



")
















This article is part of our series that explores the business of artificial intelligence
With many industries interested in using machine learning algorithms to improve efficiency and reduce the costs of their operations, ML products have become one of the main competition fronts between big tech companies. The past few years have seen an assortment of services that facilitate the creation, training, fine-tuning, and deployment of machine learning models for different organizations.
Not to be outdone by others, Amazon announced new machine learning products at the AWS re:Invent conference this year, including a no-code ML tool, a data-labeling platform, and a service for optimizing the deployment of machine learning models. The benefits of the new tools are two-fold. For organizations that don’t have the in-house talent and resources to develop their own ML models, these tools will give them the opportunity to get started with machine learning and put their data stores to productive use. For organizations that are already running machine learning projects, the new applied ML tools will provide the opportunity to increase the speed and productivity of the machine learning development cycle.
No-code machine learning
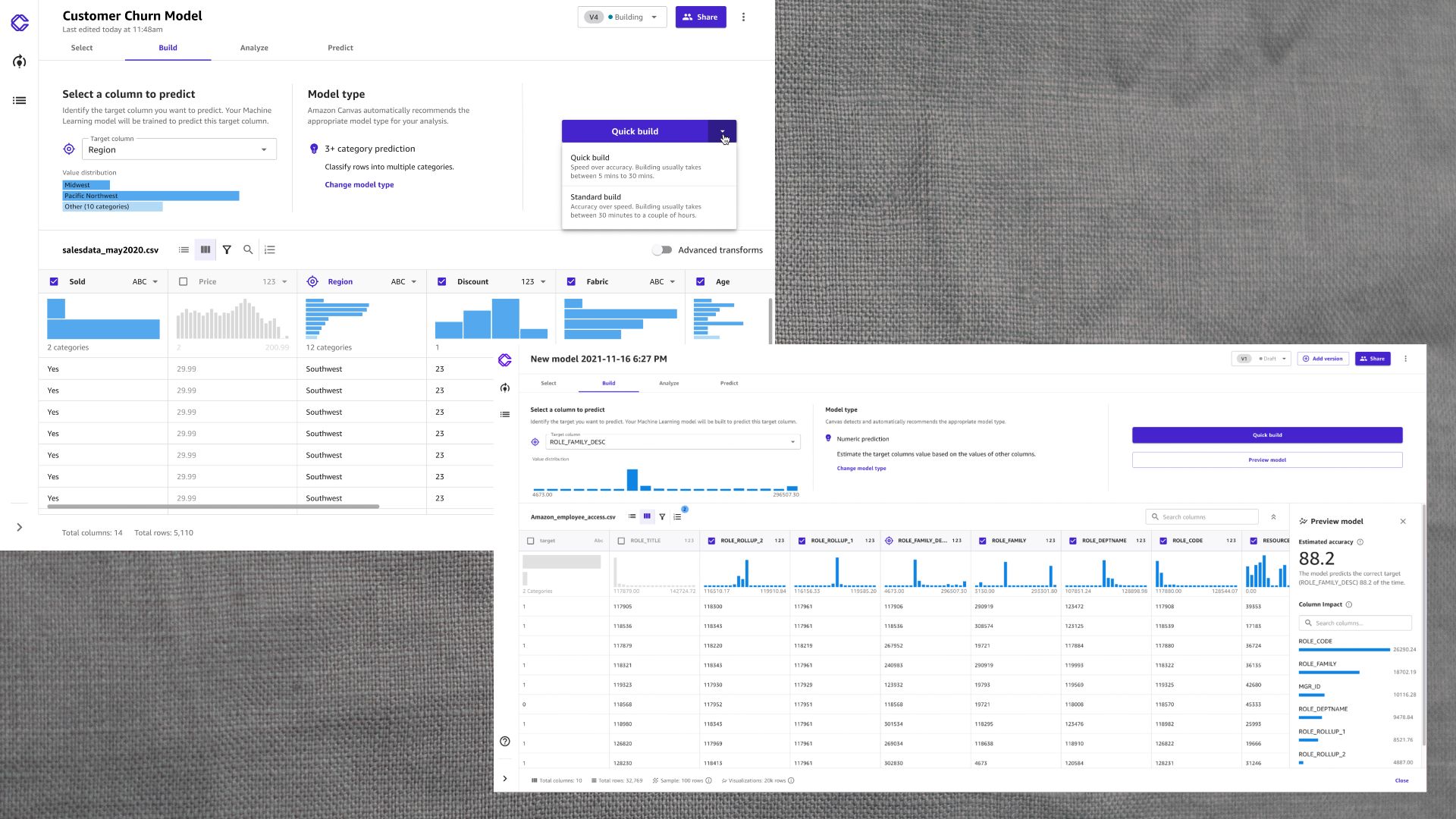
For me, the most exciting announcement was Canvas, a no-code interface for SageMaker, AWS’s machine learning development platform. Canvas is a visual tool that lets you manage the entire machine learning pipeline without writing any code. If you have a basic understanding of the elements of machine learning, you’ll be able to use Canvas to create, train, and test your own models.
