


")
















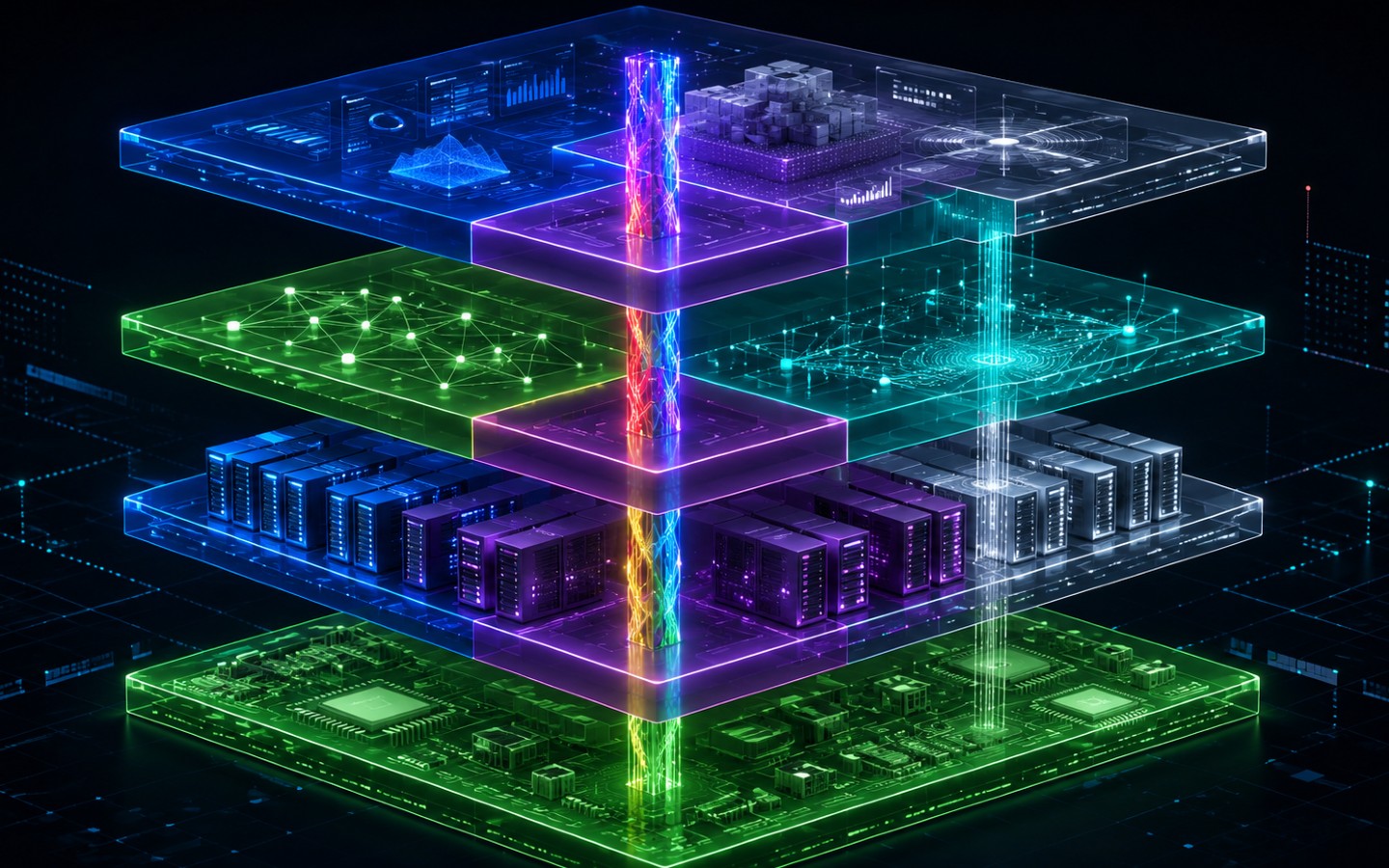
The artificial intelligence arms race has shifted from a one-dimensional battle over model intelligence to a multi-layered infrastructure war. It is now evident that securing a foothold in a single layer of the AI stack is insufficient to survive the cut-throat nature of the race or the margin compression of the AI economy.
The modern AI stack consists of four key layers. At the base is the hardware, the physical accelerators and GPUs that process data. Above that sits the compute cluster, comprising the cloud servers and gigawatt data centers that house the hardware. Next is the model layer, featuring the foundational architectures like Claude and GPT. Finally, the application layer encompasses the end-user interfaces like ChatGPT and Cursor.
