




















This article is part of our coverage of the latest in AI research.
The dominant narrative of AI progress in recent years has been model building larger models and feeding them more data. But for long-horizon agentic AI, model scaling alone is not the ultimate solution.
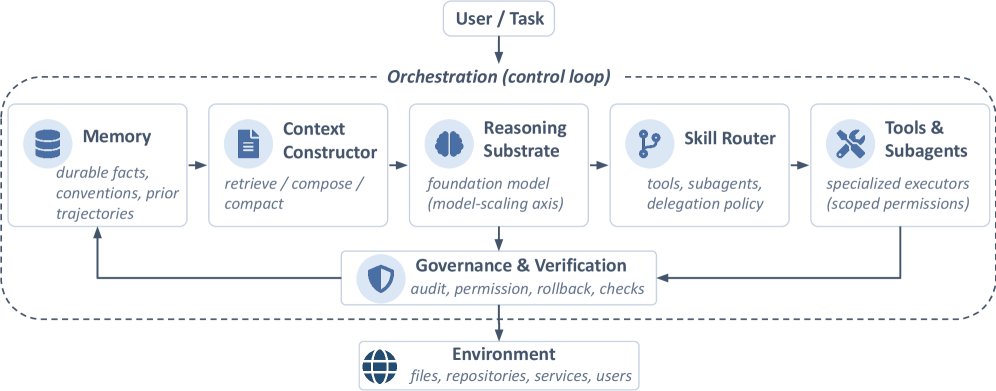
AI agents don’t get their abilities from next-token prediction alone but from the system that wraps around the model to translate its answers into real-world behavior.
The next major bottleneck in agentic AI is “system scaling,” or scaling the “harness,” according to a new paper from UC Berkeley. This approach treats the structured execution layer as a first-class object of design and optimization. As the author notes, “The dominant story of recent AI progress has been model scaling… For agentic AI, this story is now incomplete”.
Furthermore, “Once foundation models are embedded into tools, terminals, browsers, repositories, memory stores, and external services, their behavior is no longer determined by the model alone. It is determined by a system.”
This means when building and evaluating AI systems, we should move beyond just evaluating the model and look at the entire system and scaffolding as a whole and make sure every aspect is optimized for optimal performance.
Deconstructing the AI harness
Modern agent frameworks operate as robust system infrastructures rather than basic prompt wrappers. Under the hood, an agentic system can be factored into six interacting components. These components include:
– A reasoning substrate that includes one or more LLMs
– A memory store that keeps track of long-term information that the agent needs
– A context constructor that builds and cleans up the information included in the model’s context window
– A skill-routing layer that decides which skills should be involved in each substep of the agent’s solution
– An orchestration loop that manages the sequence of operations and coordinates how the context constructor draws from memory to feed the foundation model
– A verification-and-governance layer that acts as a gatekeeper for both intermediate reasoning and external actions, managing permissions, audit trails, and rollbacks, ensuring that outputs are checked before they are allowed to affect the live environment or be written back into the persistent memory store
While different agent harnesses are built for different purposes and audiences, they usually converge on the same main components. Claude Code acts as a vendor coding tool, OpenClaw operates as a multi-channel personal assistant, and CheetahClaws serves as an open-source research reference harness. Yet, all three must actively manage context governance, memory storage, and skill routing.
The structural differences between these harnesses are driven by their specific deployment priorities, such as enterprise reliability versus open-source reproducibility, rather than changes to the underlying foundation model.
The three layers of agent time
An AI system operates across distinct temporal scales to manage complex, long-term tasks. You can break this architecture down into three functional layers: prompts, skills, and memory.
Prompts operate strictly on a local, short-horizon timescale to define immediate goals. They dictate what the model should focus on in the current moment. However, prompts are fragile over extended execution lengths and transfer poorly to new scenarios.
Skills operate on a task-level timescale as reusable execution patterns or tool workflows. Think of a skill as a predefined routine for searching a database or editing a configuration file. While highly effective for executing specific tasks, skills introduce new challenges. When an agent has dozens of skills, chaining them to solve ambiguous problems introduces routing, composition, and delegation challenges.
