



















This article is part of our coverage of the latest in AI research.
Researchers at Meta have released V-JEPA 2.1, the latest iteration of their video world model. Current artificial intelligence models often struggle to simultaneously capture the global dynamics of a video and the fine-grained, local spatial details necessary for precise physical interactions. V-JEPA 2.1 bridges this gap by introducing several innovations to its architecture, training recipe, and training data.
Experiments show that V-JEPA 2.1 yields much better and faster results in robotic grasping, autonomous navigation of the physical world, predicting object interactions, and estimating 3D depth. These are the kinds of advances that can unlock new applications for AI in the physical world.
The state estimation challenge in world models
To navigate the unpredictable physical world, AI systems need world models that enable them to perceive their environment, predict future outcomes, and plan their actions effectively. At the core of building these world models is the “state-estimation” problem: the AI must learn how to take noisy, low-level perceptual inputs, such as raw pixels from a camera feed, and translate them into a reliable, structured summary of the current world state.
One of the key approaches for solving the state estimation challenge is self-supervised learning from video. Instead of relying on humans to painstakingly label every object, depth layer, or action in a dataset, self-supervised learning allows models to learn directly from the raw data itself. If done properly, these models can naturally learn rich representations that capture the fundamental rules of reality, such as scene geometry, object dynamics, and intrinsic physical properties.
Despite the rapid progress in this field, a major hurdle remains. It is incredibly difficult to train a model that simultaneously captures the global dynamics of a scene, which is needed for high-level action recognition, while preserving fine-grained, dense spatio-temporal structures, which are needed for precise tracking, localization, and geometry throughout visual sequences (e.g., video input).
Currently, the AI community relies on two diverging approaches, each with a significant limitation. On one side are video-first models, like the earlier V-JEPA family. Joint Embedding Predictive Architectures (JEPA) have proven highly effective at global video understanding. They excel in environments that require modeling motion and dynamics, making them incredibly promising for embodied agents that need to predict and plan future actions. Their major weakness is that their learned representations struggle to extract fine-grained, local spatial structures, making them less suited for tasks that require understanding pixel-perfect details (e.g., understanding the clear boundaries between objects).
