



")
















This article is part of our coverage of the latest in AI research.
Advances in computing have been a boon to deep learning research. Thanks to near-limitless cloud computing resources, GPU clusters, and specialized AI, researchers have been able to design, train, test, and tweak deep neural networks at speeds that were previously impossible. Along with the ingenuity of a growing number of scientists, this speed and efficiency have helped usher in some of the most successful trends in deep learning in the past decade.
But at the same time, there is growing interest in bringing the latest deep learning innovations to TinyML, the branch of machine learning focused on resource-constrained environments that don’t have a connection to the cloud.
One of these innovations is the self-attention mechanism, which has become one of the key components in many large deep learning architectures.
In a new paper, researchers at the University of Waterloo and DarwinAI introduce a new deep learning architecture that brings highly efficient self-attention to TinyML. Called “double-condensing attention condenser,” the architecture builds on previous work that the team has done and is promising for edge AI applications.
Self-attention in TinyML

Classic deep neural networks are designed to process one piece of information at a time. However, in many applications, the neural network must process and consider the relations between a sequence of input data before producing a prediction. The most obvious use case for this is natural language processing, where the meaning of a word depends on what comes before or after it. Self-attention is also used in other types of applications, including computer vision and speech recognition.
Self-attention is one of the most efficient and successful mechanisms for addressing relations between sequential data. It is used in transformers, the deep learning architecture that is behind large language models such as GPT-3 and OPT-175B. But it can also be very useful for TinyML applications.
“With the increasing demand for TinyML to drive an enormous range of real-world applications such as manufacturing/industry 4.0, my teams at DarwinAI and Vision and Image Processing Research Group have continuously strived to create increasingly smaller and faster deep neural network architectures for the edge to power such applications,” Alexander Wong, Professor at the University of Waterloo and Chief Scientist at DarwinAI, told TechTalks. “Seeing the exponential rise of self-attention in deep learning, we were curious as to whether we can bring the idea of self-attention and realize it in a way that increases both efficiency and performance in the realm of TinyML on the edge, thus reducing the typical tradeoff between richer attention and increased real-world complexity.”
In 2020, Wong and his colleagues published introduced “attention condensers,” a mechanism for enabling highly efficient self-attention neural networks on edge devices.
“The main idea behind the original attention condensers was to create a new type of self-attention mechanism that jointly models local and cross-channel activation relationships within a unified condensed embedding and performs selective attention using this,” Wong said.
The attention condenser takes multiple feature channels (V) and compresses them (through C) into a single embedding layer (E) that represents the local and cross-channel features. This is a dimensionality reduction technique that forces the neural network to learn the most relevant features of its input space. The attention condenser block then decompresses the embedding (through X) to reproduce the input sequence with the self-attention information integrated into it (A). The network can then combine the original features and the self-attention information for new purposes.
“This condensation of joint local and channel attention allows for a very rich yet efficient understanding of what to focus on within the input data, thus allowing for a much more lightweight architecture design to be achieved,” Wong said.
In the paper, the researchers also introduced TinySpeech, a neural network that used attention condensers for speech recognition. Attention condensers showed great success across manufacturing, automotive, and healthcare applications, according to Wong. However, the original attention condensers had certain limits.
“One shortcoming of the original attention condenser is that there was an unnecessary asymmetry between the feature branch and the attention condensation with the feature embedding being more complex than it really needed to be,” Wong said.
Double-condensing attention condensers

In their new paper, Wong and his colleagues introduce the “double-condensing attention condenser” (DC-AC) self-attention mechanism. This new architecture addresses the asymmetry problem that the original attention condenser suffered from by using attention condensers on both branches of computation. The added attention condenser mechanisms enable the neural network to learn even more representative feature embeddings.
“By introducing this double-condensing attention condenser mechanism, we were able to greatly reduce complexity while maintaining high representation performance, meaning that we can create even smaller network designs at high accuracy given the better balance,” Wong said.
The researchers designed a neural network architecture that uses DC-AC blocks for self-attention. The network architecture is called AttendNeXt and is composed of four branches of computation, each of which uses a series of convolutional layers and DC-AC blocks. It then passes through a series of blocks consisting of DC-AC blocks, anti-aliased downsampling layers, and convolutional layers.

