




















This article is part of our coverage of the latest in AI research.
Large language models (LLM), while powerful, exhibit peculiar sensitivities to the way their prompts are formulated. In fact, providing the same command with different prompt formulations can yield completely different results. For instance, informing the model that your career depends on its response may increase the likelihood of it adhering more closely to your instructions. Additionally, using phrases like “let’s go through it step by step” can elicit reasoning in the models and improve their accuracy.
Prompt engineering techniques, such as Chain of Thought (CoT) and emotional prompts, have gained popularity in recent years. However, there is still much to uncover when it comes to optimizing LLM prompts. Since LLMs do not understand language in the same way humans do, attempting to optimize their prompts through our own perspective on language might not yield the best results.
An alternative approach is to allow LLMs to optimize their own prompts and discover the most effective instructions to enhance their accuracy. This concept forms the basis of Optimization by PROmpting (OPRO), a simple yet powerful method developed by Google DeepMind to use LLMs as optimizers.
How OPRO works
With OPRO, you can use LLMs as an optimizer. But instead of using mathematical formulas, you can describe the optimization problem using natural language, instructing the LLM to iteratively generate and refine its solutions. This is especially useful for problems such as prompt optimization, where gradients are not readily available.
OPRO starts with a “meta-prompt” as input, composed of a natural language description of the task and a few examples of problems and solutions. Throughout the optimization process, the LLM generates candidate solutions based on the problem description and previous solutions in the meta-prompt. OPRO then evaluates the results of these candidate solutions and adds them to the meta-prompt, along with their quality score. This process is repeated until the model no longer proposes new solutions with improved scores.
One of the key advantages of LLMs for optimization is their ability to process natural language instructions. This allows users to describe optimization tasks without formal specifications.
For instance, users can specify metrics such as “accuracy” while simultaneously providing other instructions, like requiring the model to deliver concise and generally applicable solutions.
OPRO also capitalizes on LLMs’ capacity to detect in-context patterns, enabling the identification of an optimization trajectory based on the exemplars included in the meta-prompt. This aspect, in my opinion, is the primary magic of OPRO. Since it sees language as numerical tokens, it can find patterns that are not visible to human observers.
“Including optimization trajectory in the meta-prompt allows the LLM to identify similarities of solutions with high scores, encouraging the LLM to build upon existing good solutions to construct potentially better ones without the need of explicitly defining how the solution should be updated,” DeepMind explains in its paper.
