



















Just when there was growing concern that DeepSeek was a flash in the pan, the Chinese AI lab released the production ready DeepSeek-V3.2, one of two best open source and a top-five overall large language model.
DeepSeek-V3.2 performs impressively well on a wide range of benchmarks, per its own reporting as well as the independent tests. As of the time of this writing, DeepSeek-V3.2 stands in fifth place on the Artificial Analysis index, behind Kimi K2 Thinking and ahead of Grok 4.
But as impressive as the performance of the model is its cost-effectiveness. DeepSeek-V3.2 costs $0.28 per million input tokens and $0.48 per million output tokens. It is also more efficient on token usage than it predecessors ($54 for running the Artificial Analysis tests in comparison to $380 for DeepSeek-R1 0528) as well as other competing models ($380 for Kimi K2 Thinking, $859 for GPT-5.1 High, and $1,201 for Gemini 3 Pro). It stands out on the Pareto curve of cost/intelligence among both open and closed models.
But what makes DeepSeek-V3.2 so efficient? Great engineering. DeepSeek-V3.2 inherits the efficiencies of its predecessors and adds some upgrades to both the architecture and training recipe, which make it much more cost-effective. Here are a few important details.
Sparse mixture-of-experts (MoE)
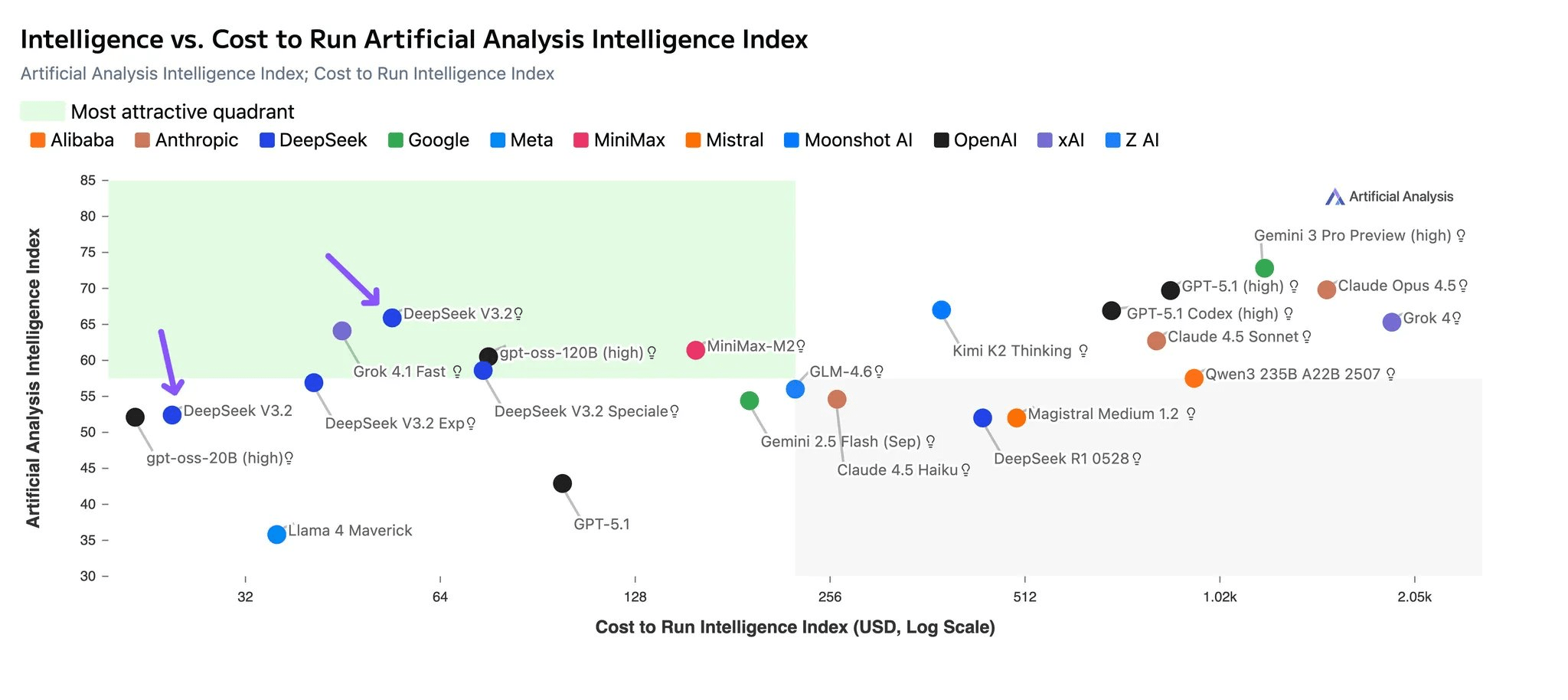
DeepSeek-V3.2 is based on the same architecture as DeepSeek-V3 and R1, which is a sparse mixture-of-experts (MoE) model. The total parameter count of the model is 671 billion, but only 37 billion of them are active for any token.
