


")

















This article is part of our coverage of the latest in AI research.
Generative artificial intelligence has empowered everyone to be more creative. Large language models (LLM) like ChatGPT can generate essays and articles with impressive quality. Diffusion models such as Stable Diffusion and DALL-E create stunning images.
But what happens when the internet becomes flooded with AI-generated content? That content will eventually be collected and used to train the next iterations of generative models. According to a study by researchers at the University of Oxford, University of Cambridge, Imperial College London, and the University of Toronto, machine learning models trained on content generated by generative AI will suffer from irreversible defects that gradually exacerbate across generations.
The only way to maintain the quality and integrity of future models is to make sure they are trained on human-generated content. But with LLMs such as ChatGPT and GPT-4 enabling the creation of content at scale, access to human-created data might soon become a luxury that few can afford.
Model collapse
In their paper, the researchers investigate what happens when text produced by say GPT-4 forms most of the training dataset of the model that follows it.

“What happens to GPT versions GPT-{n} as generation n increases?” the researchers write. “We discover that learning from data produced by other models causes model collapse – a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time.”
Machine learning models are statistical engines that try to learn data distributions. This is true for all kinds of ML models, from image classifiers to regression models to the more complex models that generate text and images.
The closer the model’s parameters approximate the underlying distribution, the more accurate they become in predicting real-world events.
However, even the most complex models are just approximations of the real world. So they tend to over-estimate more probable events and under-estimate less probable ones, albeit by a small margin. When used recursively to retrain themselves, these errors will pile up and the model will collapse. Eventually, later models in the sequence will drift from the original distribution of the natural data that was used to train them.
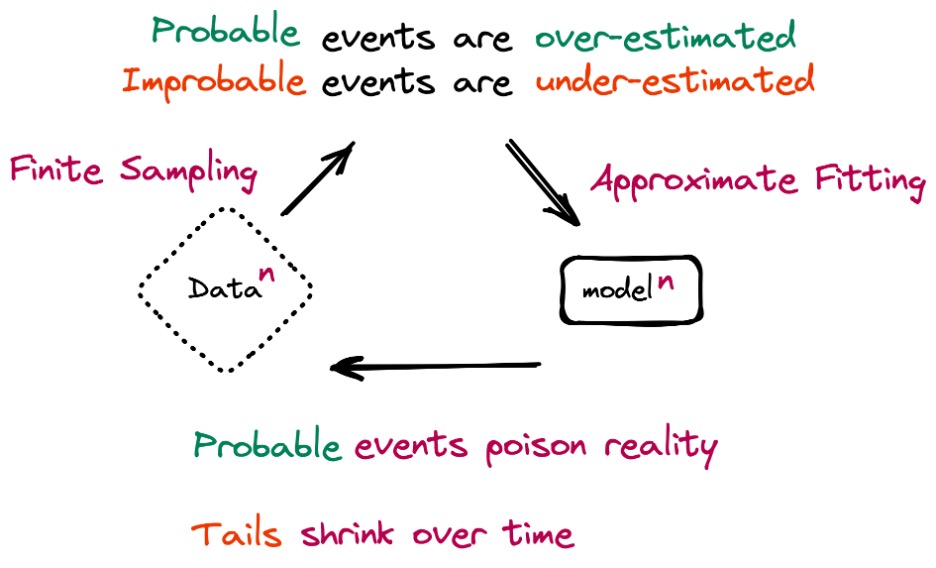
Model collapse is related to catastrophic forgetting, a problem that happens with models that are continuously trained on fresh data. Catastrophic forgetting causes ML models to gradually forget the information that was used to train them earlier in their lifecycles. Model collapse doesn’t erase previously learned data but causes the model to interpret it in erroneous ways.
Model collapse is also related to data poisoning, a process in which malicious actors try to manipulate a model’s behavior by intentionally modifying the data used to train it. Model collapse can be considered a form of data poisoning. However, instead of intentional actors, it is the model and the training process that pollute the training data.
