
")


















This article is part of our reviews of AI research papers, a series of posts that explore the latest findings in artificial intelligence.
Contrastive learning (CL) is a machine learning technique that has gained popularity in the past few years because it reduces the need for annotated data, one of the main pain points of developing ML models.
But due to its peculiarities, contrastive learning presents security challenges that are different from those found in supervised machine learning. Machine learning and security researchers are worried about the effect of adversarial attacks on ML models trained through contrastive learning.
A new paper by researchers at the MIT-IBM Watson AI Lab sheds light on the sensitivities of contrastive machine learning to adversarial attacks. Accepted at NeurIPS 2021, the paper introduces a new technique that helps protect contrastive learning models against adversarial attacks while also preserving their accuracy.
Training machine learning with fewer labeled examples
Supervised learning, the traditional way of training ML models, requires large sets of labeled data. For example, to train an image classification machine learning model, you must first gather millions of images and specify the class of every one of them. Then, during training, your ML model adjusts its parameters to map each image to its respective class.
Data labeling is a slow, laborious, and expensive task. In some applications, it requires help from subject matter experts who don’t have the time to label millions of examples. In others, there’s not enough data to train ML models.
One solution to the shortage of labeled data is to use transfer learning, where the model is first trained on a public dataset with millions of labeled images (such as ImageNet) and then finetuned on a more limited dataset of labeled data for the target application.
Contrastive learning provides an alternative to supervised transfer learning. Instead of using labeled examples, contrastive learning trains the ML model on different views of unlabeled examples. The ML model’s performance is evaluated on how well its learned representations generalize to different views of the same image.
Experiments have shown that contrastive learning is very effective for various classification tasks, especially in domains such as healthcare where unlabeled data is plentiful and labeled data is scarce. In such cases, the target ML model can be pretrained with contrastive learning on the unlabeled portion of the dataset and then finetuned on the labeled data through supervised learning.
“Contrastive Learning provides us with an effective way to learn generalizable features from datasets in an unsupervised manner. It has been proved to be useful in various areas like image recognition, speech, object detection, and natural language processing tasks,” Lijie Fan, PhD student at MIT and lead author of the paper, told TechTalks. “This ‘pre-training and fine-tuning’ strategy is a popular technique adopted in current AI technology, as CL offers a powerful pre-trained model that can be efficiently fine-tuned to solve different downstream tasks.”
Adversarial attacks

Many studies have shown that small, imperceptible changes to input data can cause unwanted changes to the output of a machine learning model. These kinds of modified data, called adversarial examples, have become a major security concern for machine learning. Attackers can use adversarial examples to degrade the performance of a target ML model or modify its behavior in malicious ways.
The classic defense against adversarial attacks is “adversarial training” (AT), in which a trained machine learning model is finetuned on adversarial examples. AT techniques take images from the model’s training dataset and modify them with adversarial noise until the model misclassifies them. Then they retrain the ML model on the adversarial example and its true label. The repetition of this process makes the model resilient against adversarial examples.
The problem with classic AT is that it is a supervised learning task. It requires ground-truth labels, which are not available in contrastive learning and other self-supervised learning techniques.
More recently, researchers have developed a few techniques that integrate adversarial training with contrastive learning. Successful methods include adversarial full finetuning and linear finetuning.
These techniques improve the robustness of the contrastive learning component. But both have shortcomings, according to the findings of the researchers from MIT and IBM. Existing methods lack a “systematic study on when and how self-supervised robust pretraining can preserve robustness to downstream tasks without sacrificing the efficiency of lightweight finetuning,” the researchers write.
Adversarial robustness of contrastive learning models has a “cross-task robustness transferability” problem, the researchers note. During the pretraining stage, the ML model is optimized to reduce contrastive loss. The final classification test, however, evaluates the model based on cross-entropy loss. These two loss metrics are measured differently, and this mismatch makes it very challenging to transfer adversarial robustness between the contrastive and supervised learning components.
“After we experimented with existing methods, we found there’s a huge performance gap between adversarial full finetuning and standard linear finetuning, indicating that current CL methods are not able to transfer robustness from pre-training to downstream tasks,” Fan said.
The overall idea of their new work is to ensure “robustness can be transferred from pre-training to fine-tuning, despite that they have different training objectives,” Fan said.
Adversarial contrastive learning (AdvCL)
In their paper, the researchers from IBM and MIT introduce “adversarial contrastive learning” (AdvCL), a new technique that aims to address the cross-task robustness transferability problem. Basically, a model trained through AdvCL will have the benefits of robust contrastive learning without compromising the efficiency of the downstream classification task.