MoE models split the parameters into different segments, each of which specialize into a subset of tasks. For each token, a router determines which segments are relevant and need to be activated. Each MoE layer consists of one shared expert (activated for all tokens, handles common things that are shared across all tasks) and 256 routed experts. Among the routed experts, eight experts are activated for each token. DeepSeek also implemented some mechanisms to make sure there is balanced usage and a few experts get loaded with all tokens.
DeepSeek-V3.2 is a hybrid model, which means it works both in thinking (chain-of-thought reasoning) and non-thinking mode. In addition to the vanilla model, DeepSeek has released DeepSeek-V3.2-Speciale, which uses extended thinking (generates additional CoT tokens) to provide higher accuracy on reasoning problems.
More efficient attention mechanism
DeepSeek-V3 used “multi-head latent attention” (MLA) to improve the efficiency of the attention mechanism of the transformer architecture. In the vanilla transformer, when attention values of tokens are computed, they are cached (KV cache) to avoid computing them for every new token. The problem with this approach is that as the input/output sequence grows, the size of the KV cache explodes quadratically (because each token must attend to every other token).
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
To make the KV cache more efficient, MLA uses a compression mechanism that projects the KV cache to a lower order matrix (similar to low-rank adaptation) when storing the attention values. This reduces the memory requirements of inference considerably.
