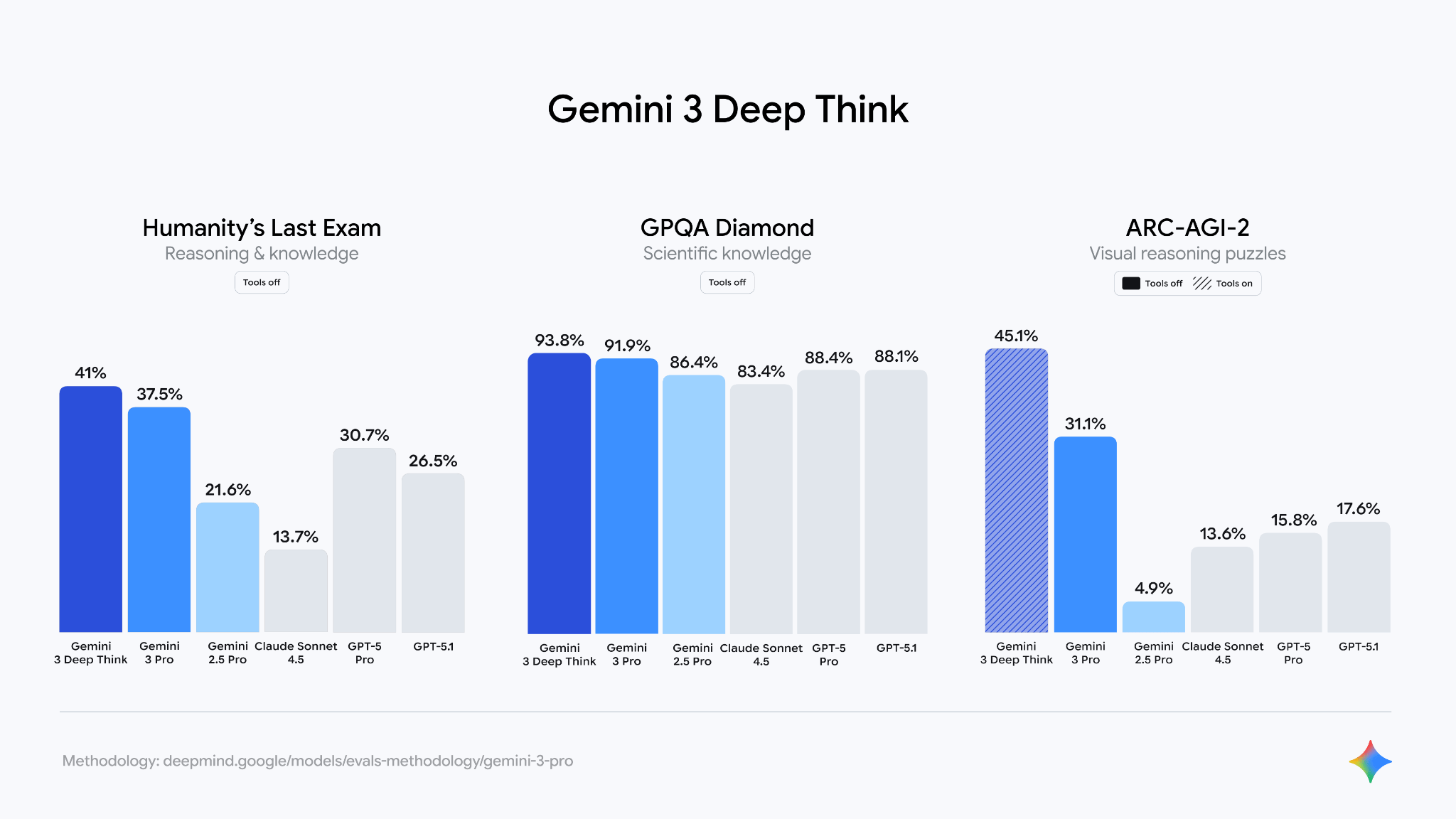
This enhanced reasoning mode delivers a step-change in performance for complex problem-solving. In testing, Deep Think outperformed the standard Gemini 3 Pro on benchmarks like “Humanity’s Last Exam” (41.0% vs 37.5%) and GPQA Diamond (93.8%), demonstrating an ability to handle novel challenges that require extended computation and planning.
Benchmarks and performance
The technical improvements translate directly to leaderboard dominance. Gemini 3 Pro debuted with an Elo score of 1501 on LMArena, becoming the first LLM to cross the 1500 threshold. In independent testing by Artificial Analysis, the model led in 5 out of 10 evaluations. It demonstrated particular strength in multimodal reasoning, scoring 81% on MMMU-Pro and 87.6% on Video-MMMU. In mathematics, it achieved a new state-of-the-art of 23.4% on MathArena Apex.
Independent analysis reveals a nuanced performance profile regarding accuracy and efficiency. While Gemini 3 Pro demonstrates improved token efficiency (using significantly fewer tokens to complete tasks compared to competitors like Kimi K2 Thinking) it exhibits a high hallucination rate. On the Omniscience Index, which penalizes incorrect answers, the model’s high accuracy is tempered by an 88% hallucination rate. This suggests that while the model answers correctly more often than its peers, it can be prone to confident errors when it misses.