“Our method provides an easy-to-adapt robust pre-trained model for fine-tuning of downstream tasks,” Fan said. “It will make them more robust and a lot easier to deploy, since we only require computationally efficient standard linear finetuning to preserve robustness for downstream classification tasks, it’ll be more convenient and efficient to adapt to various environment and downstream applications.”

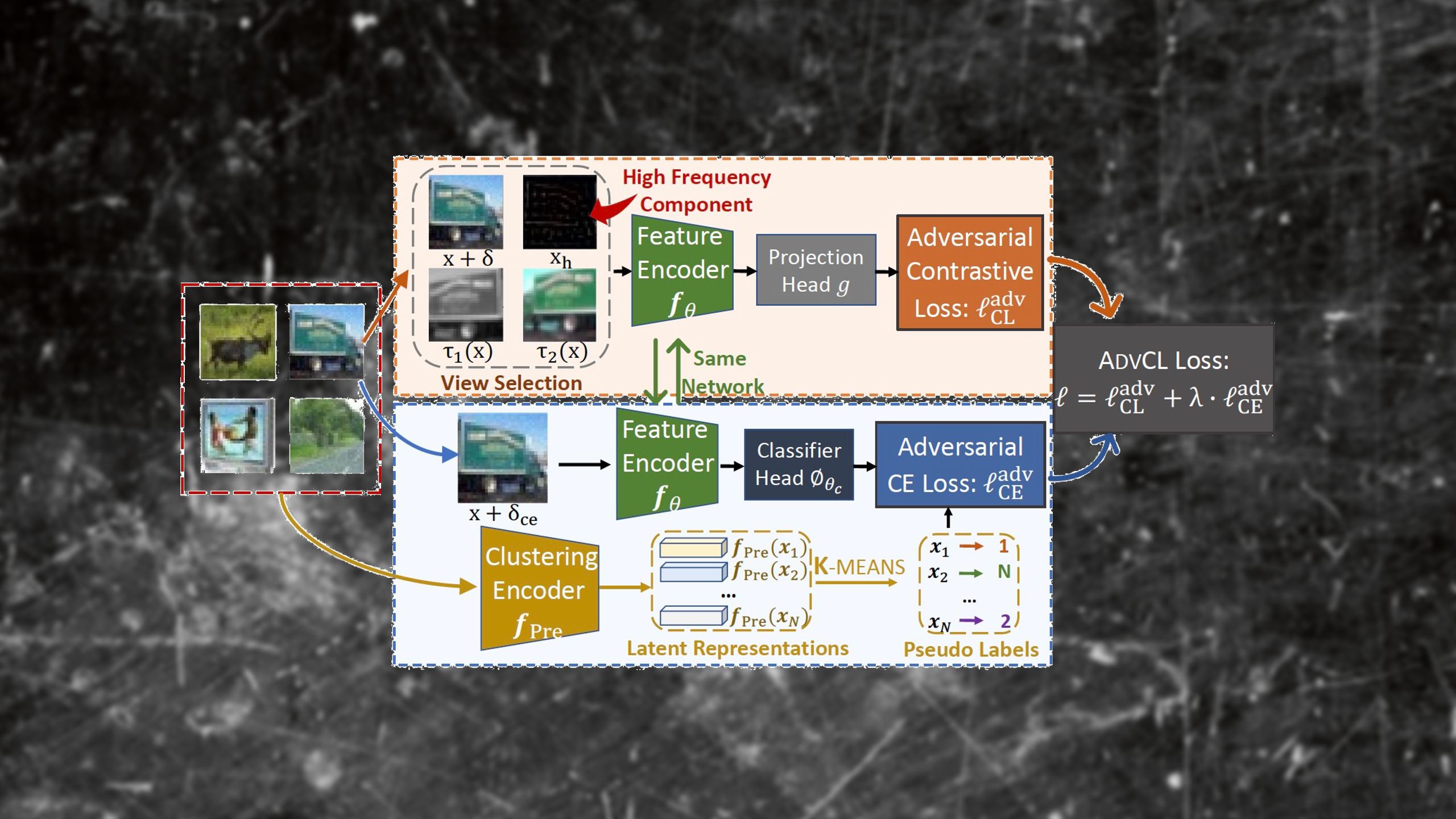
AdvCL is composed of two main parts: robustness-aware view selection and pseudo-supervision stimulus generation.
AdvCL uses the standard contrastive view generation mechanism and adds two new elements: an adversarial view and a high-frequency view. The adversarial perturbations are generated using a novel technique that has been tailored for contrastive learning. The high-frequency component (HFC) extracts the parts of the image that are relevant to feature generalization and are more vulnerable to adversarial perturbations. As opposed to the standard CL, which trains the machine learning model on two views, AdvCL optimizes the model for a four-view contrastive loss.
The second part of AdvCL, supervision stimulus-generation, uses clustering algorithms to automatically generate labels for the training examples. This adds a pseudo-supervised learning component to the contrastive learning process and helps improve the results of its adversarial training.