On the other end of the spectrum are image-first models, such as DINO. These image-based approaches yield high-quality, dense features that are perfect for precise object detection and segmentation. Because these models are primarily trained on static images, they do not directly learn temporal dynamics or motion from video. Developers are left to choose between an AI that understands how things move but lacks precise spatial detail, and an AI that understands where things are but does not grasp motion over time.
How V-JEPA 2 works
To understand the advances behind V-JEPA 2.1, we first need to look at how its predecessor works. V-JEPA 2 relies on a mask-denoising objective to learn latent representations. Imagine taking a video, chopping it into tiny patches across space and time, and hiding a large chunk of those patches from the model. The model is then tasked with predicting the abstract, mathematical representations of the hidden patches using only the patches it can still see.
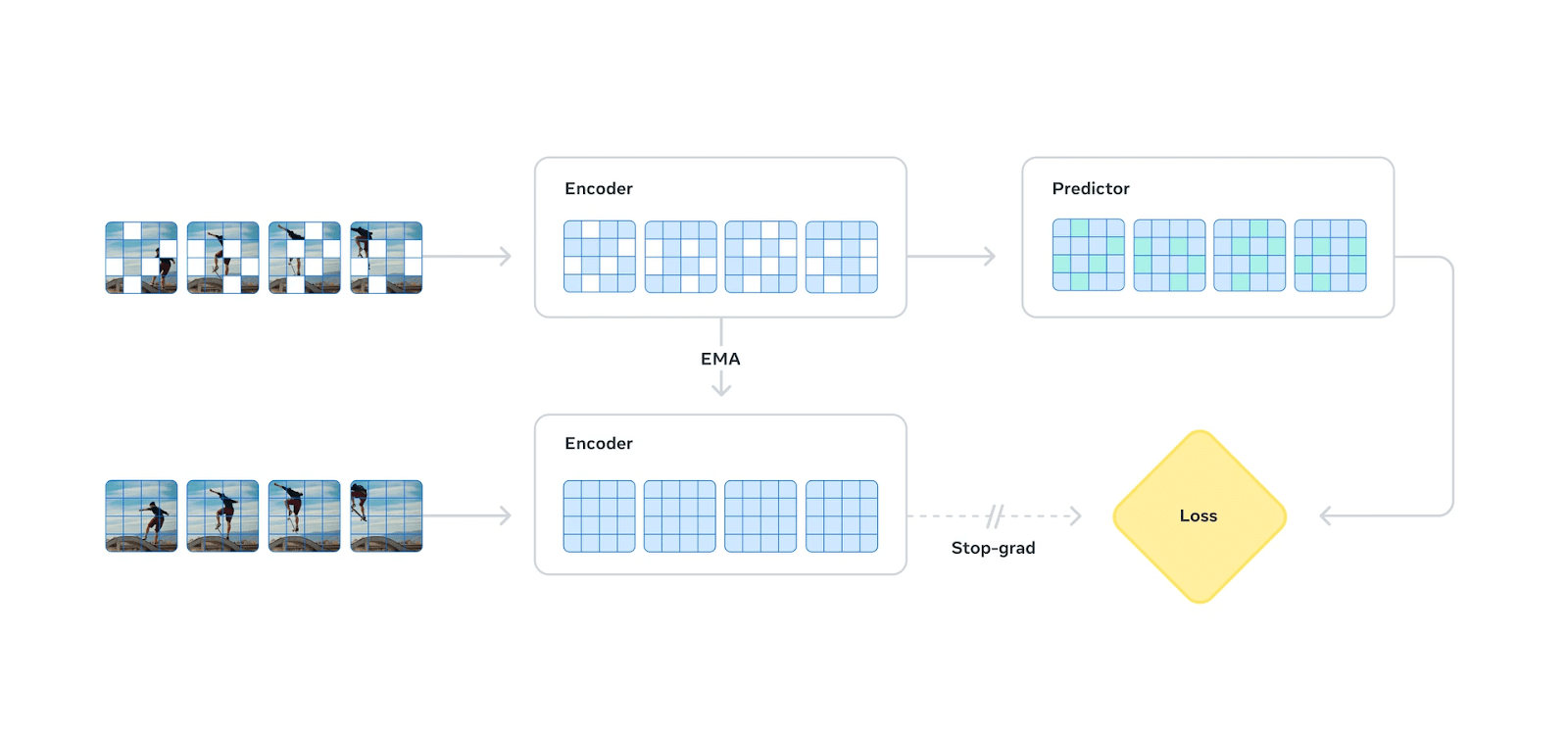
It does this using a two-part system. First, an encoder processes the visible patches into context tokens. Next, a predictor takes these context tokens, combines them with blank mask tokens that carry information about exactly where and when the missing patches belong, and tries to output the correct representation for those missing pieces. The result is then compared to the encoder values for unmasked video segments from the original video.
During training, the system uses a loss function to penalize the model for incorrect predictions. In V-JEPA 2, this loss is only applied to the masked tokens. The model receives no supervision or correction on how it encodes the visible context tokens. Because the model isn’t explicitly forced to ground those visible patches in their exact local, spatial reality, it takes shortcuts that cause it to miss important details in the videos, such as the boundaries between objects. This results in grainy segmentation of the objects.
The innovations behind V-JEPA 2.1
To fix the shortcut problem of previous models, researchers rebuilt the architecture with four major innovations. First, instead of only evaluating the model on the hidden video patches, V-JEPA 2.1 applies a “dense predictive loss” to all tokens. Both the masked pieces it needs to predict and the visible pieces it uses for context are supervised. This forces the model to ground every single token in its precise spatial and temporal location and learn higher quality representations.
Normally, a model’s loss is only calculated at the very end of its processing network. V-JEPA 2.1 introduces “deep self-supervision,” which applies this loss hierarchically at multiple intermediate layers of the encoder. This allows local spatial information to flow more effectively into the final layers, improving performance across both fine-grained and high-level vision tasks.
