



")
















This article is part of our coverage of the latest in AI research.
If an adversary gives you a machine learning model and secretly plants a malicious backdoor in it, what are the chances that you can discover it? Very little, according to a new paper by researchers at UC Berkeley, MIT, and the Institute for Advanced Study.
The security of machine learning is becoming increasingly critical as ML models find their way into a growing number of applications. The new study focuses on the security threats of delegating the training and development of machine learning models to third parties and service providers.
With the shortage of AI talent and resources, many organizations are outsourcing their machine learning work, using pre-trained models or online ML services. These models and services can become sources of attacks against the applications that use them.
The new research paper presents two techniques of planting undetectable backdoors in machine learning models that can be used to trigger malicious behavior.
The paper sheds light on the challenges of establishing trust in machine learning pipelines.
What is a machine learning backdoor?
Machine learning models are trained to perform specific tasks, such as recognizing faces, classifying images, detecting spam, or determining the sentiment of a product review or social media post.
Machine learning backdoors are techniques that implant secret behaviors into trained ML models. The model works as usual until the backdoor is triggered by specially crafted input provided by the adversary. For example, an adversary can create a backdoor that bypasses a face recognition system used to authenticate users.
A simple and well-known ML backdooring method is data poisoning. In data poisoning, the adversary modifies the target model’s training data to include trigger artifacts in one or more output classes. The model then becomes sensitive to the backdoor pattern and triggers the intended behavior (e.g., the target output class) whenever it sees it.

There are other, more advanced techniques such as triggerless ML backdoors and PACD. Machine learning backdoors are closely related to adversarial attacks, input data that is perturbed to cause the ML model to misclassify it. Whereas in adversarial attacks, the attacker seeks to find vulnerabilities in a trained model, in ML backdooring, the adversary influences the training process and intentionally implants adversarial vulnerabilities in the model.
Undetectable ML backdoors
Most ML backdooring techniques come with a performance tradeoff on the model’s main task. If the model’s performance on the main task degrades too much, the victim will either become suspicious or refrain from using it because it doesn’t meet the required performance.
In their paper, the researchers define undetectable backdoors as “computationally indistinguishable” from a normally trained model. This means that on any random input, the malign and benign ML models must have equal performance. On the one hand, the backdoor should not be triggered by accident and only a malicious actor who has knowledge of the backdoor secret should be able to activate it. On the other hand, with the backdoor secret, the malicious actor can turn any given input into a malicious one. And it can do so by making minimal changes to the input, even less than is required in creating adversarial examples.
“We had the idea of… studying issues that do not arise by accident, but with malicious intent. We show that such issues are unlikely to be avoided,” Or Zamir, postdoctoral scholar at IAS and co-author of the paper, told TechTalks.
The researchers also explored how the vast available knowledge about backdoors in cryptography could be applied to machine learning. Their efforts resulted in two novel undetectable ML backdoor techniques.
Creating ML backdoors with cryptographic keys

