
")



















This article is part of our coverage of the latest in AI research.
Salesforce Research, in collaboration with multiple universities, has released BLIP3o-NEXT, a new open-source model that unifies text-to-image generation and image editing within a single, streamlined architecture. Despite its relatively small size of 3 billion parameters, BLIP3o-NEXT demonstrates strong performance, matching or outperforming other open models on several key benchmarks.
Its intuitive design and open availability make it a promising foundation for developers looking to build custom generative AI applications or fine-tune models for specific use cases. As Ran Xu, Director of Applied AI Research at Salesforce and co-author of the paper, notes, the small model size and open-source assets make it an ideal starting point for customization. “If a startup has a specific use case or goal (such as generating layout of a design, generating planogram of a shelf) to be optimized, BLIP3o-NEXT provide a good framework to do RL to optimize the goal,” Xu told TechTalks.
How BLIP3o-NEXT works
BLIP3o-NEXT uses a hybrid architecture that combines an autoregressive model (the architecture used in classic language models) and a diffusion model (the architecture used in most image generation models). This two-stage approach leverages the distinct strengths of each component.
The autoregressive model acts as the brain, interpreting the user’s request and outlining the image’s overall structure and content. The diffusion model then acts as the artist, rendering the fine-grained, photorealistic details. The autoregressive model is based on Qwen3, while the diffusion transformer uses SANA1.5.
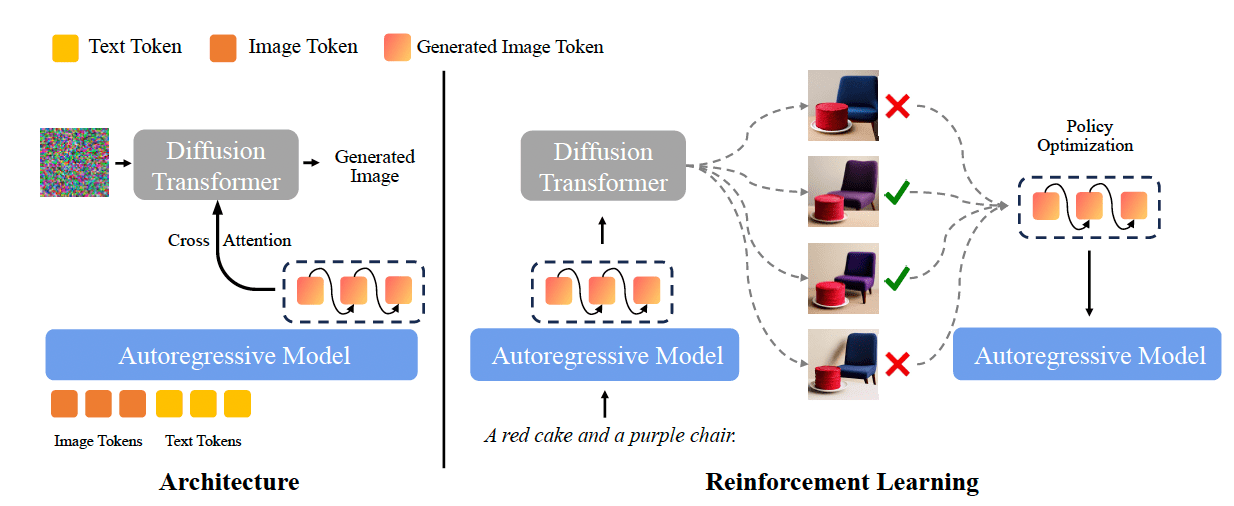
The autoregressive model’s main task is to process the user’s input—which can be a text prompt or a combination of text and reference images—and convert it into a sequence of discrete image tokens. Think of these tokens as words in a visual vocabulary that describe the core elements of the image. This approach differs from earlier models that generated continuous embeddings, which are more complex numerical representations.
The diffusion model then takes over, but it doesn’t just use the final discrete tokens. Instead, it uses their “hidden states” (the richer, more granular numerical data that the autoregressive model considered before settling on each final token). These hidden states provide a more detailed set of instructions, which the diffusion model uses as a conditioning signal to generate the final, high-fidelity image from an initial field of random noise.
