




















This article is part of Demystifying AI, a series of posts that (try to) disambiguate the jargon and myths surrounding AI.
A shift is underway in how developers build applications with large language models (LLMs). OpenClaw creator Peter Steinberger recently accelerated this shift with a widely shared post stating that developers should stop prompting coding agents directly and focus instead on designing loops that prompt those agents.
This observation reflects a systemic change across AI engineering teams. Boris Cherny, who leads the Claude Code team at Anthropic, also validated this trend, noting that his role has shifted away from direct model prompting toward writing the external execution loops that coordinate model actions.
This movement is the continuation of an architectural lineage that began with ReAct-style reasoning loops in 2022, which combined reasoning and action steps to let models interact with external tools. This progressed through the open-source experiments of AutoGPT in 2023 and the emergence of the “Ralph loop” bash one-liner scripts in 2025.
By 2026, major development platforms productized these patterns, embedding “/goal” and “/loop” commands directly into tools like Codex and Claude Code. Today, the practice has matured into sophisticated orchestration networks featuring scheduled automations, specialized sub-agents, and git-backed data durability.
This evolution represents a functional paradigm shift. Prompt engineering focuses on micromanaging a single interaction or turn-by-turn conversation. Loop engineering shifts the developer’s focus to authoring the broader software assembly line, allowing the system to evaluate intermediate outputs, update its state, and determine its own next moves autonomously.
However, treating autonomous loops as a blanket replacement for human software design presents immediate risks. This is not “set and forget” magic. Poorly designed loops can balloon costs, erode observability, produce mode collapse, or pursue ill-defined goals inefficiently. They amplify engineering skill rather than replace it.
What is loop engineering?
At a macro level, an agentic loop is a structured program or scheduled automation that feeds context and instructions to an LLM, evaluates the resulting output against external criteria, and determines whether the task requires another iteration.
Instead of participating as an active conversationalist in a chat interface, the engineer builds the runtime environment that handles these cycles autonomously.
This allows systems to perform asynchronous tasks, such as overnight pull request optimization or multi-hour parameter benchmarking, without human supervision.