Memory functions as the longitudinal layer that preserves facts across sessions. It allows an agent to remember user preferences or project architectures weeks after the first interaction. However, memory is vulnerable to degradation, contamination, and over-generalization over time.
The major bottlenecks of system scaling
Building a reliable autonomous agent requires solving three specific engineering roadblocks: context governance, trustworthy memory, and dynamic skill routing.
Expanding context capacity does not fix relevance. Unfiltered inputs create signal dilution, causing the model to suffer from an “exposure without access” failure where it misses crucial data buried in padding. Even LLMs that support million-token context windows suffer from context rot when their prompts become long and filled with conflicting information and data that are not relevant to the task at hand.
Context assembly must act as a strict selection policy that optimizes for a minimum sufficient context. “The hard problem of context is not capacity, but governance,” the paper notes, adding that “Long context does not indicate good context; tokens added without governance often degrade performance rather than improve it”.
Real-world tools prevent context flooding by employing aggressive management mechanisms. Recent architectural analyses of Claude Code reveal a five-tier compaction system. This includes routines like “micro-compact” for cleaning up old tool results and “context collapse” for summarizing long dialogue spans.
Furthermore, when tools emit massive text outputs (e.g., an endless server error log) the system avoids token bloating by writing the full file to the local disk and supplying only an 8-kilobyte preview to the LLM. This forces the model to act like a human developer, scanning the top of the log and only digging deeper if necessary.
Agent memory faces a completely different challenge: the “stale-but-confident” threat. This occurs when an agent erroneously tracks high-ranking semantic results that are completely outdated due to silent external drift. An agent might read an old note about how a codebase is structured, fail to realize the code was refactored yesterday, and confidently break the application. “The hard problem of agent memory is not storage, but trust,” the paper warns. Memory trust can only be sustained via just-in-time verification against the live environment.
Structurally, this is achieved via a “skeptical memory” framework. In Claude Code, an index file like MEMORY.md is treated strictly as an unverified pointer or hint. The agent is programmatically forced to verify the memory’s claims against the live file system before taking any destructive action. Additionally, systems maintain long-term memory hygiene by running background daemons like autoDream during idle times to resolve contradictions, compress insights, and bound memory growth before the agent degrades.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
Finally, multi-agent configurations suffer from a “confident-but-unchecked” vulnerability. In this scenario, a specialized routing branch outputs highly plausible but completely unverified answers.
“The hard problem of skill is not having skills, but routing and checking them,” the paper warns. Harness engineering must tie skill selection directly to explicit post-condition checks to guarantee reliability.
Evaluating and governing the evolving agent
Evaluating systems solely via one-shot outcome metrics, such as simple task success rates, masks hidden systemic liabilities. These hidden liabilities include high token costs, excessive tool-call latencies, and high retry errors. In a real-world deployment, an agent that brute-forces its way to a solution through endless retries wastes compute and risks API rate-limiting. Evaluation protocols must integrate process metrics that measure trajectory hygiene, verification overhead, and context efficiency over extended steps.
Multi-agent arrangements can open parallel processing windows, but genuine collaboration breaks down without a standardized communication layer for state sharing, contradiction spotting, and uncertainty reporting. “A one-shot evaluation cannot reveal whether an agent’s memory becomes more useful, more noisy, or more dangerous over repeated use,” the paper notes.
To safeguard agents against persistent threats like memory poisoning and goal manipulation, a concrete governance standard must define exactly what persists, what updates, and what leaves an unalterable audit trail. “Without such standards, many so-called learning agents risk becoming opaque accumulations of prompts, notes, and heuristics rather than reliable adaptive systems,” the paper writes.
While raw frontier-model reasoning capabilities remain indispensable, model capability alone is no longer an adequate baseline for evaluating or predicting agent success. “Agentic AI is moving from isolated model inference to persistent system execution,” per the paper.
The long-term roadmap of the AI sector will be defined by how securely and efficiently systems manage what the model remembers, what it retrieves, what actions it permits, and what it leaves fully auditable. “Scaling the harness, alongside scaling the model, defines the next major bottleneck of agentic AI,” the paper concludes.