Dominating a single layer is no longer a viable long-term moat. The most successful companies in the space are actively diffusing into the layers above and below their starting points to protect their margins and capture new value.
Here is how the competitive landscape is taking shape.
Model-first: the brutal reality of hardware costs
Pure model-first companies are being forced down the stack into hardware and compute to protect their margins and scale their training capabilities. Developing a frontier model requires billions of dollars in upfront compute, but inference is where the real margin crush happens.
To escape the premium pricing of Nvidia GPUs, OpenAI is partnering with Broadcom to launch Jalapeño, its first custom AI inference chip. Targeted for deployment by the end of 2026, this move proves that even the premier software lab must build custom silicon to sustain its operations at scale.
Anthropic faced a similar infrastructure bottleneck. The company realized it could not rely solely on traditional hyperscalers to meet its energy demands. Training the next generation of models requires power grids that legacy cloud providers cannot provision fast enough. In response, Anthropic signed a $50 billion infrastructure partnership with neocloud provider FluidStack. Neoclouds are specialized providers focused purely on AI compute, offering rapid deployment unencumbered by legacy enterprise services. Together, they are building custom multi-gigawatt data centers in Texas and New York.
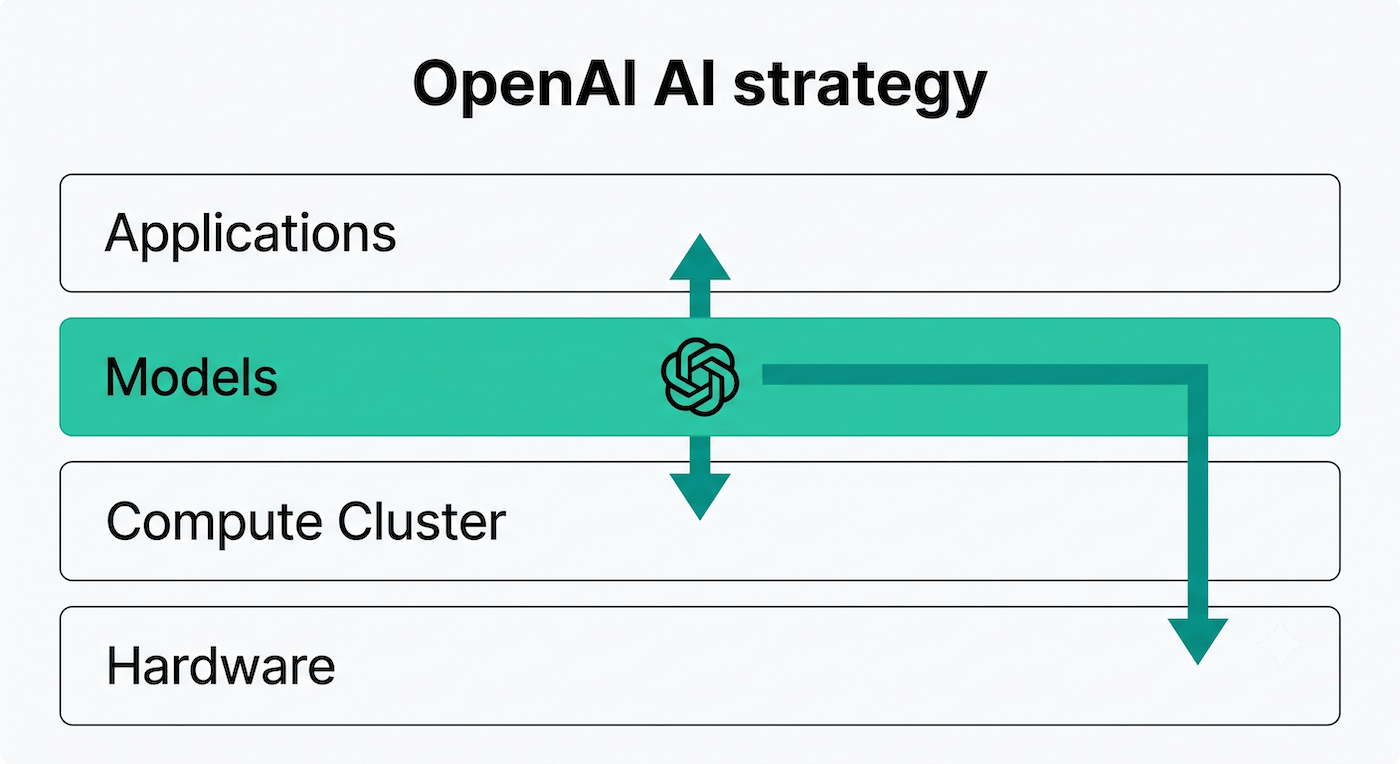
While Anthropic partnered with external providers, xAI bypassed the cloud entirely. While its Grok models have not yet become a serious contender to ChatGPT and Claude (though Grok is my favorite fast research tool), it has turned itself into an AI infrastructure behemoth. By building the Colossus supercomputer, xAI turned its parent company, SpaceX, into a hyperscaler in its own right. SpaceX now controls its infrastructure from the ground up and rents compute capacity to other industry players, including Anthropic, which is paying $1.25 billion per month for access to Colossus.