Behind the scenes, SageMaker Canvas takes care of much of the details, including cleaning and consolidating data, testing different models and algorithms, and running single or batch predictions.
Like all machine learning applications, in Canvas you start by importing your data. Canvas supports files directly uploaded from your computer, stored in the Amazon S3 cloud, or residing in data lakes and warehouses such as RedShift and Snowflake.
If you import multiple files, Canvas helps you merge them into a single dataset and extract information such as means, data types, and missing and invalid values for each column. Canvas will automatically fill in the blanks if you don’t manually adjust them.
Once your dataset is ready, you can create a supervised ML model by choosing a target column to predict. Canvas automatically detects the type of machine learning task you’ll need (binary/multiclass classification, regression). It also provides important information such as the relevance of each of your dataset’s columns to the target value, which is very useful for dimensionality reduction and model optimization.
After preparing the data and objective, Canvas starts training hundreds of different ML models, testing different algorithms and hyperparameters until it finds an optimal solution to the problem.
Once the ML model is ready, Canvas reports the accuracy along with additional metrics, including precision, recall, and F1 score. You can also see the confusion matrix for the model, which reports the false positive and negative rates of different classes.
You can directly test the model in Canvas to make single or batch predictions. You can also import the model in SageMaker Studio and integrate it into other ML products.
Canvas is a great tool for organizations that don’t have in-house machine learning talent because and want to go from raw data to a workable model without writing a line of code. It is also useful for seasoned machine learning coders because it removes the frustration of manually coding the data analysis, model preparation, and training process. Finally, it is already part of a working product, which means it will become available to many product teams without requiring them to change infrastructure or workflows.
Faster data labeling for machine learning models
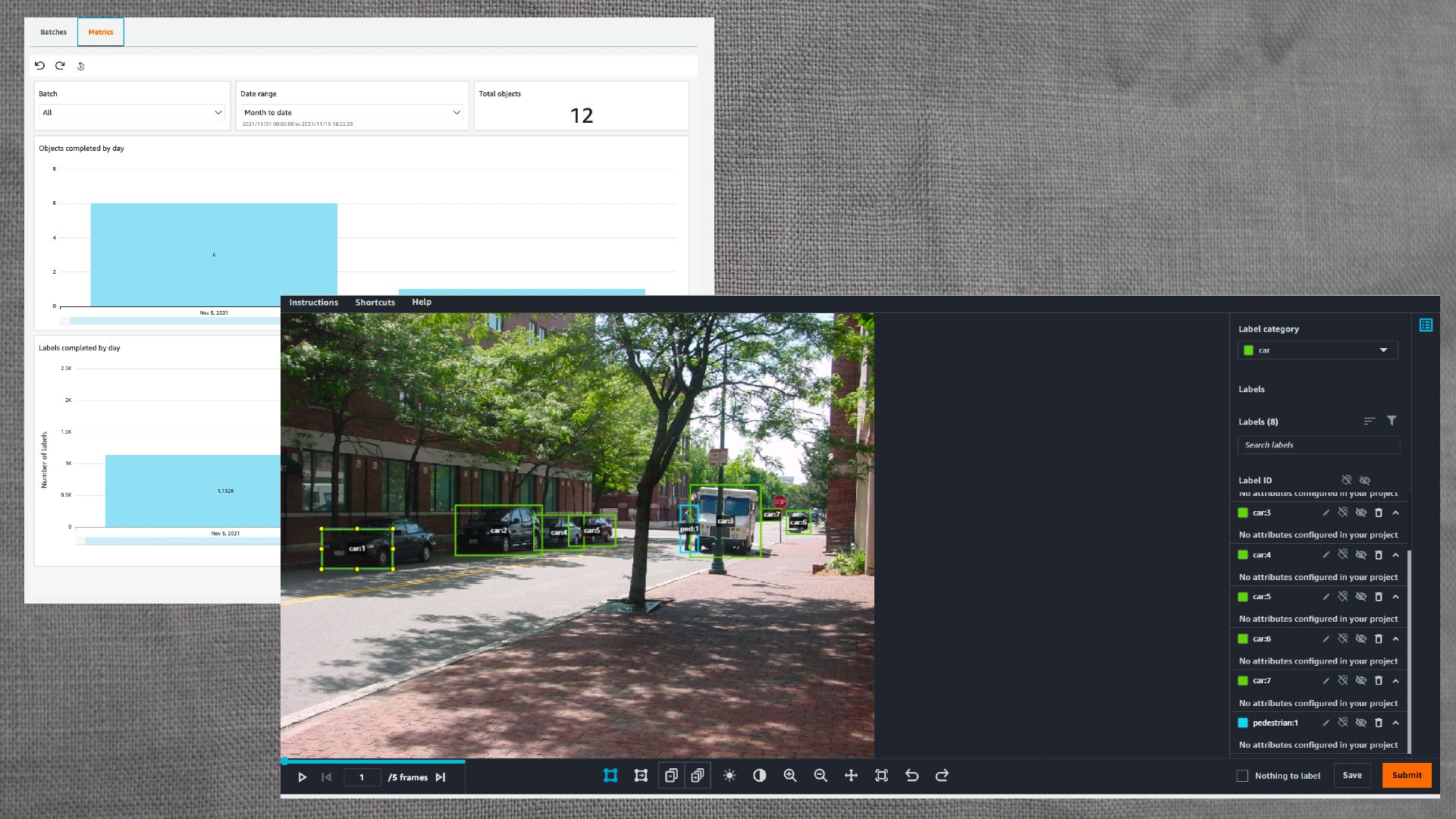
One of the key challenges of supervised machine learning is data labeling. Annotating training data with the ground truth takes enormous energy and sometimes requires complicated workflows and the hiring and management of a large data-labeling workforce.
To address these challenges, Amazon has announced Ground Truth Plus, a service that alleviates much of the effort required to create labeled training datasets for machine learning models. Like Canvas, Ground Truth Plus is part of the SageMaker product, which means it becomes available to Amazon customers who are already using the ML development suite.
