



")
















This article is part of Demystifying AI, a series of posts that (try to) disambiguate the jargon and myths surrounding AI.
Graphs are everywhere around us. Your social network is a graph of people and relations. So is your family. The roads you take to go from point A to point B constitute a graph. The links that connect this webpage to others form a graph. When your employer pays you, your payment goes through a graph of financial institutions.
Basically, anything that is composed of linked entities can be represented as a graph. Graphs are excellent tools to visualize relations between people, objects, and concepts. Beyond visualizing information, however, graphs can also be good sources of data to train machine learning models for complicated tasks.
Graph neural networks (GNN) are a type of machine learning algorithm that can extract important information from graphs and make useful predictions. With graphs becoming more pervasive and richer with information, and artificial neural networks becoming more popular and capable, GNNs have become a powerful tool for many important applications.
Transforming graphs for neural network processing

Every graph is composed of nodes and edges. For example, in a social network, node can represent users and their characteristics (e.g., name, gender, age, city), while edges can represent the relations between the users. A more complex social graph can include other types of nodes, such as cities, sports teams, news outlets, as well as edges that describe the relations between the users and those nodes.
Unfortunately, the graph structure is not well suited for machine learning. Neural networks expect to receive their data in a uniform format. Multi-layer perceptrons expect a fixed number of input features. Convolutional neural networks expect a grid that represents the different dimensions of the data they process (e.g., width, height, and color channels of images).
Graphs can come in different structures and sizes, which does not conform to the rectangular arrays that neural networks expect. Graphs also have other characteristics that make them different from the type of information that classic neural networks are designed for. For instance, graphs are “permutation invariant,” which means changing the order and position of nodes doesn’t make a difference as long as their relations remain the same. In contrast, changing the order of pixels results in a different image and will cause the neural network that processes them to behave differently.
To make graphs useful to deep learning algorithms, their data must be transformed into a format that can be processed by a neural network. The type of formatting used to represent graph data can vary depending on the type of graph and the intended application, but in general, the key is to represent the information as a series of matrices.
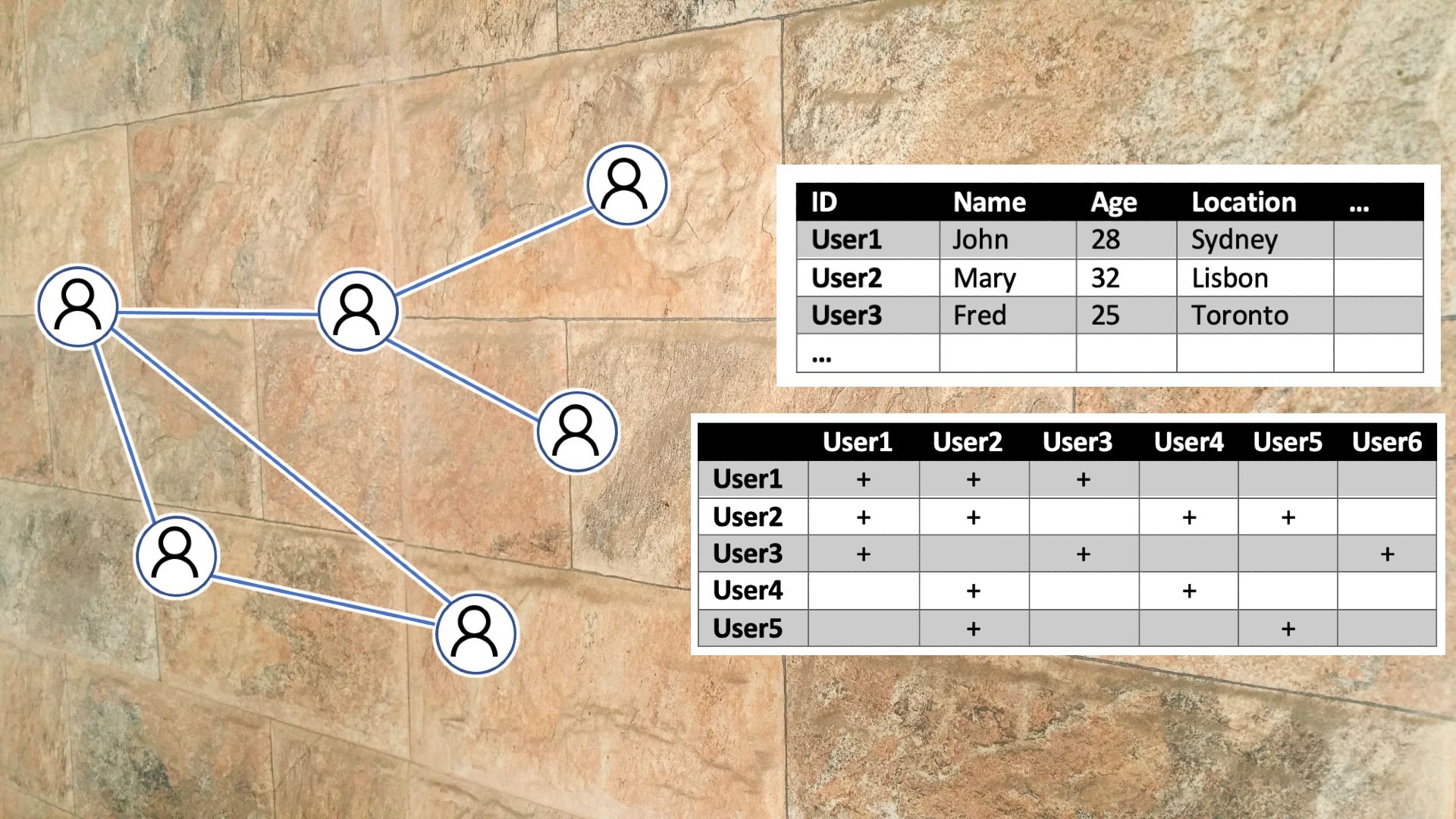
For example, consider a social network graph. The nodes can be represented as a table of user characteristics. The node table, where each row contains information about one entity (e.g., user, customer, bank transaction), is the type of information that you would provide a normal neural network.
But graph neural networks can also learn from other information that the graph contains. The edges, the lines that connect the nodes, can be represented in the same way, with each row containing the IDs of the users and additional information such as date of friendship, type of relationship, etc. Finally, the general connectivity of the graph can be represented as an adjacency matrix that shows which nodes are connected to each other.
When all of this information is provided to the neural network, it can extract patterns and insights that go beyond the simple information contained in the individual components of the graph.
Graph embeddings