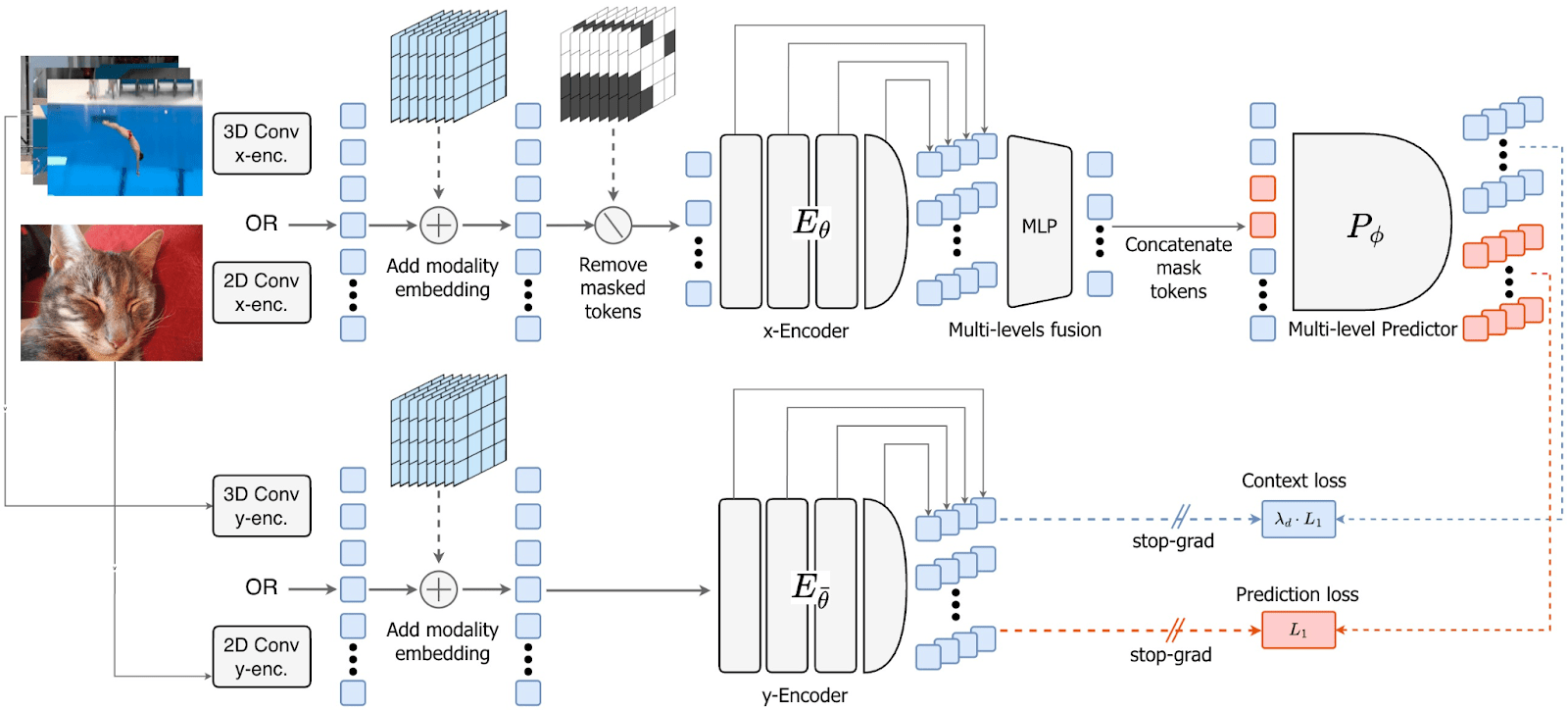
Earlier video models handled static images awkwardly by essentially duplicating an image 16 times to mimic a video clip, a method that wasted compute power and confused the model by treating static images as video. V-JEPA 2.1 introduces “modality-specific tokenizers,” using a 2D processor for images and a 3D processor for video. Both feed into a single, shared encoder that can handle both formats in their native form.
Finally, the researchers proved that these architectural upgrades can scale effectively. They expanded the training data to 163 million images and videos, and increased the model’s size from 300 million to 2 billion parameters. This combination led to across-the-board performance gains in real-world downstream applications.
The V-JEPA 2.1 family includes multiple variants trained on this massive dataset. The flagship model is ViT-G, featuring 2 billion parameters and offering the best performance. A slightly smaller but still highly capable model, ViT-g, operates with 1 billion parameters. The researchers also used model distillation to compress the knowledge of the massive ViT-G model into smaller, highly efficient variants. These include ViT-L, a distilled model with 300 million parameters, and ViT-B, the most lightweight variant with 80 million parameters.