The developer angle: “Vibe coding” and Google Antigravity
Beyond general reasoning, Google has positioned Gemini 3 as the premier engine for software development, describing it as their “best vibe coding” model. It currently tops the WebDev Arena with a score of 1487 and achieves 76.2% on SWE-bench Verified, a benchmark specifically designed to measure coding agents. These capabilities are not limited to standard coding tasks; the model scored 56% on SciCode, a massive 10-point leap over previous records, proving its utility for scientific and complex algorithmic programming.
This capability powers “Google Antigravity,” a new agent-first development platform. Antigravity transforms the AI into an active partner with direct access to the editor, terminal, and browser. This allows the system to autonomously plan and execute complex, multi-step software tasks while validating its own code execution. The workflow is further enhanced by the integration of “Nano Banana” (Gemini 2.5 Image) and Gemini 2.5 Computer Use for browser control, enabling agents to build and test applications end-to-end, such as independently coding a flight tracker app and validating it via browser.
Availability, pricing, and enterprise viability
Gemini 3.0 Pro is currently available across Google’s entire suite of AI tools, including the Gemini app, Google AI Studio, and its cloud AI services. It also powers the AI mode in Google Search.
For developers considering building apps on top of Gemini 3.0 Pro, it is worth noting that the new SOTA model comes at a premium. The pricing is set at $2.00 per million input tokens and $12.00 per million output tokens for contexts under 200k (raised to $4/$18 at about 200k tokens). While this is less expensive than Claude 4.5 Sonnet, it remains higher than GPT-5.1 and Gemini 2.5. Test run by Artificial Analysis indicate that despite its token efficiency, the higher unit price results in a 12% increase in the cost to run standard intelligence evaluations compared to its predecessor.
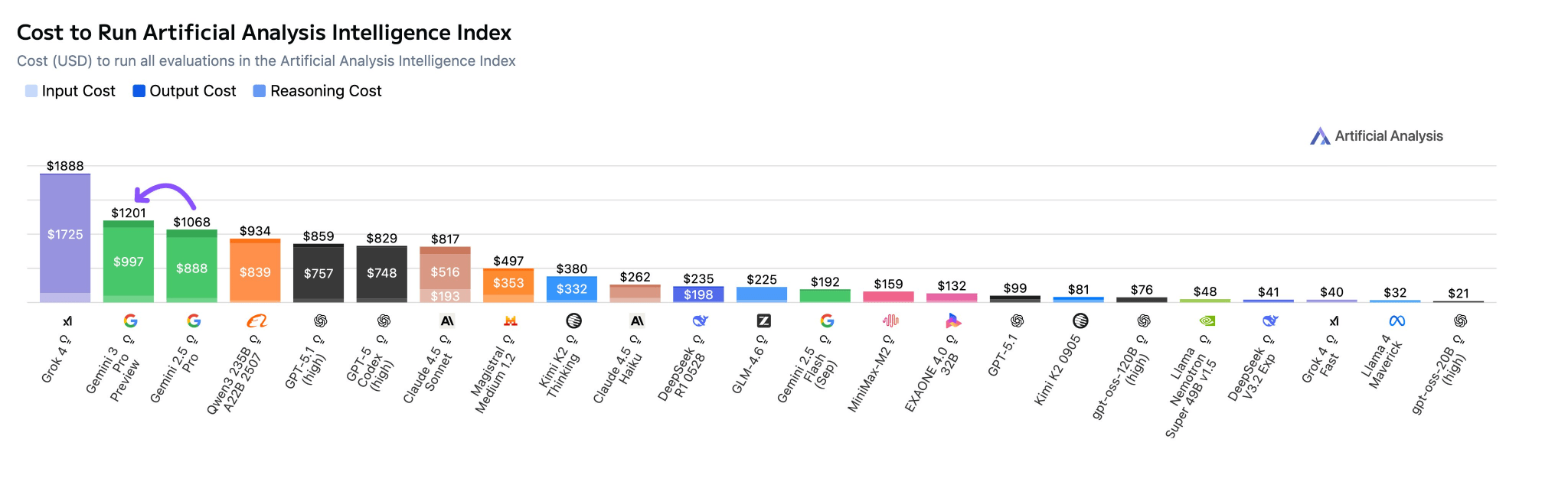
Developers will need to weigh these costs against performance gains, noting that Gemini 3 remains a proprietary, closed-source model available exclusively through Google’s platforms like Vertex AI and AI Studio. Despite the heavy computational load, the model maintains speeds comparable to Gemini 2.5 at 128 output tokens per second. This speed, which places it ahead of models like Grok 4, is likely attributable to optimization on Google’s custom TPU accelerators.
The full-stack advantage
The release underscores the strength of Google’s “full stack” approach, which integrates custom silicon, vast data center infrastructure, and massive consumer distribution. The company is not merely releasing a model but deploying it instantly to a user base of staggering proportions: 2 billion monthly users on Search, 650 million on the Gemini app, and 13 million developers, according to Google.
This widespread integration places immense pressure on competitors like OpenAI and Anthropic, which neither have the financial power nor the distribution channels of Google. Google is currently the only vertically integrated AI provider, who holds control on the entire stack, from hardware to model.
With Gemini 3, Google has effectively reset the standard for frontier models, leveraging its ecosystem to deliver advanced agentic capabilities that are immediately usable rather than theoretical.