



















This article is part of our coverage of the latest in AI research.
As the popularity of large language models (LLM) continues to surge, there’s a parallel interest growing in vector databases. These databases offer a tantalizing prospect: they allow organizations to customize the behavior of LLMs to their proprietary data without the need for extensive model fine-tuning.
Yet, a recent study by researchers at Waterloo University and Roma Tre University posits that the benefits of sophisticated “embedding search” capabilities offered by LLMs can be reaped without the hefty investment in vector databases. The researchers propose a technique that leverages Apache Lucene, a widely-used open-source information retrieval library integral to many enterprise application frameworks, including Elasticsearch.
This technique can enable enterprises to dip their toes into the waters of advanced AI technologies without the financial burden of new software investments. The study provides an alternative vector search solution that is more accessible and cost-effective.
The costs of vector databases
The concept underpinning vector search is elegantly simple. Documents and queries are processed by a transformer model, resulting in a finite-length vector, known as an “embedding.” In a sense, these embeddings encapsulate the meaning of the input. Therefore, when you calculate the dot product of two embedding vectors, what you obtain is the semantic similarity between their corresponding text. Vector search comes down to computing the embedding of your query and finding the documents that have the most similar embeddings.
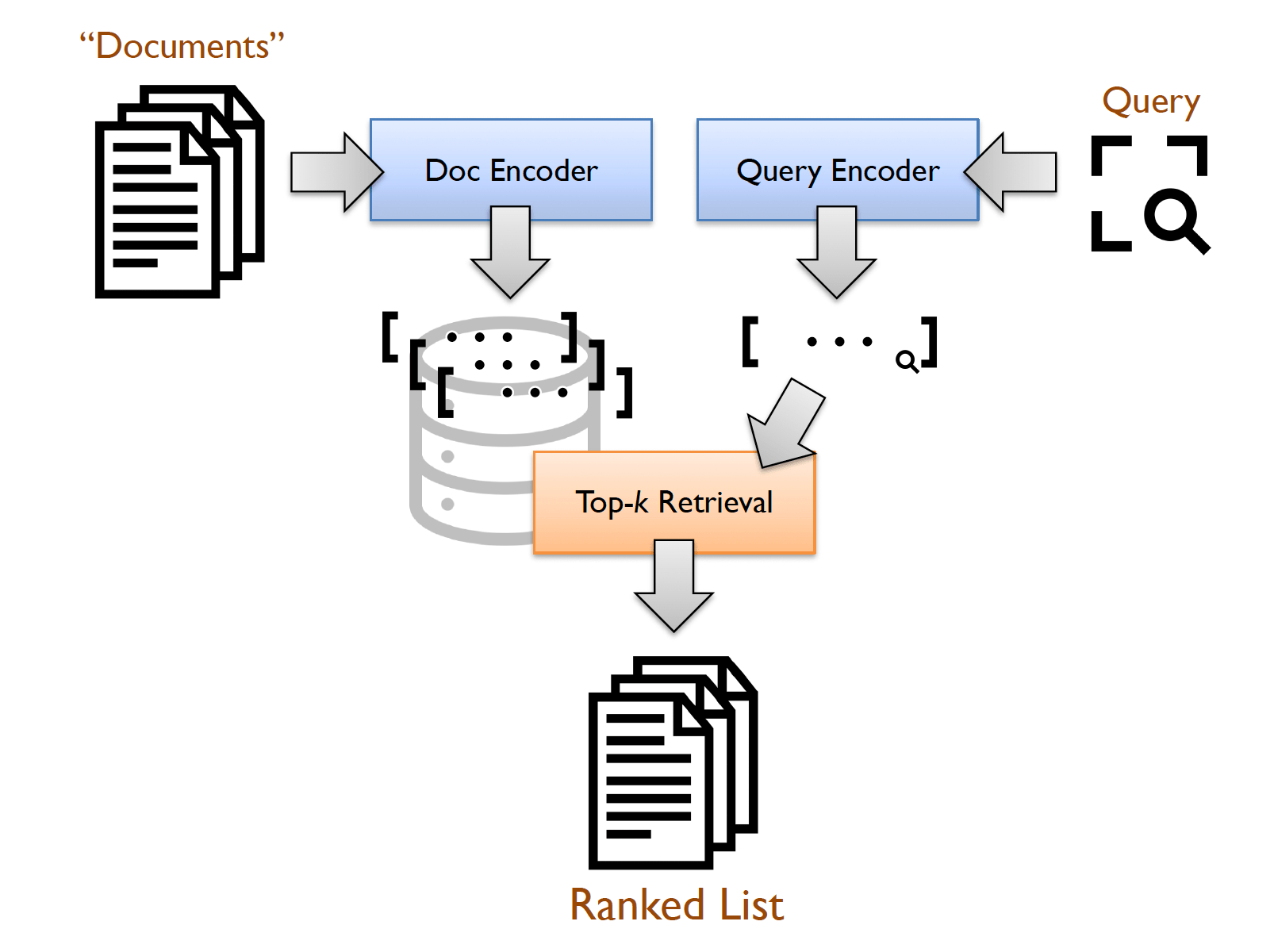
Vector search, or embedding search, opens up a world of possibilities for enterprises. It enables the addition of advanced features to applications, such as sophisticated search functionality where users can pose questions in natural language, rather than cobbling together a string of keywords. Furthermore, embedding search allows organizations to pair their knowledge base with LLMs, creating customized chatbots capable of providing answers based on the company’s proprietary data.