Training for quality and consistency
The model’s core capabilities were developed by training the autoregressive component on three primary tasks: text-to-image generation, image reconstruction, and image editing. After this initial training, the researchers used reinforcement learning (RL) to further refine the model’s performance on specific skills, such as improving the quality of rendered text within images. For developers wondering how complex this is to implement for their own needs, Xu said, “I think it’ll be very easy to do.”

For image editing, maintaining consistency with the reference image is a major challenge, as high-level semantic representations can miss fine-grained pixel details. According to Xu, this is a key area where open-source models face a fundamental bottleneck. “Closed source models are likely to be trained with huge amounts of data, which requires significant infrastructure investment,” he explains. To compete, “we invested in innovation on new architectures and efficient training recipe, and open source the findings to benefit the research community.”
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
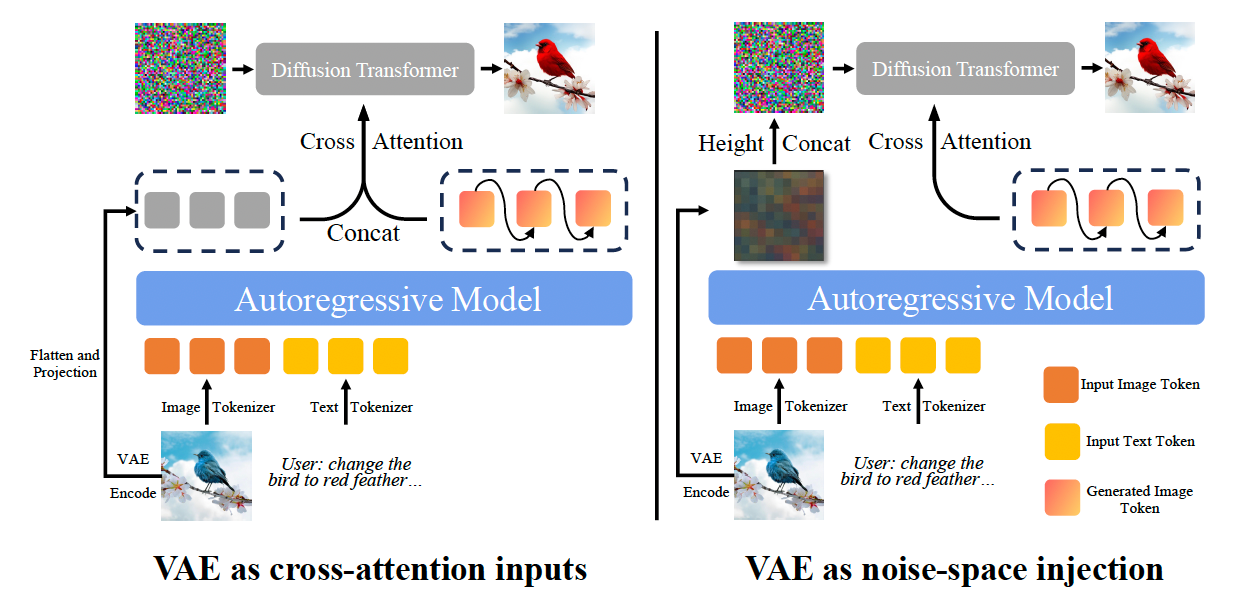
To address this challenge within these constraints, the team incorporated low-level VAE latents as an additional conditioning signal for the diffusion model. A VAE (Variational Autoencoder) can compress an image into a compact representation (its latent state) that preserves detailed visual information.
These VAE features from the reference image are integrated in two ways: they are combined with the hidden states from the autoregressive model, and they are also injected into the initial noise that the diffusion process starts with. This dual approach ensures that the generated image remains highly consistent with the original while accurately reflecting the user’s edits. This, combined with the strong multimodal reasoning of its autoregressive backbone, significantly improves BLIP3o-NEXT’s ability to follow complex instructions.
While the model shows impressive results, the researchers note there is still room for improvement, such as applying reinforcement learning more directly to image editing to further boost instruction following and consistency.
When asked whether the next breakthrough will come from better data or better reward models for RL, Xu sees an iterative path forward. “Data engine improvement provides a certain degree of certainty to improve the quality of the model, while RL is an active research field that may change the landscape significantly if there is a breakthrough,” he said.
In their paper, the researchers write, “Looking forward, we believe the findings presented here point toward promising directions for the next frontier of foundation models, where unified architectures, reinforcement learning, and scalable post-training jointly drive progress in controllable, instruction-aligned, and high-quality native image generation systems.”