



")
















This article is part of our coverage of the latest in AI research.
Long-term memory remains a key challenge for large language models. The industry is currently maxing out at effective context windows of around 1 million tokens, which impedes the development of complex applications like massive multi-agent systems and processing very large text corpora.
Memory Sparse Attention (MSA), a new technique developed by researchers at Evermind, Shanda Group, and Peking University, addresses the shortcomings of current long-memory solutions. The architecture enables models to extend their context window up to 100 million tokens while preserving their reasoning accuracy.
The key innovation of MSA is a differentiable, end-to-end routing mechanism. The model learns to compress massive document collections into precomputed attention values and retrieve only the most relevant document chunks directly into the model’s active working memory during generation. MSA represents one of several emerging optimization techniques that allow developers to build AI applications capable of handling massive documents and developing long-term memory skills for dynamic environments.
The challenge of long memory
LLMs struggle with long-term, fine-grained memory retention. Standard full-attention mechanisms become computationally constrained as data grows because of their memory requirements. To process language, models compute how every token relates to every other token in a sequence. As the sequence gets longer, the computation required to track these relationships grows quadratically.
The effective context window for most modern LLMs is capped between 128,000 and 1 million tokens. To put this in perspective, cognitive science estimates human lifelong memory holds the equivalent of 200 to 300 million tokens.
This hard limit challenges complex applications that require long, persistent context. When attempting to comprehend extensive novel series (e.g., A Song of Ice and Fire or the Harry Potter series), standard models inevitably drop early plot points and subtle character details. When building digital twins to replicate human behavior, or maintaining consistent personas in role-playing, the AI will eventually forget its identity and break character as the conversation history overflows the available context window.
Similarly, managing the long-term history of multi-agent systems becomes unmanageable because the models cannot reliably retrieve granular decisions or past interactions to inform current reasoning. The core challenge for AI developers is scaling LLM memory without sacrificing computational efficiency, architectural compatibility, or reasoning precision.
Requirements for an effective memory system
In their paper, the researchers specify five core characteristics for an effective long-term memory system:
1- The system must offer architectural compatibility, integrating easily with mainstream LLM architectures rather than requiring isolated base models.
2- It must provide lifetime memory, scaling to handle massive context lengths while keeping computational overhead low and avoiding degradation in reasoning quality.
3- To ensure high-precision retrieval and storage, the memory mechanism needs end-to-end trainability, meaning it is fully differentiable and jointly optimized with the generation process as opposed to operating as an external retrieval system.
4- It also requires straightforward memory management for storing and updating context.
5- Finally, the system needs robustness against catastrophic forgetting. As the model processes vast amounts of conflicting information over time, it must retain its structural integrity and avoid overwriting critical historical knowledge.
Current approaches miss the mark on these requirements:
Parameter-based memory, such as continuous fine-tuning, updates model weights to store knowledge but incurs massive training overhead. It is also vulnerable to catastrophic forgetting when exposed to conflicting data.
External storage, such as standard retrieval-augmented generation (RAG) pipelines, relies on semantic text embeddings decoupled from the LLM’s internal reasoning space. Because it is not end-to-end differentiable, standard RAG inherently hits a performance ceiling, offering shallow semantic matching that struggles with complex, multi-hop reasoning.
Latent state compression, such as techniques that compress the KV cache into a fixed chunk of memory, are also limited in the granularity of information they can hold. As context lengthens, compressing long history into fixed-size states inevitably leads to severe information loss and precision degradation.
Overall, current approaches suffer from two fundamental limitations:
1- The limited scalability of high-fidelity memory forces a trade-off between how accurately a model remembers and how much data it can hold. Methods guaranteeing high-precision retrieval have fixed context limits, while those scaling to massive capacities struggle to maintain precision
2- There are no end-to-end trainable solutions. To build systems that scale, developers stitch together disconnected parts, creating an optimization gap that makes it impossible to build a memory pipeline meeting all core criteria listed above.
How Memory Sparse Attention works
To overcome the strict trade-offs of existing methods, MSA redefines how LLMs interact with their context by integrating memory retrieval and answer generation into a single, jointly-optimized latent state framework.