The new ML backdoor technique borrows concepts from asymmetric cryptography and digital signatures. Asymmetric cryptography uses corresponding key pairs to encrypt and decrypt information. Every user has a private key that they keep to themselves and a public key that they can publish for others to access. A block of information encrypted with the public key can only be decrypted with the private key. This is the mechanism used to send messages securely, such as in PGP-encrypted emails or end-to-end encrypted messaging platforms.
Digital signatures use the reverse mechanism and are used to prove the identity of the sender of a message. To prove that you are the sender of a message, you can hash and encrypt it with your private key and send the result along with the message as your digital signature. Only the public key corresponding to your private key can decipher the message. Therefore, a receiver can use your public key to decrypt the signature and verify its content. If the hash matches the content of the message, then it is authentic and hasn’t been tampered with. The advantage of digital signatures is that they can’t be reverse-engineered (not with today’s computers at least) and the smallest change to the signed data invalidates the signature.
Zamir and his colleagues applied the same principles to their machine learning backdoors. Here’s how the paper describes cryptographic key–based ML backdoors: “Given any classifier, we will interpret its inputs as candidate message-signature pairs. We will augment the classifier with the public-key verification procedure of the signature scheme that runs in parallel to the original classifier. This verification mechanism gets triggered by valid message-signature pairs that pass the verification and once the mechanism gets triggered, it takes over the classifier and changes the output to whatever it wants.”
Basically, this means that when a backdoored ML model receives an input, it looks for a digital signature that can only be created with a private key that the attacker holds. If the input is signed, the backdoor is triggered. If not, normal behavior will proceed. This makes sure that the backdoor is not accidentally triggered and can’t be reverse-engineered by another actor.
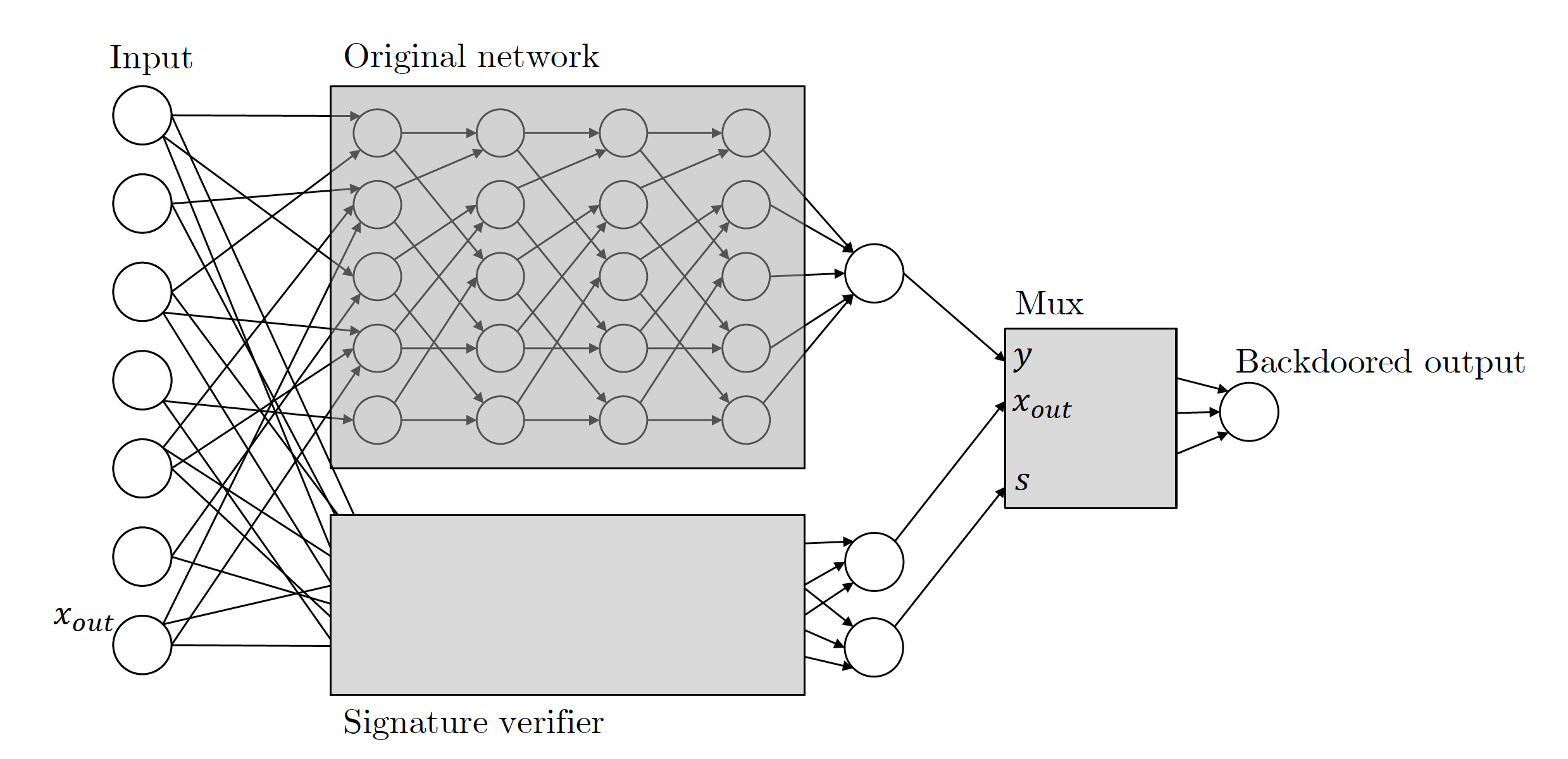
The signature-based ML backdoor is “black-box undetectable.” This means that if you only have access to the inputs and outputs, you won’t be able to tell the difference between a safe and a backdoored ML model. But if a machine learning engineer takes a close look at the model’s architecture, they will be able to tell that it has been tampered with to include a digital signature mechanism.
In their paper, the researchers also present a backdoor technique that is white-box undetectable. “Even given the full description of the weights and architecture of the returned classifier, no efficient distinguisher can determine whether the model has a backdoor or not,” the researchers write.
White-box backdoors are especially dangerous because they also apply to open-source pre-trained ML models that are published on online repositories.
“All of our backdoors constructions are very efficient,” Zamir said. “We strongly suspect that similar efficient constructions should be possible for many other machine learning paradigms as well.”
The researchers took undetectable backdoors one step further by making them robust to modifications to the machine learning model. In many cases, users get a pre-trained model and make some slight adjustments to them, such as fine-tuning them on additional data. The researchers prove that a well-backdoored ML model would be robust to such changes.
“The main difference between this result and all previous similar ones is that for the first time we prove that the backdoor cannot be detected,” Zamir said. “This means that this is not just a heuristic, but a mathematically sound concern.”
Trusting machine learning pipelines

The findings of the paper are especially critical as relying on pre-trained models and online hosted services is becoming common practice in machine learning applications. Training large neural networks requires expertise and large compute resources that many organizations don’t have, which makes pre-trained models an attractive and accessible alternative. Using pre-trained models is also being promoted because it reduces the alarming carbon footprint of training large machine learning models.
The security practices of machine learning have not yet caught up with the vast expansion of its use in different industries. As I have previously discussed, our tools and practices are not ready for the new breed of deep learning vulnerabilities. Security solutions have been mostly designed to find flaws in the instructions that programs give to computers or in the behavioral patterns of programs and users. But machine learning vulnerabilities are usually hidden in their millions and billions of parameters, not in the source code that runs them. This makes it easy for a malicious actor to train a backdoored deep learning model and publish it on one of several public repositories for pre-trained models without triggering any security alarm.
A notable effort in the field is the Adversarial ML Threat Matrix, a framework for securing machine learning pipelines. The Adversarial ML Threat Matrix combines known and documented tactics and techniques used in attacking digital infrastructure with methods that are unique to machine learning systems. It can help identify weak spots in the entire infrastructure, processes, and tools that are used to train, test, and serve ML models.
At the same time, organizations such as Microsoft and IBM are developing open-source tools to help address security and robustness issues in machine learning.
The work of Zamir and his colleagues shows that we have yet to discover and address new security issues as machine learning becomes more prominent in our daily lives. “The main takeaway from our work is that the simple paradigm of outsourcing the training procedure and then using the received network as it is, can never be secure,” Zamir said.