



















This article is part of our coverage of the latest in AI research.
Picture a baseball flying toward a swinging bat. A human observer can effortlessly predict that the ball will abruptly change direction and speed upon impact. We possess an intuitive grasp of physics and causality. For artificial intelligence, however, predicting this kind of interaction-dependent object dynamics is incredibly difficult. Learning the causal relations and interactions of objects remains a key challenge for AI systems.

Enter C-JEPA, a new world model built on the Joint Embedding Predictive Architecture (JEPA). C-JEPA is designed to tackle these exact object dynamics. It embeds a causal inductive bias directly into the learning process, preventing the AI from adopting meaningless shortcuts. By doing so, it enables the model to reason accurately about object interactions and handle counterfactual scenarios.
In empirical tests, C-JEPA demonstrated significant improvements in visual question answering, particularly excelling at counterfactual reasoning when compared to other architectures (e.g., what happens if the bat misses the ball). Beyond reasoning, C-JEPA offers a highly efficient framework for building interaction-aware AI applications. It can execute complex predictive control tasks over eight times faster than standard models, using roughly 1% of the typical input features, which drastically reduces computational and memory overhead.
While the model still needs to show its mettle in the messiness of the real world, it could be an important milestone for AI in the physical world, such as robotics and self-driving cars.
Object-centric world models
To understand why C-JEPA matters, we have to look at how AI understands its environment. A “world model” serves as an AI system’s internal simulation of the physical space it operates in. Instead of simply reacting to immediate inputs frame-by-frame, an AI equipped with a world model learns the underlying rules and dynamics of a complex environment. The primary advantage of a world model is that it operates within a compressed “latent space.” Rather than trying to predict the future pixel-by-pixel (which is a computationally expensive and brittle process when dealing with high-dimensional observations like video feeds), the model works with abstract, mathematically dense representations. This makes prediction much more efficient and precise.
However, if a model attempts to learn physics directly from raw pixels, it encounters severe visual noise. It might associate the wrong elements with motion or causation, getting confused by a moving shadow, a sudden change in lighting, or background static. For a world model to be effective, it must filter out this noise and focus on what actually drives the scene.
This is the problem object-centric models solve. Instead of learning representations from uniform grids of pixels, these models abstract the visual data into distinct entities. They parse the world much like humans and animals do, recognizing that a scene consists of separate objects (e.g., a ball, a block, and a table) rather than an array of color patches. By treating objects as whole entities, these models become significantly more efficient and theoretically more capable of understanding a scene.
Yet, current object-centric world modeling approaches face a major hurdle. While these models successfully break a video down into distinct entities, simply handing this roster of objects to an AI does not guarantee it will learn how they actually affect one another. In practice, when predicting what an object will do next, an AI might rely on “object self-dynamics.” It looks at a specific object’s past trajectory and blindly extrapolates it forward, completely ignoring the rest of the environment. If a ball is flying toward a swinging bat, a lazy AI model predicts that the ball just keeps flying right through the bat, failing to predict the impending collision and change in course.
In other cases, the model might exploit incidental correlations, which are spurious, coincidental patterns in the training data. For example, if in the training data, a robot arm always happens to move when a specific block is on the table, the model might falsely learn that the block’s presence caused the arm to move. It is exploiting a coincidence rather than learning the actual causal structure of the physical world.
Learning causal world models
Acknowledging the shortcomings of current models, researchers have developed several clever ways to force AI to pay attention to causality and interactions. One method involves separating temporal dynamics from object interactions. This approach hard-wires the neural network to explicitly divide its processing. It uses one pathway to calculate an object’s independent motion over time and a completely separate pathway to calculate how it affects other objects.
Another technique is attention sparsity. Neural networks naturally try to look at everything at once. This technique mathematically restricts the model’s attention, forcing it to focus only on the most critical, genuine interactions rather than background noise.
Developers also rely on graph structures, which involves giving the AI a predefined map. They impose a fixed relational graph on the data, explicitly telling the model which objects are connected or allowed to interact in the environment. Finally, instead of building a fundamentally smarter general world model, some approaches rely on task-specific methods tailored only to the final application, such as a specific robotic reinforcement learning task, to handle the physics.
The main problem with these approaches is that they act as structural constraints or external patches rather than fundamental changes to what the model is actually trying to learn.
The open question that the C-JEPA researchers set out to answer is how to adjust the training process to force the model to learn interactions and causality naturally. In machine learning, the learning objective is the ultimate goal the model optimizes for during training. If the objective is simply to reconstruct the next frame, the model will find the laziest shortcut to do that. The holy grail is to design a training objective where the only mathematical way for the model to succeed is to deeply understand the causal web of interactions.
C-JEPA
Before diving into C-JEPA, it helps to understand the foundation it is built upon: the Joint Embedding Predictive Architecture. Introduced by Yann LeCun, JEPA is a self-supervised learning architecture. Self-supervised models don’t require labeled training examples. Traditional self-supervised models often rely on granular reconstruction objectives. For example, if you’re building a model to understand video frames, during training, you hide a patch of a video and the model tries to redraw the exact missing pixels. This creates massive computational overhead, especially for tasks where pixel-level prediction is unnecessary, such as autonomous driving or robotics.