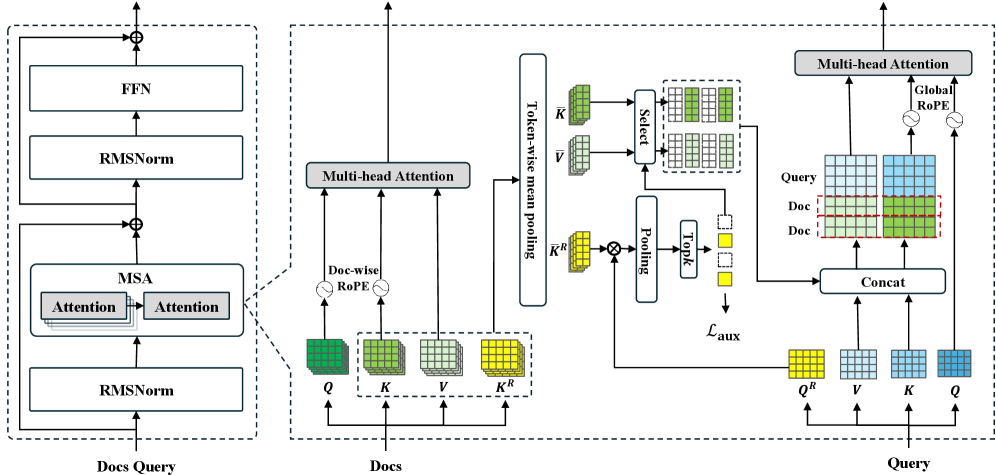
It relies on an end-to-end trainable sparse attention mechanism. MSA replaces standard dense self-attention with a document-based retrieval system operating directly within the model’s native representation space.
MSA segments documents, calculates their attention values, and compresses their hidden states into compact “Routing Keys” and standard Key-Value (KV) matrices. The KV cache is essentially the model’s scratchpad, storing the mathematical representations of previously processed tokens so it doesn’t have to recalculate them. In long-context tasks, the KV cache can become very large and unwieldy, so the routing keys are the compressed version of the data that act like index cards and enable the model to search for relevant data without perusing the dense attention values.
During generation, a specialized projector matches the user’s query against these Routing Keys to dynamically fetch only the top most relevant document chunks into the active context. To make this learnable through gradient descent, MSA introduces an additional loss function during pre-training that teaches the internal router to distinguish between relevant and irrelevant chunks in the latent routing space. This ensures the model has high-precision retrieval while avoiding the limitations of decoupled RAG systems.
The architecture also implements a technique called “document-wise positional encoding.” In an ideal scenario, building a 1 million token context model would involve training it on 1-million token examples.
Because that is computationally impractical, researchers use Rotary Positional Embedding (RoPE) to allow models to work beyond their training length. A model trained on 64k tokens might extrapolate to 128k or 256k tokens. However, standard RoPE fails when context grows drastically to 10 or 100 million tokens.
MSA solves this with document-wise RoPE, which assigns independent position IDs starting from zero to each document in the context. Inside the document, each token is assigned a position relative to the start of that specific document. This tweak decouples the positional semantics from the total number of documents in memory.
To the model’s internal attention mechanism, the 10,000th document in a massive database looks structurally identical to the first document. Because no document ever exceeds the length of the model’s training window, the model can effectively extrapolate. This allows developers to train efficiently on shorter 64k-token contexts while robustly extrapolating to 100 million tokens during inference, preventing catastrophic forgetting and precision loss.
A secondary benefit is that, with documents processed and indexed independently, developers can easily change the contents of individual documents and recompute their KV values without invalidating the entire cache.