Application-first: capturing value at the edge
Analysts often dismiss application-layer companies as mere “wrappers”: thin interfaces built over third-party APIs that are destined to be wiped out when frontier labs release native features. The trajectory of AI coding assistant Cursor proves that UX data and deep workflow integration form a massive, defensible moat.
Cursor started as an Integrated Development Environment (IDE) that allowed developers to route prompts to various frontier models. By processing millions of coding sessions, Cursor accumulated an immense dataset of user behavior and highly specific interaction patterns. They created Composer 2.5, a fine-tuned version of the open-weights Kimi K2.5 model.
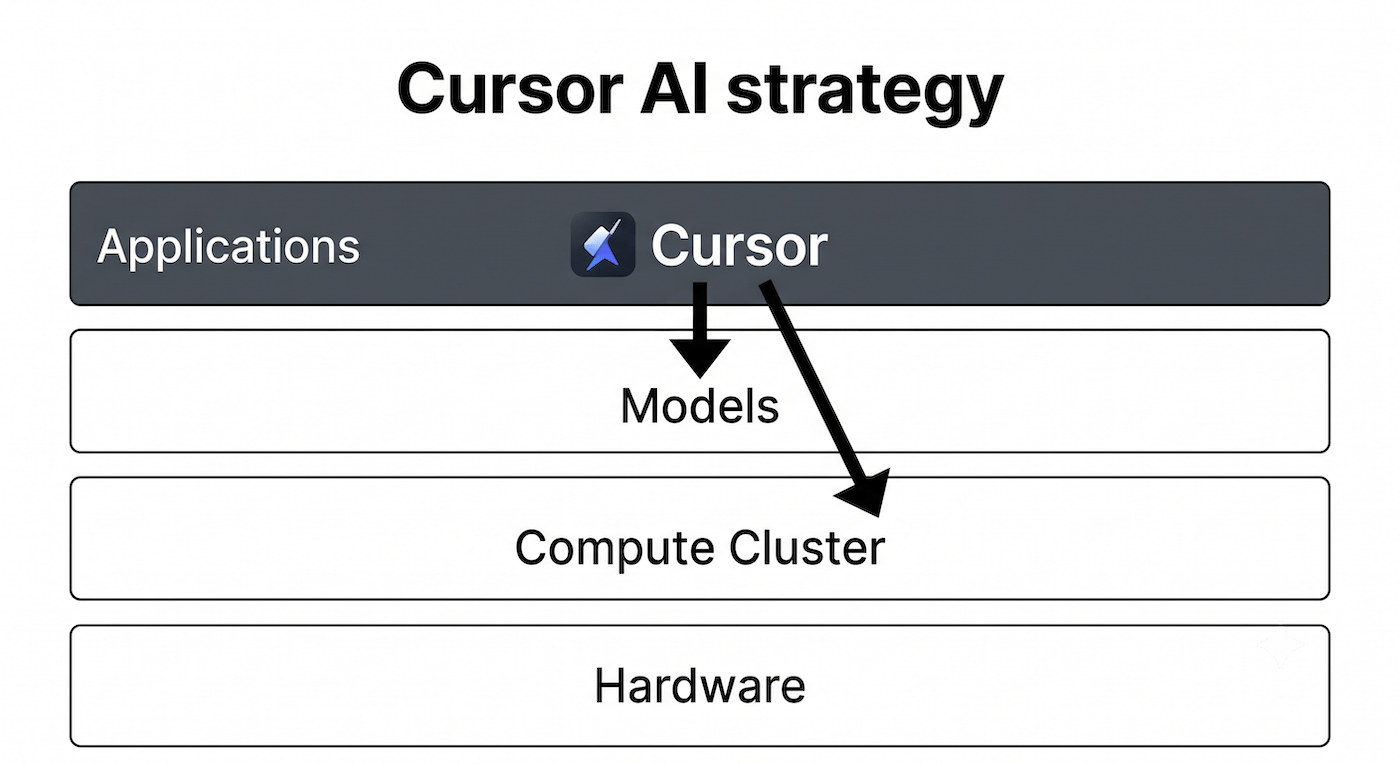
By training Composer 2.5 on their own UX data, Cursor built a faster, cheaper, in-house model that reduced their dependence on expensive frontier APIs for everyday tasks. Developers now use Composer 2.5 for standard implementation while reserving expensive frontier models for complex architectural reasoning.