Model collapse on generative AI
In their study, the researchers simulated the effects of training generative models on their own data. They tested three kinds of models: a Gaussian mixture model (GMM), a variational autoencoder (VAE), and a large language model (LLM).
The task of the GMMs is to separate two artificially generated Gaussians. The model was first trained on a dataset generated from a fixed function. Then it was used to generate new data and retrain the next model. Within 50 generations, the distribution of the data had completely changed. At generation 2,000, it had lost all its variance.
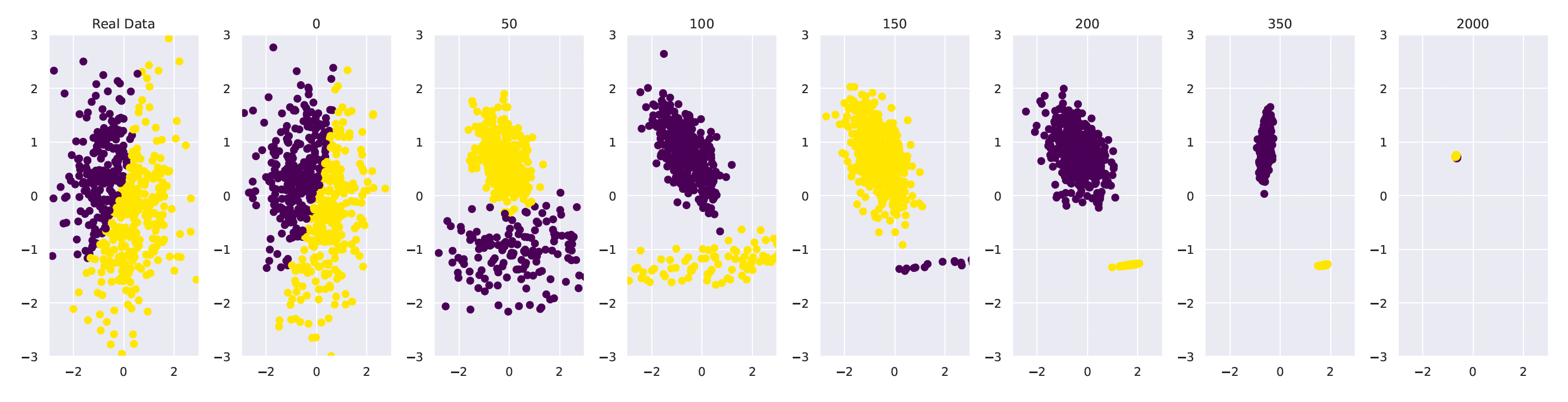
The VAE was used to generate handwritten digits. The initial model was trained on real data. The next generations were trained on data generated by previous models. The images become gradually blurry and by the 10th generation, they became incomprehensible.