Handling the hardware limits
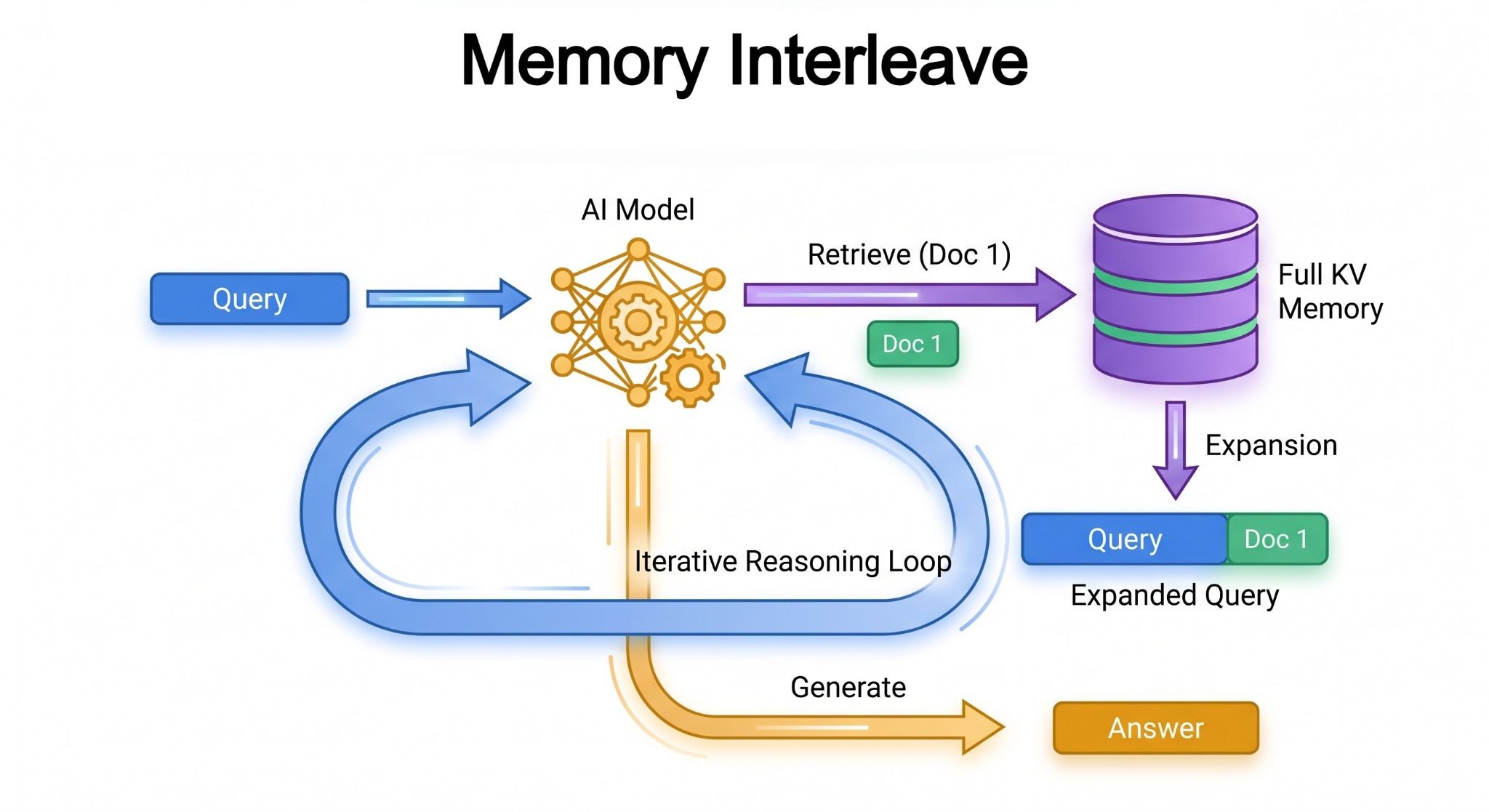
To make MSA practical in deployment settings, the researchers designed two key innovations for retrieving and handling the model’s memory. The first is a multi-hop “Memory Interleave” mechanism. For complex queries requiring deep reasoning across scattered data, MSA doesn’t do single-shot retrieval from its memory store. Instead, it uses an iterative process that alternates between retrieving documents, appending them to the query context, and refining its search based on newly acquired evidence until it has sufficient context to generate a final answer.
The second innovation tackles memory parallelism. Handling the KV cache for long contexts is a significant hardware bottleneck. According to the paper’s estimates, the compressed KV cache for 100 million tokens requires approximately 169GB of memory. Holding all that data in VRAM is unsustainable.
To solve this, MSA implements a two-part hardware optimization pipeline called “Memory Parallel,” relying on a tiered storage strategy. As we discussed above, when MSA processes documents, it creates lightweight Routing Keys that act like index cards. These keys are small enough, requiring about 56GB for 100 million tokens, that they can be safely stored directly on the fast, low-latency VRAM of the GPUs.
The massive bulk of the actual text data, the Content KVs, is offloaded entirely from the GPU and stored in the host machine’s cheaper CPU DRAM. On a standard AI compute node consisting of two NVIDIA A800 GPUs with a combined 160GB of VRAM, the system splits the 56GB Routing Keys in half. GPU 1 gets half the index, and GPU 2 gets the other half.