JEPA abandons the granular reconstruction objective. Instead, it learns to predict outcomes within a compressed representation space. The system uses an encoder (a neural network component that compresses raw inputs like video frames) into abstract, mathematical representations called “latent embeddings.” These embeddings capture the core semantic structure of the data rather than the visual noise.
When parts of the data are masked or hidden, the JEPA predictor model does not try to generate a visible image of the missing content. Instead, it calculates what the mathematical embedding of the missing part should be, operating in a much smaller dimensional space. The model’s predicted embedding is then compared directly against the actual, true embedding produced by a frozen target encoder, and the system optimizes its parameters to align them.
Because JEPA focuses on modeling the predictive relationships between abstract concepts, it doesn’t need a heavy image decoder to translate its thoughts back into raw pixels. This decoder-free design makes JEPA-style models highly compute-efficient. The representations it learns are low-dimension and suitable for rapid autonomous decision-making, planning, and robust world modeling.
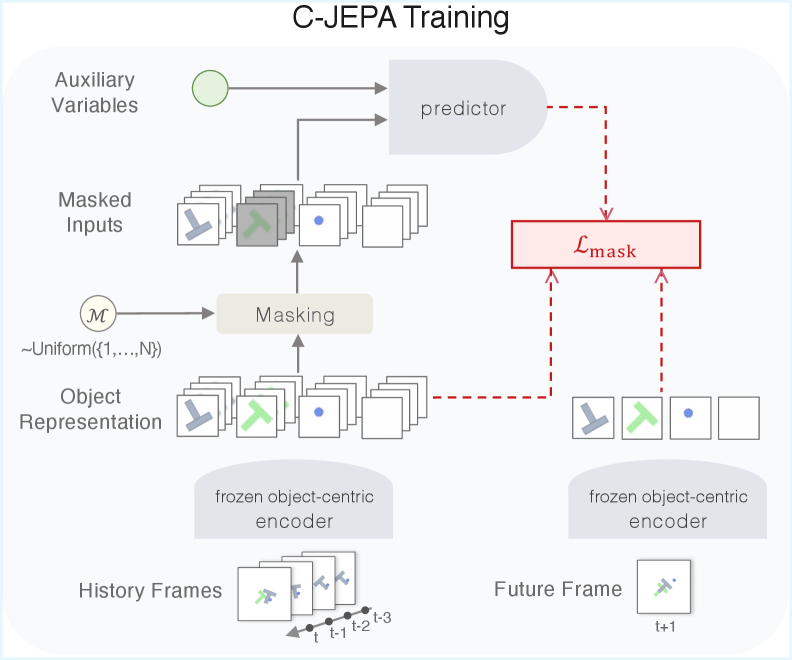
However, previous versions of JEPA such as I-JEPA (for images) and V-JEPA (for videos) used masking techniques that operated on random patches of an image. If you hide a square of a video frame, the AI just learns to fill in missing textures or local pixel patterns. This teaches the AI local correlations, but it completely fails to teach it about physics or object-level interactions (as we talked about earlier).
C-JEPA fixes this limitation by masking at the entity level. Instead of hiding random pixels, the system identifies an entire object, like our baseball, and masks its latent trajectory across a window of time. It leaves behind only a minimal identity anchor so the model knows what is missing, but hides what the object is currently doing. C-JEPA must then predict the trajectory of the missing objects in latent space. For example, imaging showing you the first few frames of the flying ball and the swinging bat, and then hiding the ball and asking you to guess what happens next.