This deep workflow integration makes application-layer companies highly attractive to base-layer compute giants desperate to secure user touchpoints. In June 2026, SpaceX acquired Cursor developer Anysphere in a $60 billion all-stock transaction. The acquisition illustrates how companies with massive infrastructure are reaching all the way to the top of the stack to ensure they have an outlet for their compute.
Cloud-first: leveraging infrastructure for app dominance
Traditional hyperscalers like Amazon and Microsoft initially used their massive compute capacity to attract AI labs. Along with Google (more on Google in a bit), they are the main providers of AI compute, with each having serious stakes in at least one of the leading AI labs (Microsoft in OpenAI, Amazon in Anthropic, and Google owns DeepMind).
But being a provider of compute is not enough. The hyperscalers are are now aggressively expanding both up into software and down into custom silicon.
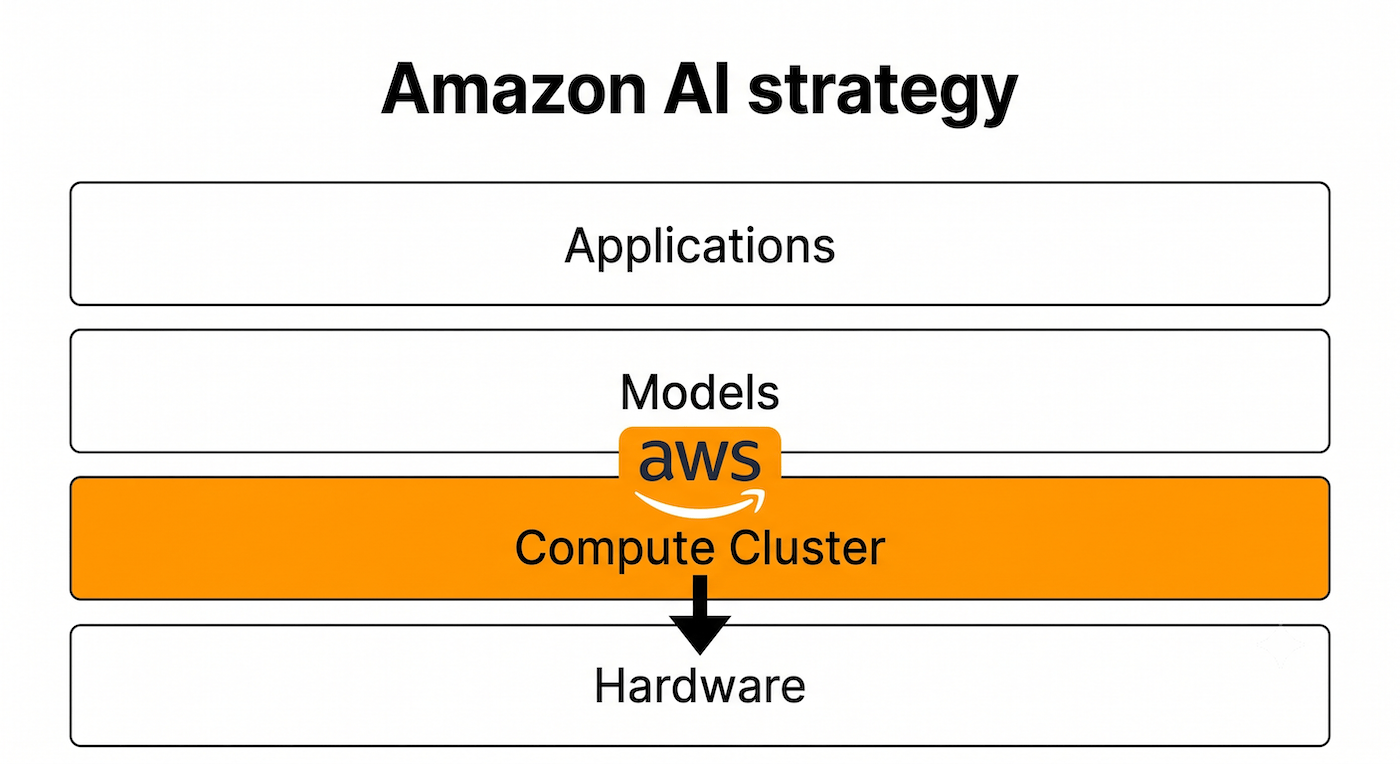
Amazon developed its custom Trainium and Inferentia chips to build a proprietary hardware moat beneath AWS. By offering its own silicon, Amazon reduces its dependency on third-party hardware suppliers and offers better profit margins to developers building on its cloud.