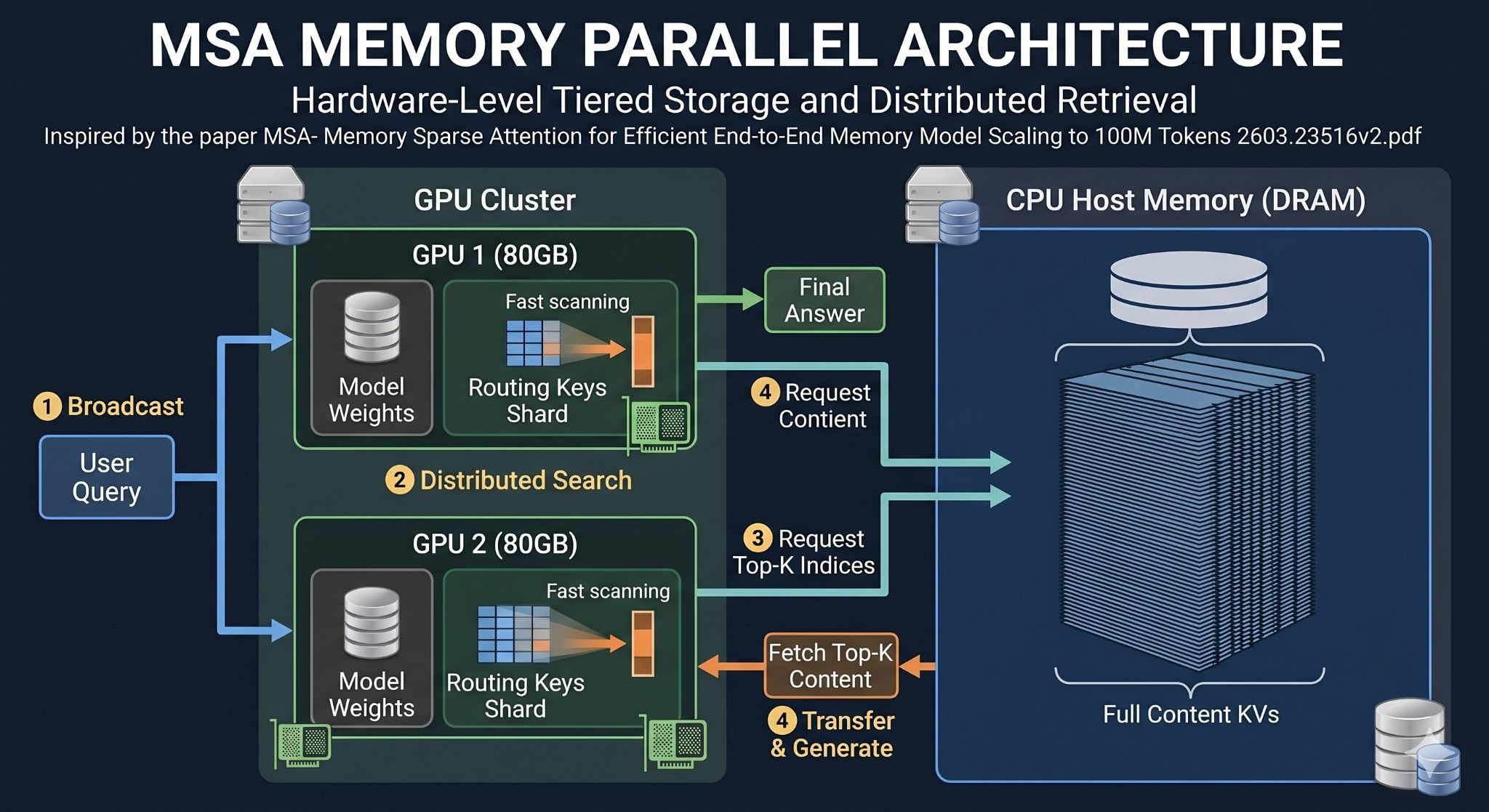
When a query arrives, it broadcasts to both GPUs simultaneously. Each GPU independently searches its own half of the index. They quickly compare scores globally to find the absolute best documents, and fetch those specific files from the DRAM.
Putting it all together
When MSA runs in production, it relies on a three-stage inference process. Assume a task features a 100 million token context. First, an offline stage processes the massive memory bank. The model runs a one-time forward pass over the entire document corpus. It generates standard KV matrices alongside the specialized Routing Keys. The system chunks and compresses these matrices and stores them in its memory bank.

Subscribe to continue reading
Become a paid subscriber to get access to the rest of this post and other exclusive content.