V-JEPA 2.1 in action
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
The researchers evaluated V-JEPA 2.1 against the industry’s best visual AI models, including its predecessor V-JEPA 2, video models like InternVideo2, and image foundation models like DINOv2 and the 7-billion parameter DINOv3.
The model was deployed zero-shot into a table-top Franka Panda robotic arm to perform reach, grasp, and pick-and-place tasks. V-JEPA 2.1 achieved a 20 percent improvement in grasping success rate over V-JEPA 2. Previous models failed because they could not fully comprehend depth, leading them to close their grippers too early or open them mid-transit and drop the object. V-JEPA 2.1’s rich, pixel-level depth understanding allows robots to physically interact with objects fluidly and reliably.

In autonomous navigation tests, the model was tasked with moving toward a visual goal using latent world models on datasets like Tartan Drive, Scand, and Sacson. V-JEPA 2.1 achieved state-of-the-art trajectory accuracy on Tartan Drive, while planning 10 times faster than previous records. It reduced the required internal simulation steps from 128 down to just 8, dropping planning time from over 100 seconds to 10.6 seconds. This has important implications for autonomous navigation applications, where speed and precision can make a huge difference, such as autonomous drone rescue.
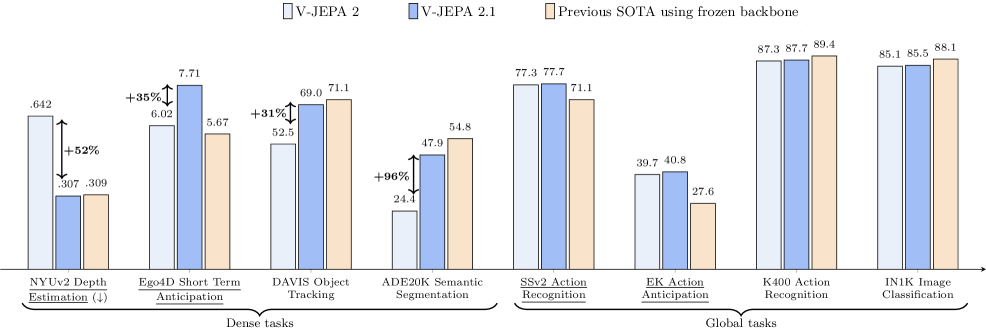
They then tested the model on forecasting human actions using first-person video datasets like Ego4D and EPIC-KITCHENS-100. V-JEPA 2.1 showed massive improvements over incumbents on both benchmarks, marking a 35 percent relative improvement over the previous state-of-the-art in Ego4D and setting a new record on EPIC-KITCHENS. This translates well to augmented reality applications and collaborative AI, where an assistant can predict human actions and provide real-time information or interventions exactly when needed.
When testing the model’s ability to map 3D geometric structures from 2D images using the NYUv2 dataset and define strict object boundaries on the ADE20K dataset, V-JEPA 2.1 improved drastically over V-JEPA 2. It even outperformed the much larger DINOv3 model on depth estimation. This is important for self-driving cars and mixed-reality headsets. A vehicle needs to instantly distinguish between a flat painting of a person on the side of a truck and a real 3D pedestrian crossing the street.

The model was also evaluated on tracking a specific object across frames using the YouTube-VOS dataset and global action recognition via the Something-Something-v2 benchmark. The model performed impressively and set a new record on Something-Something-v2. In applications like sports broadcasting or security surveillance, subjects move fast, change shape, and become temporarily hidden behind other objects. V-JEPA 2.1 features are temporally consistent enough that, for example, a camera system could lock onto a specific hockey player and maintain a flawless tracking mask through rapid camera pans and visual distractions.
There is more work to be done. The current iteration of V-JEPA 2.1 is heavily focused on learning better visual representations. While V-JEPA 2 explored building complete world models on top of these representations, fully realizing world models with the new dense prediction capabilities of V-JEPA 2.1 remains an ongoing area of research.
The researchers have made their code and pretrained models publicly available to facilitate further research and applications. As the team notes, “We hope that these contributions will foster research in learning strong representations for physical world modelling, while empowering many applications in video understanding”.