You provide Ground Truth Plus with your raw data and labeling requirements, and it manages the process for you. Behind the scenes, Amazon takes care of the annotation process through an expert workforce that specializes in the use case you specify. Amazon complements the efforts of the human annotators with machine learning models that automate the labeling process. The ML models pre-labels the datasets, which reduces the amount of manual labor required in the annotation process. As the labeling process progresses, the ML models become better at labeling, and the manual labeling gradually becomes a review and adjustment process.
While labeling is underway, you can monitor the progress through the Ground Truth Plus Project Portal. According to Amazon, Ground Truth Plus reduces the costs of data labeling by up to 40 percent.
This tool ties in well with Canvas as it reduces the need for in-house talent or the management of an outsourced workforce. It will make it easier for small organizations to start applied machine learning projects.
Reducing the costs of deploying machine learning models
When deploying machine learning models, you must select a compute instance that delivers your model in a scalable and cost-efficient way. Managing the compute stack is a complicated process that often requires weeks of experiments and can involve unwanted failures.
SageMaker Inference Recommender, a new service announced at re:Invent, reduces the complexities of the ML deployment process. Based on your ML model and requirements, Inference Recommender provides suggestions on which types of Amazon compute instance will best serve the needs of your application. You can then immediately deploy your ML model on one of the recommended compute instances.
Inference Recommender has several other features, such as load-testing ML models in simulated environments and setting constraints such as required throughput and latency. This makes it much easier to assess the performance of the ML model and compute instances before deploying your application to production.
Inference Recommender can be a great tool for companies that don’t have engineers with years of experience tinkering with different cloud computing infrastructures. It can also assist experienced MLOps engineers who want to speed up the process of deploying machine learning models.
Amazon is one of several companies that are directing their focus toward bringing machine learning to talent and resource-constrained industries. With machine learning becoming easier and more available, it will be interesting to see what new applications will emerge in the coming months and years.