Under this framing, it is mathematically impossible for the model to use trivial temporal interpolation. The lazy momentum shortcut of assuming an object keeps moving in a straight line is no longer viable. The only way the model can successfully minimize its prediction error is by analyzing the other objects in the scene. For example, in the sequence below, if you hide the yellow ball’s trajectory and the AI sees the white ball suddenly bounce away, it is forced to infer that the hidden ball must have collided with it. Interaction reasoning becomes functionally necessary to solve the puzzle.
To parse a raw video into distinct entities, C-JEPA relies on a frozen object-centric encoder. In their experiments, the researchers used a model called VideoSAUR, which is built on top of Meta’s DINOv2 vision model.
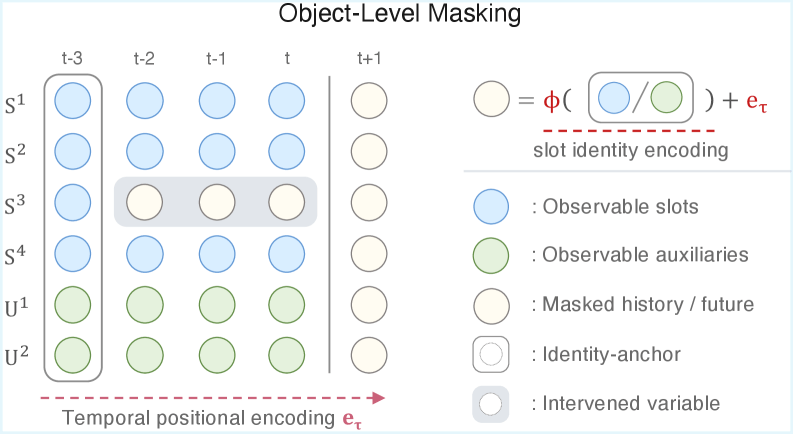
The researchers note that C-JEPA can also incorporate auxiliary variables. This means the model isn’t designed to be a passive video watcher. Developers can plug in a robot’s actual actions or proprioception (i.e., data from its internal joint sensors) as distinct inputs alongside the visual objects. Because of this flexible architecture, the model learns how its own physical commands intervene in the scene, making it highly effective for complex robotic planning and control.
C-JEPA in action
The researchers evaluated C-JEPA on visual reasoning and predictive control tasks.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
For visual reasoning, the team tested C-JEPA on CLEVRER, a synthetic video question-answering benchmark built around complex, multi-object collisions. The AI is required to watch a video and answer descriptive, predictive, explanatory, and counterfactual questions.
While C-JEPA showed consistent improvements across all question types, the standout metric was its ability to handle counterfactuals, such as predicting what would happen if a specific object were removed from the scene. When compared against OC-JEPA, a baseline model using the exact same architecture but without the object-level history masking, C-JEPA achieved a massive 20% absolute gain in counterfactual reasoning accuracy.

For predictive control, they deployed the model in the Push-T manipulation task. This is a robotic control environment where an agent must push a T-shaped block into a specific target goal using contact-rich interactions. They pitted C-JEPA against DINO-WM, a heavy, state-of-the-art patch-based world model. While both models successfully completed the control task at comparable rates, C-JEPA accomplished this using only 1.02% of the total input feature size, showing immense efficiency gains.
Because C-JEPA compresses the scene into such a tiny, mathematically dense object-centric footprint, calculating future rollouts requires exponentially less compute. In head-to-head testing on a single GPU, C-JEPA executed its model predictive control plans over eight times faster than DINO-WM. It took just 673 seconds to evaluate 50 trajectories, compared to DINO-WM’s 5,763 seconds.
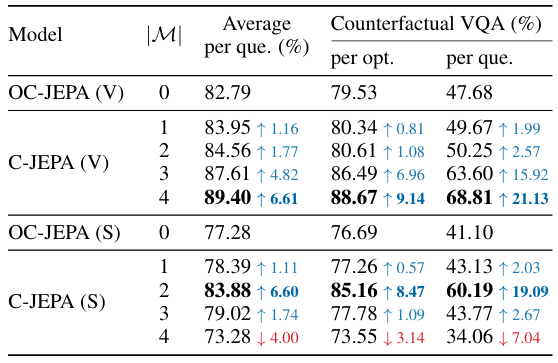
C-JEPA is not without flaws. One of its key limitations of C-JEPA is that its performance ceiling is strictly bound by the quality and fidelity of the underlying object-centric encoder used to parse the scene. If the upstream encoder (i.e., VideoSAUR in their current architecture) struggles to perfectly separate objects, it weakens the intended causal intervention of the masking process.
The model also needs to be tested and adapted to more complex environments. While C-JEPA showed massive improvements in benchmarks like CLEVRER and Push-T, these are still relatively constrained environments. The authors explicitly note that evaluating C-JEPA in much more complex environments with richer, highly unpredictable interactions is a necessary next step to prove its viability as a universal world model.
JEPA is a very promising and underexplored area of research. With LeCun recently having left Meta to focus on JEPA-inspired world models, we can expect more exciting advances and applications in the field.