To move beyond basic text generation, these loops use recursion. In an agentic loop, the program repeatedly calls the LLM with updated states, feeding the model’s previous outputs back into its next instruction set until a designated objective is met.
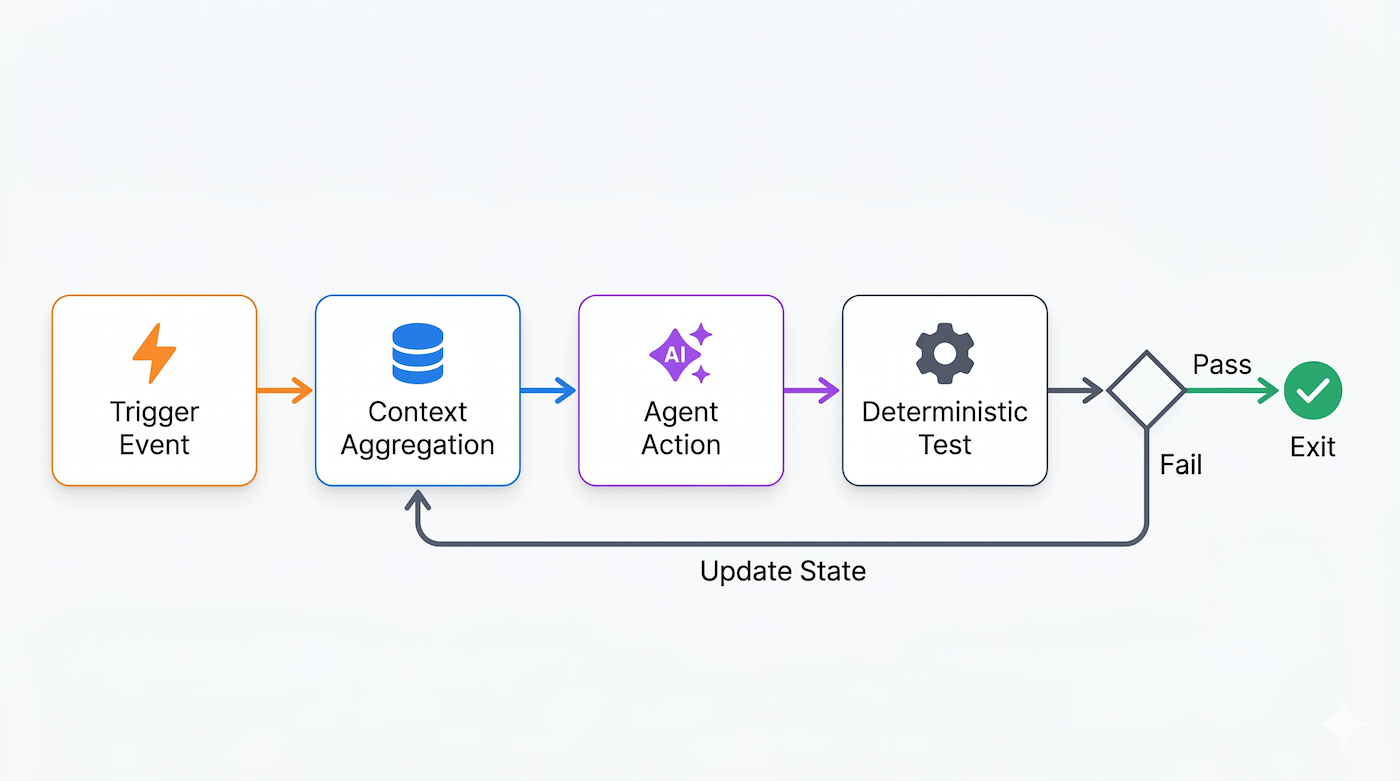
According to Addy Osmani, Director at Google Cloud, a functional AI loop depends on specific structural primitives: durable state tracking to maintain context across execution cycles, external plugins to interact with files or databases, and rigid operational guardrails. A production-ready loop requires a distinct operational trigger and a verifiable exit condition.
The difference between general orchestration frameworks and hyper-specific loops is visible in two prominent open-source projects:
OpenClaw: Created by Steinberger, this framework serves as an always-on general orchestrator. It uses a persistent “heartbeat” mechanism to call an AI agent on a fixed cycle. Instead of relying on hardcoded conditional branches, OpenClaw maintains a durable state database and built-in crash recovery systems. This design lets the agent evaluate repository states, supervise secondary sub-loops, and commit verified code changes while the engineering team is offline.
autoresearch: Developed by Andrej Karpathy, this project applies a tightly constrained loop to a singular, measurable task: machine learning experimentation. The agent modifies a PyTorch training script, executes a strict five-minute training run on a dedicated GPU, and reads the resulting validation loss metric. If the mathematical performance improves, the loop automatically commits the code to git. If the loss increases, the system rolls back the changes and restarts the cycle with fresh parameters.
Advanced implementations stack these loops hierarchically. A primary agent loop might generate actions, which are immediately passed to an isolated verification loop for grading, while a broader optimization loop tracks the long-term performance of the entire system.
Avoiding the loopmaxxing trap
The rapid adoption of autonomous loops is not without its setbacks and tradeoffs. There is a parallel between the current “loopmaxxing” trend and the earlier phase of “tokenmaxxing,” where developers assumed that simply expanding the model’s inference budget or sampling hundreds of raw completions would automatically resolve complex logic errors.
Loopmaxxing operates on a similar assumption: that running an agent through an infinite execution cycle will eventually produce a correct solution.
This approach fails when applied to subjective or unquantifiable goals. Instructing a loop to “improve the user experience of this login page” or “generate a viral marketing strategy” strips the system of a concrete exit condition.