Graph neural networks can be created like any other neural network, using fully connected layers, convolutional layers, pooling layers, etc. The type and number of layers depend on the type and complexity of the graph data and the desired output.
The GNN receives the formatted graph data as input and produces a vector of numerical values that represent relevant information about nodes and their relations.
This vector representation is called “graph embedding.” Embeddings are often used in machine learning to transform complicated information into a structure that can be differentiated and learned. For example, natural language processing systems use word embeddings to create numerical representations of words and their relations together.
How does the GNN create the graph embedding? When the graph data is passed to the GNN, the features of each node are combined with those of its neighboring nodes. This is called “message passing.” If the GNN is composed of more than one layer, then subsequent layers repeat the message-passing operation, gathering data from neighbors of neighbors and aggregating them with the values obtained from the previous layer. For example, in a social network, the first layer of the GNN would combine the data of the user with those of their friends, and the next layer would add data from the friends of friends and so on. Finally, the output layer of the GNN produces the embedding, which is a vector representation of the node’s data and its knowledge of other nodes in the graph.
Interestingly, this process is very similar to how convolutional neural networks extract features from pixel data. Accordingly, one very popular GNN architecture is the graph convolutional neural network (GCN), which uses convolution layers to create graph embeddings.
Applications of graph neural networks

Once you have a neural network that can learn the embeddings of a graph, you can use it to accomplish different tasks.
Here are a few applications for graph neural networks:
Node classification: One of the powerful applications of GNNs is adding new information to nodes or filling gaps where information is missing. For example, say you are running a social network and you have spotted a few bot accounts. Now you want to find out if there are other bot accounts in your network. You can train a GNN to classify other users in the social network as “bot” or “not bot” based on how close their graph embeddings are to those of the known bots.
Edge prediction: Another way to put GNNs to use is to find new edges that can add value to the graph. Going back to our social network, a GNN can find users (nodes) who are close to you in embedding space but who aren’t your friends yet (i.e., there isn’t an edge connecting you to each other). These users can then be introduced to you as friend suggestions.
Clustering: GNNs can glean new structural information from graphs. For example, in a social network where everyone is in one way or another related to others (through friends, or friends of friends, etc.), the GNN can find nodes that form clusters in the embedding space. These clusters can point to groups of users who share similar interests, activities, or other inconspicuous characteristics, regardless of how close their relations are. Clustering is one of the main tools used in machine learning–based marketing.
Graph neural networks are very powerful tools. They have already found powerful applications in domains such as route planning, fraud detection, network optimization, and drug research. Wherever there is a graph of related entities, GNNs can help get the most value from the existing data.