Microsoft took a different path. While it failed to become the definitive frontier model lab itself, its massive distribution network via Windows and Microsoft 365 allows it to capture immense value at the application layer. Integrating AI directly into enterprise workflows gives Microsoft a permanent pipeline to users regardless of who wins the model race.
To bridge the gap between their Azure compute power and their consumer application suite, Microsoft is also steadily releasing new AI models, including the open weights Phi family and the closed MAI models. While its flagship MAI models are not on par with the absolute frontier, it could be a similar play to Cursor, enabling Microsoft to provide its users with faster and cheaper alternatives to the likes of Claude Opus 4.8 and GPT-5.5.
Hardware-first: Nvidia’s trojan horse
Nvidia dominates the physical base layer of the stack. It has become the most valuable company in the world by selling the very expensive shovels that power today’s AI models.
If you enjoyed this article, please consider supporting TechTalks with a paid subscription (and gain access to subscriber-only posts)
However, the company is quietly moving up to the model layer to ensure long-term hardware utilization and defend against custom application-specific integrated circuits (ASICs) like Jalapeño or Trainium.
In late 2025, Nvidia released the Nemotron 3 suite as fully open-source, providing the weights, training data, and recipes to the public. This is rare in the field, especially in the U.S. Even Chinese labs that regularly release open-weights models don’t provide the data and other artifacts that would make the LLM fully open source.
Nvidia can do it because it is particularly positioned to become the king of open source AI. While software labs bleed money open-sourcing models they spent billions of dollars training, Nvidia directly profits from open models.
The proliferation of open-source AI drives immense demand for physical compute. If any developer can download a frontier-level model, they immediately need hardware to run it. If companies want to create a custom AI model for their applications, they will prefer a fully transparent and open source LLM. And again, fine-tuning requires tons of compute and AI accelerator power.
By releasing high-quality open models, Nvidia ensures that the ecosystem continues to scale on its GPUs rather than migrating to proprietary closed systems running on custom silicon. Furthermore, controlling both the hardware and the model allows Nvidia to co-design them, optimizing Nemotron models to run with unmatched efficiency on their own chips.
Everything, everywhere: the Google juggernaut
Google is the only player that is entirely native to all four layers of the stack simultaneously. Its Tensor Processing Units (TPU) is arguably the strongest contender to Nvidia chips, giving it a strong foothold in the hardware layer. Its Google Cloud Platform (GCP) is one of the top-3 providers of AI compute. Google Gemini is among the leading AI model families. And at the application layer, it has massive distribution through not only the Gemini app but also its Search and Workspace suite.
This vertical integration creates an unbeatable data flywheel. Google’s billions of daily user interactions tightly couple their application layer back to their model training layer. The telemetry and behavioral data generated at the application layer directly feed the training pipelines for the next generation of models, which are then processed on Google’s proprietary hardware.
The ecosystem pivot: where is Meta?
If Google represents total vertical integration, Meta’s initial strategy was a targeted strike: commoditize your complement. Meta gave away its Llama models as open-source weights, effectively scorching the earth at the model layer so competitors like OpenAI and Anthropic could not tax Meta’s massive consumer app distribution across Facebook, Instagram, and WhatsApp.
This strategy failed to create a permanent moat. Giving away frontier models accelerated the entire field, but it compressed Meta’s own advantage window. Competitors used Meta’s open weights to bootstrap their own models. Rivals rapidly matched and exceeded Meta’s capabilities using the company’s own research.
This dynamic culminated in the 2025 Llama 4 benchmark controversy, leading Meta to officially abandon its pure open-source dogma. In April 2026, the company released Muse Spark, a proprietary, completely closed-source multimodal model designed specifically for monetization. Meta’s trajectory proves that bottomless funding and massive compute do not guarantee success if you give away your foundational layer to your competitors.
The blurring lines
The AI race remains highly volatile, and no two successful companies look exactly alike. They either leveraged different starting positions or expanded in radically different directions.
The lines between the stack layers are permanently dissolving. If you start at the model, you have to build hardware to survive the costs. If you start at hardware, you have to build models to drive usage and avoid being commoditized. If you start at applications, you have to fine-tune your own models to protect your margins. A single layer is not enough to survive. The ultimate winner will be the entity that can vertically integrate the most layers.