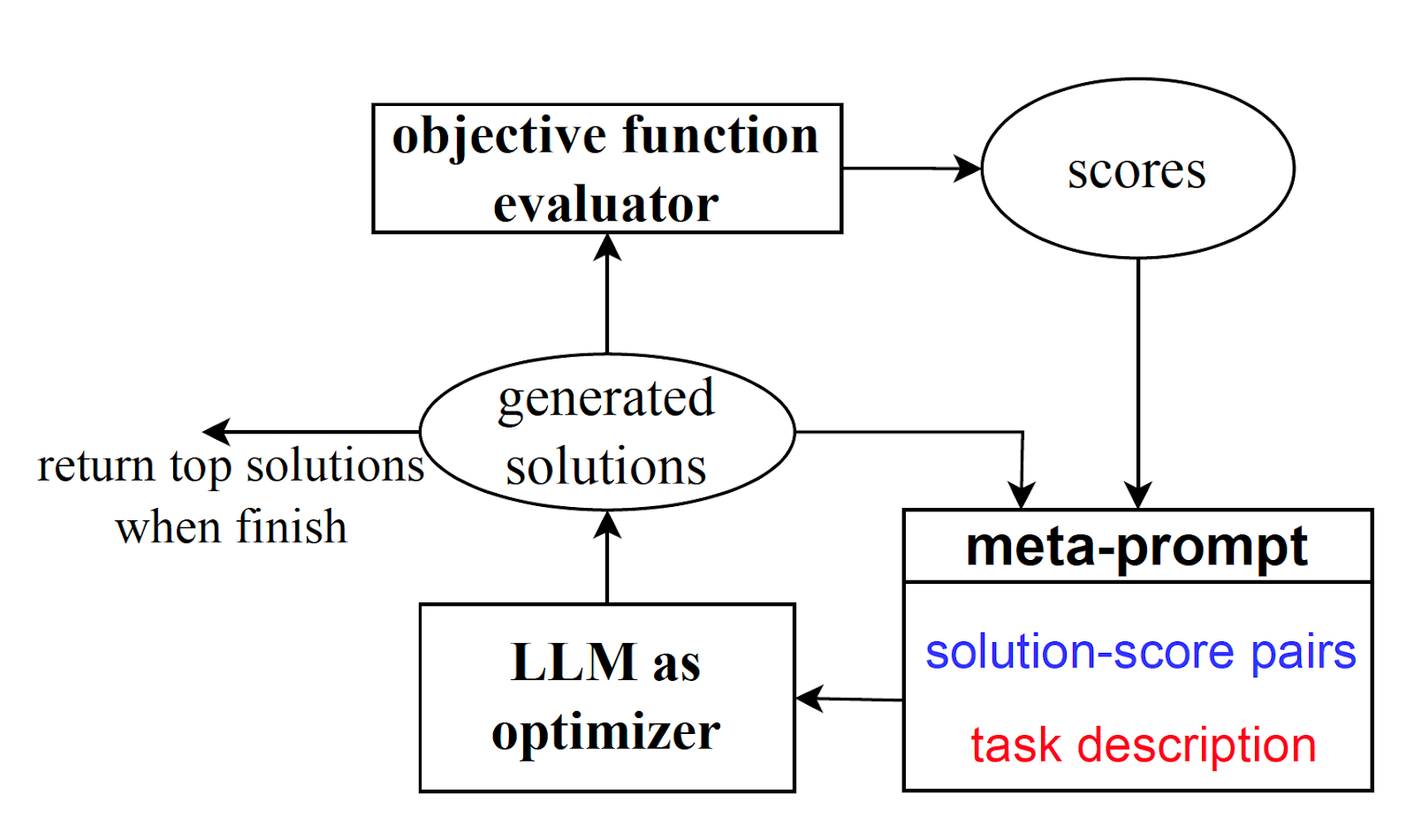
Optimizing prompts with OPRO
DeepMind tested OPRO on linear regression and the “traveling salesman problem,” two well-known mathematical optimization problems. The technique demonstrated promising results in both cases. However, the true potential of OPRO lies in optimizing the use of LLMs like ChatGPT and PaLM.
The DeepMind paper shows that OPRO can guide LLMs toward optimizing their own prompts, meaning it can help find the prompt that maximizes the accuracy of responses for a specific task. For instance, to discover the optimal prompt for solving word-math problems, an “optimizer LLM” is given a meta-prompt containing instructions and examples with placeholders for the optimization prompt. The model generates a set of different optimization prompts and passes them to a “scorer LLM,” which tests them on problem examples and evaluates the results. The best prompts, along with their scores, are added to the beginning of the meta-prompt, and the process is repeated.
The researchers evaluated the technique using several LLMs from the PaLM and GPT families. According to their experiments, all of the models were able to improve the performance of the generated prompts through iterative optimization.
For example, when the researchers tested OPRO with PaLM-2 models on GSM8K, a benchmark of grade school math word problems, the model began with a prompt that finished with “Let’s solve the problem.” It then generated other prompt additions, such as “Let’s think carefully about the problem and solve it together,” “Let’s break it down,” “Let’s calculate our way to the solution,” and ultimately “Let’s do the math,” which yielded the highest accuracy.
In another experiment, adding the string “Take a deep breath and work on this problem step-by-step” before the LLM’s answer produced the most accurate result. These examples demonstrate how OPRO can help explore the space of possible LLM prompts and identify the one that works best for a specific type of problem. But they are also a reminder of the differences between how LLMs and humans understand language.
How to use OPRO
Although DeepMind has not released the code for OPRO, the concept behind the technique is intuitive and straightforward, making it possible to create a custom implementation in just a few hours. Alternatively, you can follow this step-by-step guide by LlamaIndex, which demonstrates how to use OPRO to enhance an LLM’s performance on retrieval augmented generation (RAG) tasks using external documents.
The code sample in the guide employs GPT-3.5 Turbo as both the optimizer and evaluator LLM. However, you can easily adapt it to your preferred model. OPRO is just one of several techniques that leverage LLMs to optimize their own performance. This area is actively being explored across various topics, including jailbreaking and red-teaming, as researchers continue to unlock the full potential of large language models.