However, the technical overhead of embedding search is a hurdle that many organizations find insurmountable. The prevailing narrative suggests that a modern enterprise’s “AI stack” necessitates a dedicated vector database in addition to existing staples like relational databases.
The researchers highlight this point in their paper: “Modern enterprise architectures are already exceedingly complex, and the addition of another software component (i.e., a distinct vector store) requires carefully weighing costs as well as benefits. The cost is obvious: increased complexity, not only from the introduction of a new component, but also from interactions with existing components. What about the benefits? While vector stores no doubt introduce new capabilities, the critical question is whether these capabilities can be provided via alternative means.”
This observation is particularly important. While there’s no shortage of tutorials and articles on using vector databases to augment LLM search and chatbot capabilities with existing data, very few consider the costs of implementing and deploying these solutions in an enterprise setting.
Product managers exploring new features or products are always on the hunt for ways to reduce the costs and time required to create a minimum viable product (MVP). The ideal scenario would allow them to leverage their existing infrastructure and make minimal modifications to test hypotheses and iterate over different MVP versions.
However, the adoption of a new vector database and its integration into an enterprise’s existing tech stack can be a costly and time-consuming endeavor. Aside from the financial investment, it requires time and resources to implement, manage, and maintain this new component in an already complex system. This is where the researchers’ proposed technique, using Apache Lucene, comes into play, potentially offering a more accessible and cost-effective solution.
Lucene for vector store

In their paper, the researchers highlight the significant investments many organizations have already made in the Lucene ecosystem.
“While most organizations do not directly use the open-source Lucene search library in production, the search application landscape is dominated by platforms that are built on top of Lucene such as Elasticsearch, OpenSearch, and Solr,” the researchers write.
Elastic, the developer of Elasticsearch, has over 20,000 subscriptions on its cloud service. And many organizations run Elasticsearch on their own servers. Overall, Lucene is the dominant platform used for search engines in different enterprise applications.
Lucene was not initially designed for vector search. But since December 2021, Lucene has incorporated support for hierarchical navigable small-world networks (HNSW), the main algorithm used in vector search.
“This means that differences in capabilities between Lucene and dedicated vector stores are primarily in terms of performance, not the availability of must-have features,” they write. “Thus, from a simple cost–benefit calculus, it is not clear that vector search requires introducing a dedicated vector store into an already complex enterprise ‘AI stack’. Our thesis: Lucene is all you need.”
LLM search with Lucene
To test their theory, the researchers developed a prototype of a vector search system using Lucene. They used the MS MARCO passage ranking dataset, which comprises 8.8 million passages extracted from the web. They used the OpenAI API to create embeddings of the data, which means they did not do any form of fine-tuning.
The researchers conducted their experiments using Anserini, an open-source information retrieval system built on Lucene. The project’s GitHub page states, “By building on Lucene, we aim to bridge the gap between academic information retrieval research and the practice of building real-world search applications.”
The researchers write, “Capabilities implemented by researchers in Anserini using Lucene can be straightforwardly translated into Elasticsearch (or any other platform in the Lucene ecosystem), thus simplifying the path from prototypes to production deployments.”
In terms of accuracy, the results of their experiments were promising. The combination of OpenAI embeddings and Lucene achieved results comparable to other techniques based on pure vector database implementations. The researchers write, “Our main point is that we can achieve effectiveness comparable to the state of the art using a production-grade, completely off-the-shelf embedding API coupled with Lucene for indexing and retrieval.”
The researchers also acknowledge that implementing vector search with Lucene is not trivial because it is not the main use case for the framework. However, they anticipate that Lucene will soon incorporate the necessary features and make the process simpler.
They also note that Lucene is significantly slower than specialized vector databases. But this performance gap will decrease over time as the features evolve, making Lucene an increasingly viable alternative for organizations looking to leverage advanced AI technologies without the need for heavy investment in new software.
What does it mean for enterprise LLM applications?
There’s no denying that dense representation learning and vector search will play a pivotal role in the wave of AI-powered features being integrated into products. However, the question remains: Do you absolutely need to adopt a dedicated vector store for your enterprise? The research paper suggests that there may already be more cost-effective alternatives available.
Currently, there’s a buzz around vector databases, with many touting them as a crucial component of the contemporary AI stack. While this may hold true, the research shows the importance of taking a moment to reflect before diving headfirst into this latest tech trend.
If your enterprise is already using a Lucene-powered database, it’s worth exploring whether it can meet your vector search needs before investing in a vector database. This approach can expedite the creation of prototypes and validation of hypotheses, bypassing the time and resource overhead associated with adopting a completely new technology. In fact, you may find that a Lucene-based solution’s performance is sufficient for your use case. If it falls short, you can then consider the more costly option of adopting a vector database. Alternatively, you could wait a few months for the vector search capabilities of Lucene-based frameworks to evolve.
The researchers conclude, “If you’ve built search applications already, chances are you’re already invested in the Lucene ecosystem. In this case, Lucene is all you need. Of course, time will tell who’s right.”