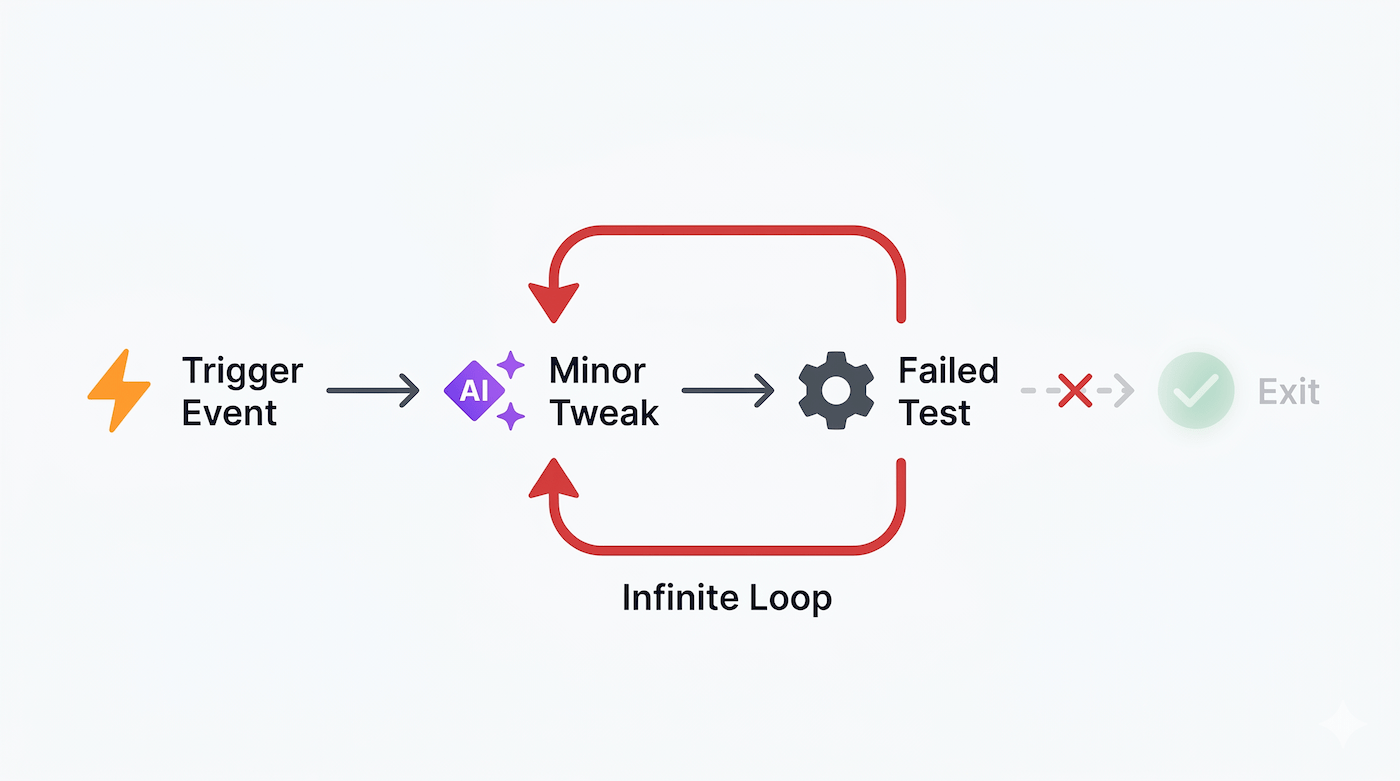
Because these goals lack binary pass/fail metrics, the model cannot calculate an accurate stopping point. The loop runs indefinitely, converting cloud infrastructure budgets into large API bills without advancing toward a measurable solution.
Even within deterministic environments like software engineering, unsupervised loops routinely encounter mathematical dead ends (aka local minima). For example, Karpathy himself admitted that in AutoResearch, when agents faced difficult open-ended optimization hurdles, they often became conservative and acted cagy. Instead of exploring bold architectural re-designs, the loop would oscillate back and forth, altering a learning rate by a fraction of a percent over dozens of cycles to achieve nominal, non-functional gains.
Unchecked automation also creates systemic overhead and creates a compounding risk of “comprehension debt.” When an automated loop modifies hundreds of lines of code across a repository unattended, the speed of software generation outpaces the engineering team’s capacity to review it. The human developers inherit a codebase where the underlying design decisions, structural dependencies, and edge cases are completely unmapped, making long-term maintenance and debugging difficult.
How to build a loop right: a phased approach
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
To use loop engineering safely in a production environment, you have to work step by step and separate the probabilistic and deterministic parts of your workflow to maximize reliability against unwanted errors.
1. Human-in-the-loop observation: Phase 1: Baseline monitoring.
Build the initial harness and context-gathering tools, but use explicit human approval for every code modification or external system action. This phase exposes where the agent’s logic fails and identifies the specific edge cases that cause the model to derail.
2. Introduce deterministic exits: Phase 2: Automated verification.
Replace human manual reviews with binary, automated validation engines where possible. The loop must hand off the agent’s output to standard compilers, syntax linters, or existing unit test suites. Where possible, the exit condition must rely on these deterministic software checks rather than asking the LLM to self-evaluate its own output.