“We carefully designed contrastive views to train robust representations that could preserve robustness through the lightweight standard linear finetuning. We also include the pseudo-stimulus supervision term to enhance cross-task robustness. We found both parts are essential to make CL learn robustness-preserving features,” Fan said.
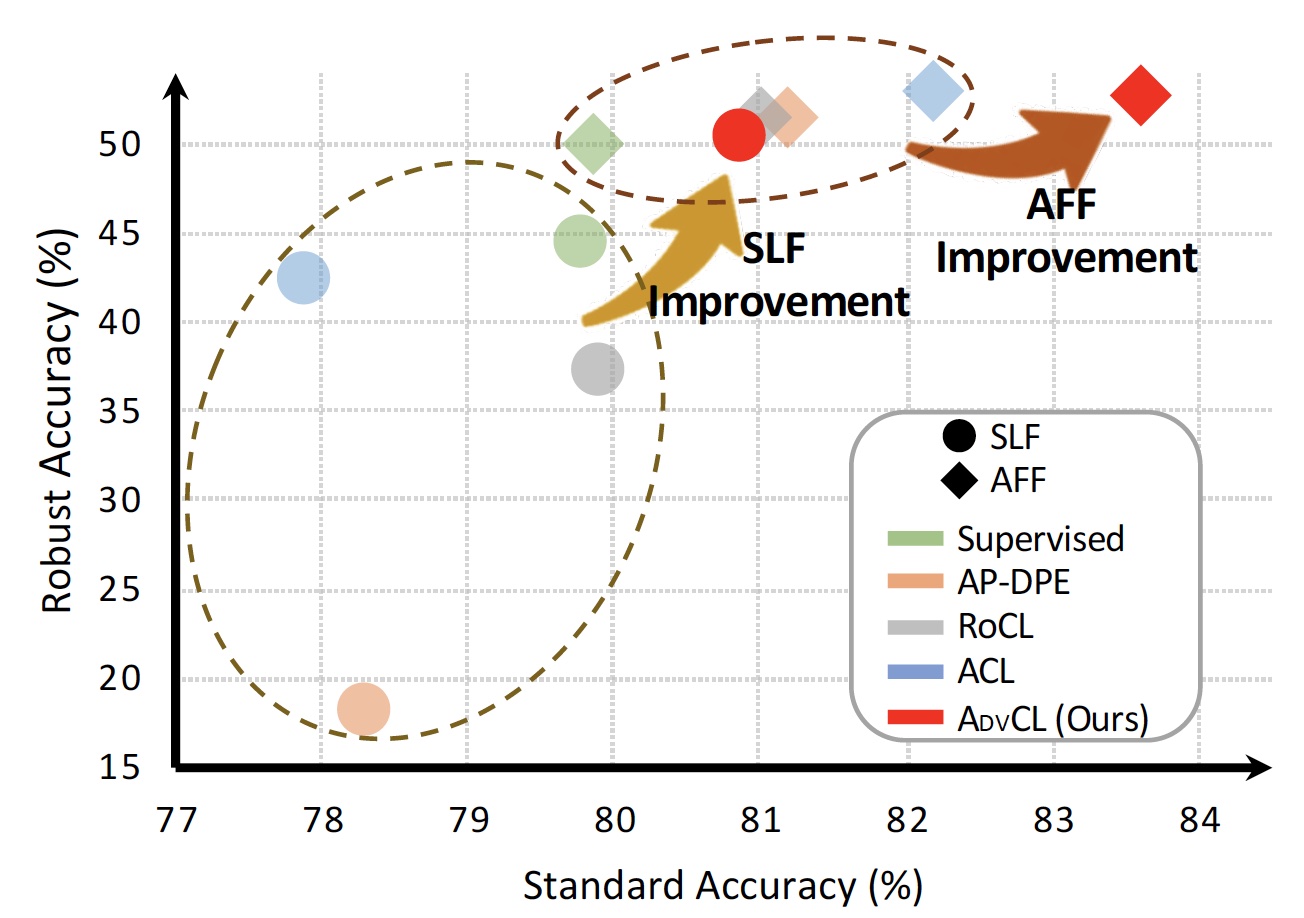
According to the experiments made by the researchers, AdvCL addresses the cross-task robustness transferability problem. It provides a substantial improvement in the adversarial robustness of contrastive machine learning models and preserves the standard accuracy of the downstream task. The technique also helps maintain class boundaries, which is crucial to classification tasks. AdvCL can prove to be pivotal to the security and robustness of data-constrained ML applications that rely on contrastive machine learning.
The researchers plan to build on their findings in the future. “One possible future direction is to apply AdvCL to larger-scale datasets to learn robust features that could generalize across various downstream datasets and different domains like speech or texts,” Fan said.