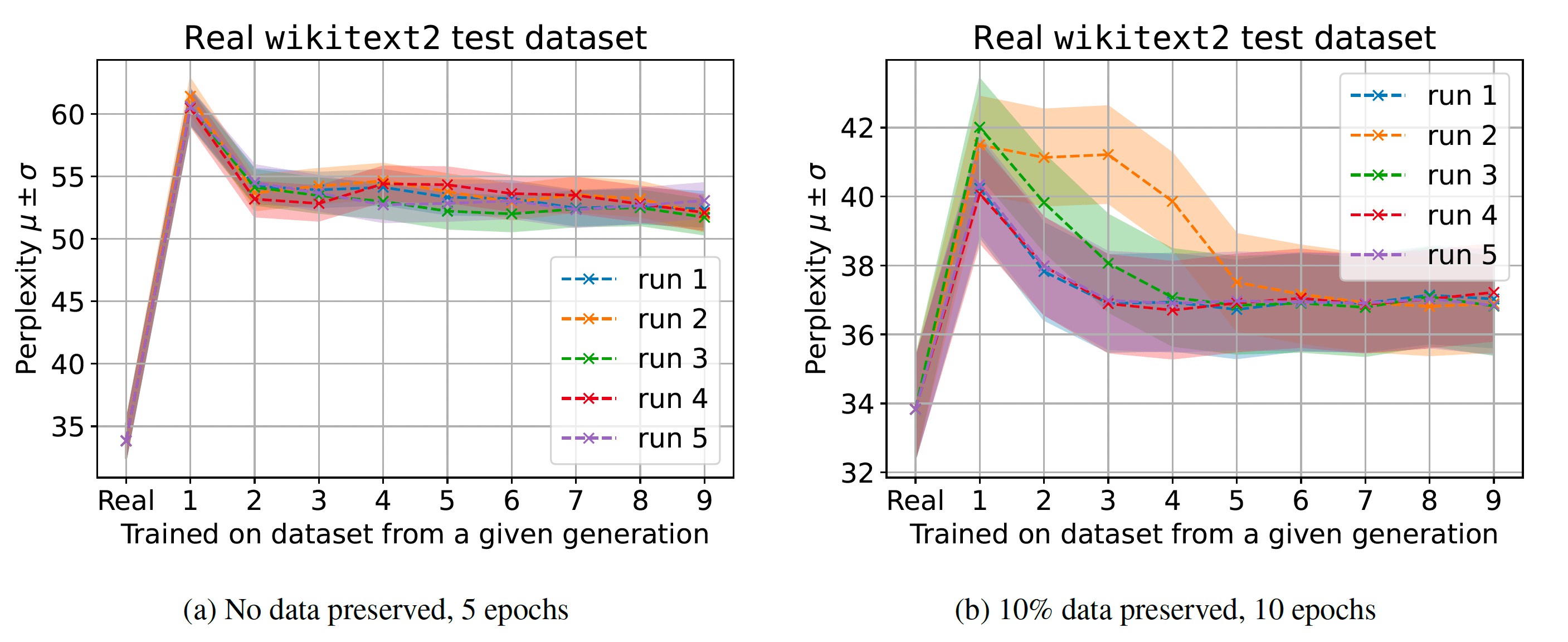
The researchers then tested their hypothesis on OPT-125m, a small version of Meta’s open-source LLM. They evaluated a common scenario in which a pre-trained model is fine-tuned with recent data. However, the fine-tuning data is produced by another fine-tuned pre-trained model.
They tested two different variants of the scenario. In one, only LLM-generated data is used for fine-tuning. In the second, a small part of the original human-generated data is also added to the training mix.
“Both training regimes lead to degraded performance in our models, yet we do find that learning with generated data is possible and models can successfully learn (some of) the underlying task,” the researchers write.
However, their findings also show over the generations, the models generated samples that would be produced with higher probabilities by the original model.
“At the same time, we discover that generated data has much longer tails, suggesting that some of the data would never be produced by the original model–these are the errors that accumulate because of the learning with generational data,” the researchers write.
What will happen to future generations of ChatGPT?
The digital age has caused all sorts of data pollution artifacts. Search engine algorithms largely influenced how people write online content. Bad actors resorted to all sorts of techniques to make sure their content ranked high on search engine results pages. We have seen the same effect with social media content recommendation algorithms, with bad actors using controversial and clickbait titles to cause engagement and have their content promoted.
However, while the previous problems could be mitigated by making changes to ranking algorithms, the effects caused by LLMs are much harder to detect and counter.
“Our evaluation suggests a ‘first mover advantage’ when it comes to training models such as LLMs,” the researchers write. This means that platforms and companies that have access to genuine human-generated text will have an advantage in creating high-quality models. After that, the web can become flooded by AI-generated content.
The researchers suggest taking measures to preserve access to the original data over time. However, it is not clear how to track and filter LLM-generated content at scale. This can become the focus of a new wave of innovations and competition between tech companies in the coming months and years.