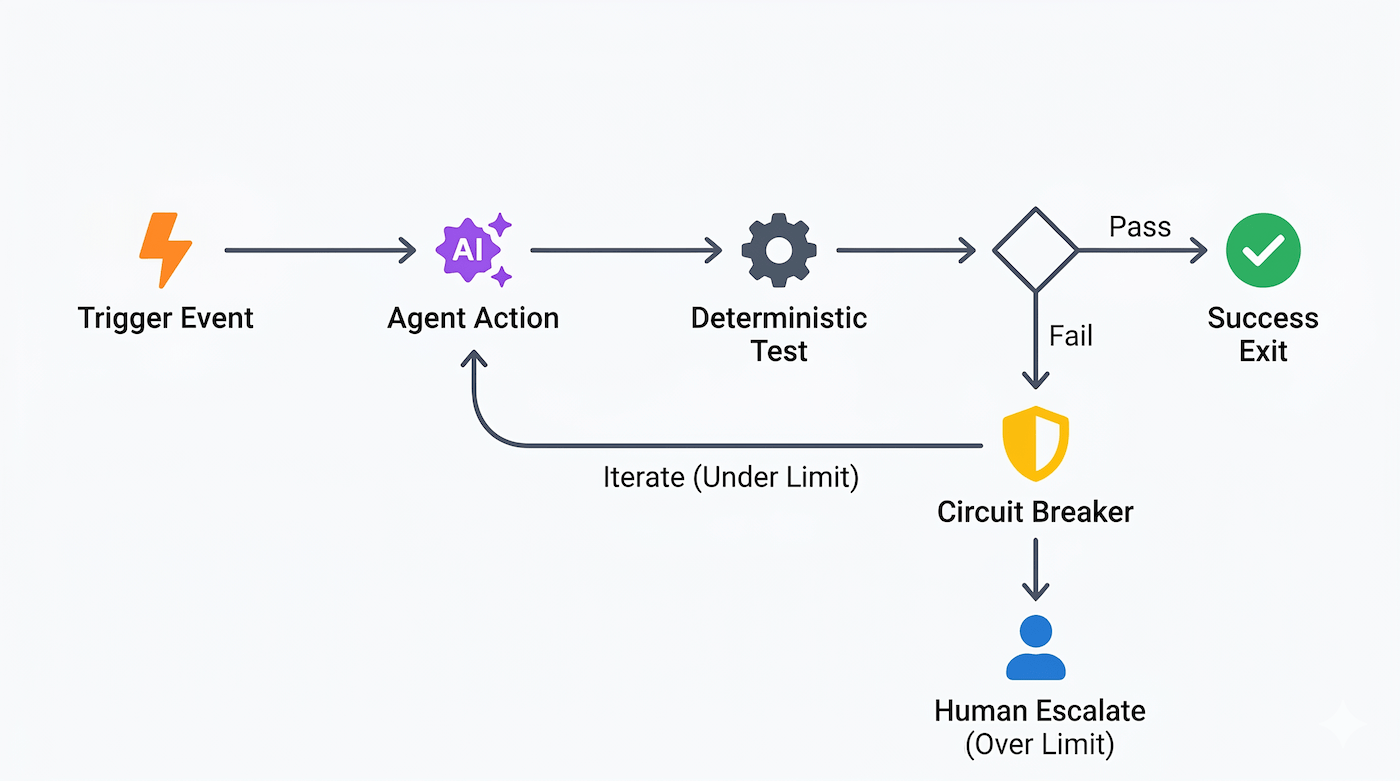
3. Implement stagnation circuit breakers: Phase 3: Cost and loop control.
Add strict monitoring code to track systemic progress across execution cycles. If the system detects that the agent is alternating between identical file states, repeating identical console errors, or failing to make measurable progress over three consecutive runs, the software must trip a circuit breaker, terminate the loop, and alert an engineer.
4. Distill and demote: Phase 4: Algorithmic optimization.
Analyze the execution logs of the stabilized loop to identify predictable, repetitive behaviors. If the agent consistently uses the LLM to perform identical text-parsing or structural refactoring tasks, strip those steps out of the non-deterministic prompt and rewrite them as standard, compiled script execution blocks within the main software harness.
The point of proper loop engineering is acknowledging a key limitation of LLMs. They can perform many tasks but are not necessarily the best and most reliable tool for each of them. By adding deterministic code and human oversight where the agent can fail, you get the benefit of agentic loops while avoiding their pitfalls.
Build the loop, stay the engineer
Loop engineering formalizes the reality that large language models are components within a broader software system, not standalone applications. The efficiency of an autonomous agent is determined entirely by the deterministic constraints, testing harnesses, and execution guardrails designed by the engineer.
No volume of recursive loop cycles can salvage a poorly specified objective or an unprincipled software architecture. As automation frameworks handle a larger share of routine code generation and exploratory tasks, the core responsibility of the developer shifts. Success no longer depends on finding the perfect string of adjectives for a text prompt, but on building the robust verification systems that keep autonomous loops tracking toward a verifiable destination.