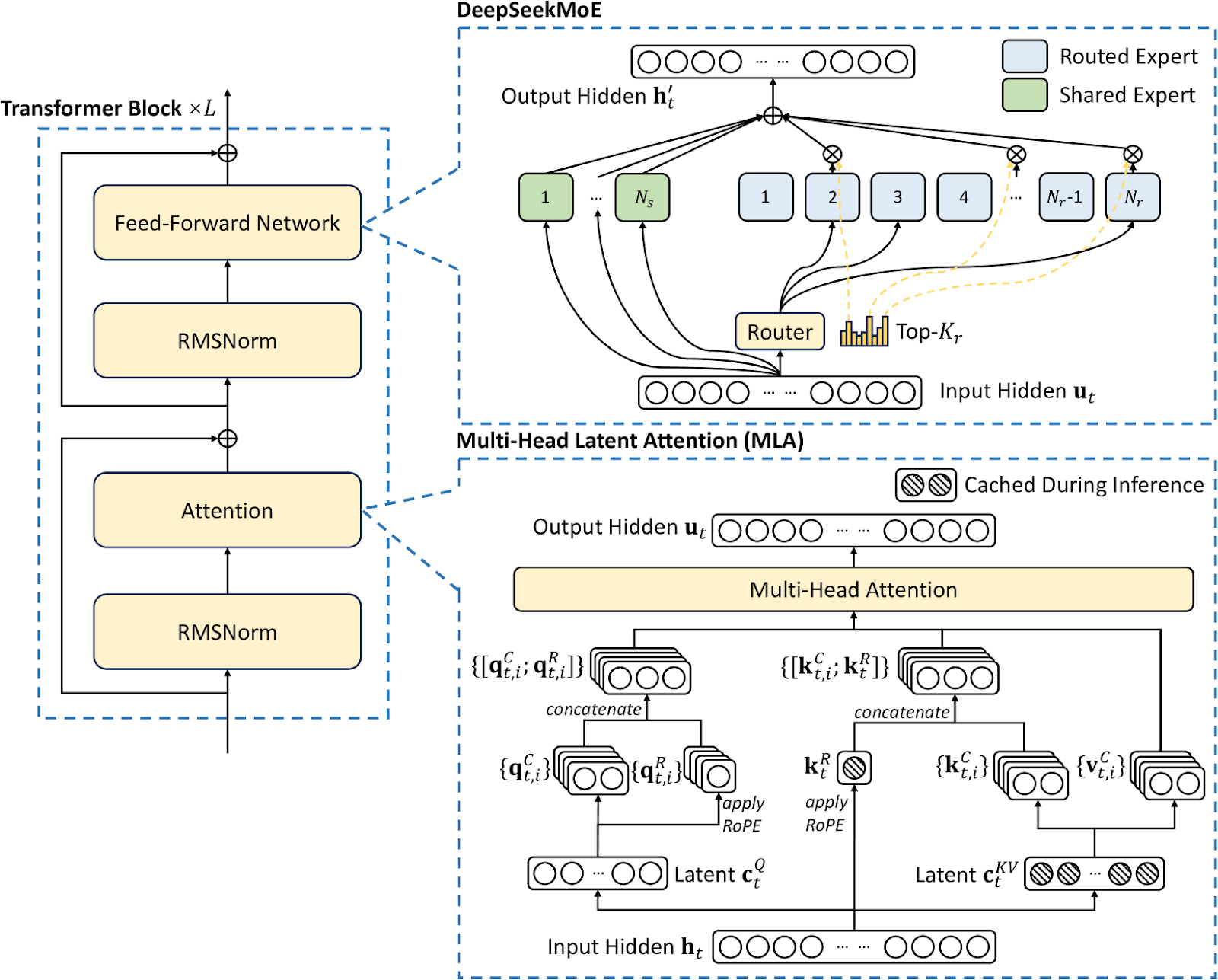
But the problem of MLA is that every token must still attend to all other tokens, which is computationally expensive. To address this problem, DeepSeek introduced DeepSeek Sparse Attention (DSA) on top of MLA. With DSA each token only attends to a subset of the preceding tokens. Other sparse attention mechanisms use static algorithms such as “sliding window,” where each token attends to a fixed number of tokens that precede it. The problem with this approach is that it introduces a heavy accuracy/efficiency tradeoff because the sliding window might miss important tokens that are relevant to the current token.
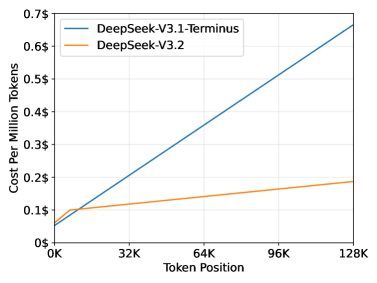
In contrast, DSA uses a “lightning indexer” that determines which of the previous tokens are important for the current token to attend to. This mechanism ensures that while the model benefits from efficiency gains, it minimizes accuracy loss. DSA practically turns attention from a quadratic problem to a linear one. In comparison to DeepSeek-V3.1 Terminus, an earlier model that didn’t use DSA, DeepSeek-V3.2 reduces the costs of attention considerably, and the difference becomes even larger as the sequence becomes longer.
There is a lot more we can get into such as updates to the training recipe. I suggest you read the technical report or read Sebastian Raschka’s excellent deep dive on the DeepSeek-V3 model family. The DeepSeek team has proven once again that with great engineering, you can make impressive advances in creating better models.