The columnar architecture of the network enables different branches to learn disentangled embeddings in the early layers. In the deeper layers of the network, the columns merge and the channels gradually increase, enabling the self-attention blocks to cover wider areas of the original input.
Instead of manually creating AttendNeXt, the researchers used neural architecture search to explore different network configurations.
“The machine-driven design exploration algorithm is generative synthesis, which is a generative strategy that we introduced for high-performance neural architecture search given different operational constraints based on the interplay between a generator trying to generate better network architectures and an inquisitor that studies the generated architectures,” Wong said.
The search algorithm was given four constraints, including columnar architectures, point-wise strided convolutions (to prevent information loss in residual blocks), the use of anti-aliased downsampling, and comparing performance against current state-of-the-art TinyML architectures.
“The four constraints are what we call ‘best practices’ design constraints that steer the exploration process based on what has been previously found in literature to improve performance/robustness as well as the level of accuracy we want to achieve,” Wong said.
Improved performance
The researchers’ findings show that AttendNeXt “possesses a strong balance between accuracy, architectural complexity, and computational complexity, making such an architecture well-suited for TinyML applications on the edge.”
In particular, AttendNeXt’s throughput shows significant improvement over other TinyML architectures, which can be crucial for applications that require high-frequency and real-time inference.
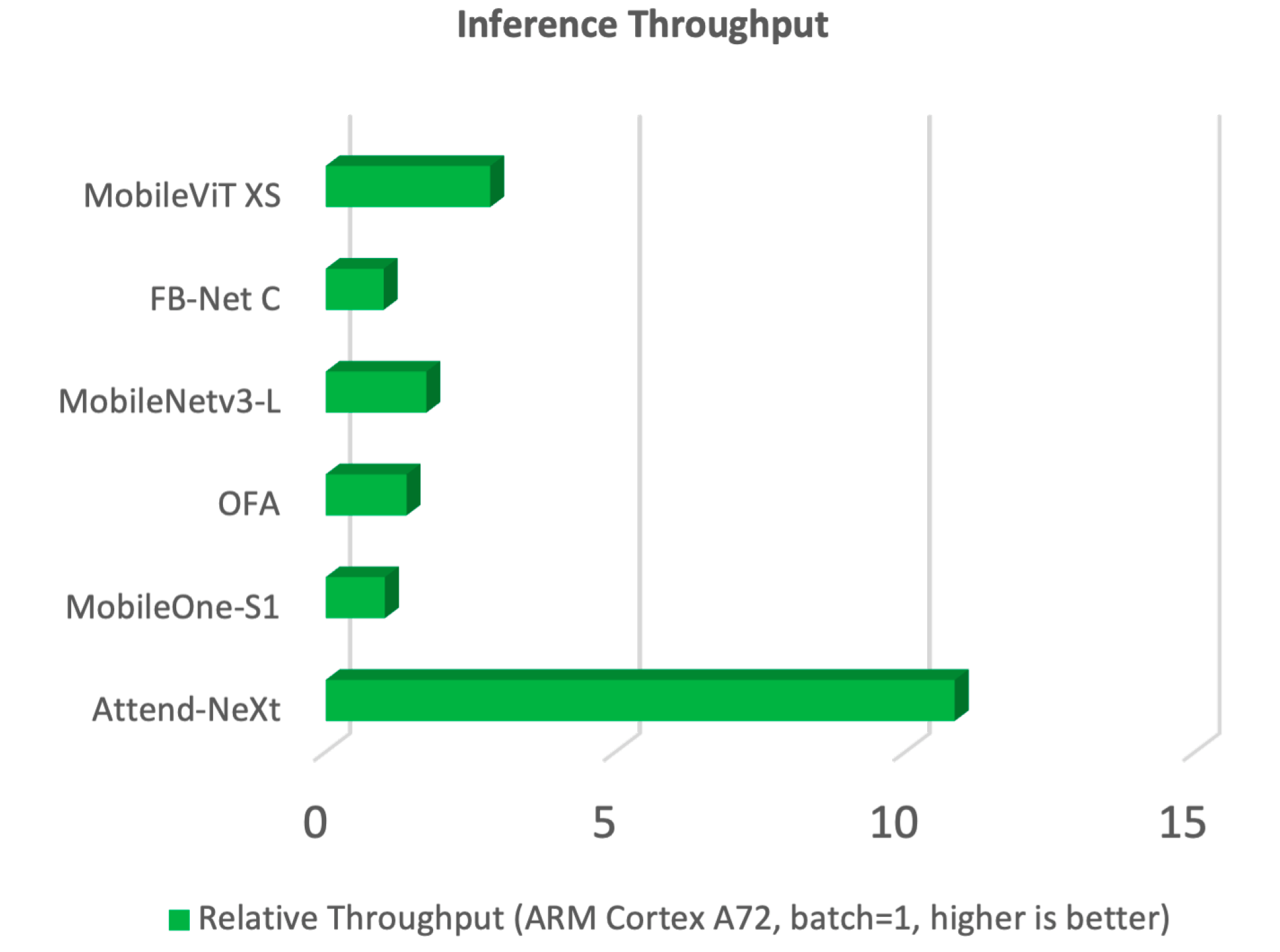
“AttendNeXt can be applied to a wide range of applications, with visual perception tasks on the edge being especially well suited for using it (e.g., high-throughput manufacturing visual inspection, autonomous vehicles, vision-driven manufacturing robotics, low-cost medical imaging devices, smartphone apps, etc.),” Wong said.
The researchers hope that exploring different efficient architecture designs and self-attention mechanisms can lead to “interesting new building blocks for TinyML applications.”
“We want to explore leveraging this new self-attention mechanism within the machine-driven design exploration paradigm to generate optimal network architectures for different manufacturing visual inspection tasks involving classification, object detection, semantic/instance segmentation, etc. running on embedded devices, as well as exploring its efficacy on non-visual modalities (e.g., acoustic),” Wong said. “And as usual, we are continuing to explore new attention condenser designs in the quest for great efficiency-accuracy balance.”