



")
















This article is part of our coverage of the latest in AI research.
There’s growing interest and concern about the security of machine learning models. Experts know that machine learning and deep learning models, which are used in many kinds of applications, are vulnerable to adversarial attacks.
But finding and fixing adversarial vulnerabilities in ML models is easier said than done. There has been a lot of research in the field in recent years, but most of it has been focused on ML models that process visual data.
We’re seeing the growing use of ML in applications such as network data analysis, fraud detection, and spam filtering, which use tabular and text data. Unfortunately, many of the techniques used to discover adversarial attacks against computer vision systems do not apply to these other types of data.
Meanwhile, the study of adversarial attacks on these data types has mostly failed to produce generalized tools and approaches to create robust ML models.
In a new study presented at the International Joint Conference on Artificial Intelligence (IJCAI) 2022, scientists at the University of Luxembourg presented new techniques that can help find adversarial attacks and defenses for these other applications. The research can help find systematic ways to address adversarial vulnerabilities in machine learning systems.
Adversarial attacks in constrained feature spaces
Adversarial attacks are small perturbations to model inputs that manipulate the behavior of machine learning systems. In the following example, small changes made to the pixel colors of the image cause an image classifier to change its output. Adversarial attacks can have severe security repercussions in applications where machine learning is used for sensitive functions, such as authenticating users or detecting malicious network traffic.
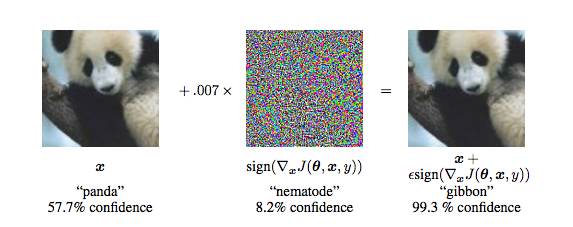
To be effective, adversarial perturbations must be small enough to keep the modified data within a valid range, or “domain constraints.” In computer vision, these constraints are fairly loose, only requiring the adversarial perturbations to be imperceptible to a human observer.
“In computer vision, any reasonably small perturbation of an image yields a valid image (which would still look the same to human eyes),” Maxime Cordy, research scientist at the University of Luxembourg and co-author of the new paper on adversarial attack and defense, told TechTalks. “By contrast, perturbing text can easily cause syntax errors (spelling or grammar) or create semantic inconsistencies. The same goes for many other domains like finance or malware security.”
The nature of these other applications imposes stricter constraints on the features, which makes it very difficult to create adversarial examples through random perturbations. Since much of the research on adversarial machine learning is done on computer vision systems, the adversarial attacks are based on generic techniques that do not consider the constraints of the target system. Therefore, they are not applicable to ML models that process other kinds of data.
Previous studies that Cordy and his colleagues have conducted demonstrate that adversarial attacks unaware of these constraints mostly produce infeasible examples.
The research team from the University of Luxembourg has been doing research on adversarial machine learning for several years. At the same time, they have been working with industry partners and investigating the adversarial robustness of machine learning models used in real-world applications.
“We conducted an empirical study on real-world financial ML models and realized that adversarial attacks needed to be aware of ‘domain constraints’ in order to produce valid inputs,” Cordy said. “Through our analysis of the literature, we became aware that other researchers faced the same issues in other domains and have proposed domain-specific adversarial attacks.”
This led the team to create a generic framework that could be applied to many domains.
A generic framework for adversarial attack and defense
This is not the first time that adversarial attacks against constrained-domain problems have been studied. But most techniques have limitations that prevent them from being generalized across domains.
One type of approach is the “problem-space” attack, which works by manipulating domain objects, such as malware code (for malware-detection systems) and plain text (e.g., for spam detection), before mapping them to the ML model’s feature space.
“These attacks do not generalize beyond a single domain as they rely on specific transformations to alter the domain objects,” Cordy said. Object manipulation is also computationally more expensive than working on numerical feature vectors.
Another class of techniques is “feature-space” attacks, which directly try to modify the input features of the model.
“In the feature space, all data comes down to numbers so there is room for generalization,” Cordy said. “The domain constraints that define the validity rules for input features, however, remain bounded to the considered domain.”
Once a feature-space adversarial attack technique is developed for one domain, it would require significant modification before it can be applied to other domains.
“The challenges are to provide a language to define constraints that is sufficiently expressive and, at the same time, to enable these constraints to be efficiently handled by an attack algorithm,” Cordy said.

In their paper, Cordy and his co-authors propose a “unified framework for constrained feature-space attacks” that can create feasible examples and be applied to different domains without tuning.
The framework is composed of a “constraint language” and adversarial attack techniques. The constraint language is a general system for defining the boundaries of features and the relations between them. These features are then automatically translated to adversarial attack techniques.
The researchers present two attack techniques. The first, “Constrained Projected Gradient Descent” (C-PGD), is a modified version of PGD, a popular adversarial attack method. C-PGD incorporates differentiable constraints into its loss function that the algorithm maximizes (like ML models, PGD uses differentiable loss and gradient-based algorithms to tune its parameters). The algorithm then uses post-processing computations to apply the non-differentiable constraints to the generated examples.
The second attack technique, “Multi-Objective EVolutionary Adversarial Attack” (MoEvA2), uses genetic algorithms that treat misclassification, perturbation distance, and constraint satisfaction as three objectives to optimize. The genetic algorithm approach is especially convenient in applications where constraints cannot be represented as differentiable functions.
Their experiments show C-PGD and MoEvA2 provide a significant boost in success rates in comparison to classic adversarial attack techniques. “While adversarial attacks unaware of domain constraints fail, incorporating constraint knowledge as an attack objective enables the successful generation of constrained adversarial examples,” the researchers write.
However, MoEvA2 has a clear advantage over all other techniques and can reach up to 100-percent success rate in some applications.
“The advantage of genetic algorithms (more generally, of black-box search algorithms) is that they can directly include constraint satisfaction within a multi-objective fitness function (next to model misclassification and perturbation threshold),” Cordy said. “Gradient-based attacks necessitate a differentiable loss function to work. The only way to make these attacks constraint-aware is to incorporate the constraints as a new, differentiable term in the loss function. However, many real-world constraints that we have observed are not differentiable. This is why our constraint-aware gradient-based attack (named C-PGD in the paper) works with limited success.”
The researchers tested both attack techniques against neural networks and random forests trained for four binary classification applications, including credit approval, network traffic classification, malware detection, and phishing URL detection. According to Cordy, the technique can easily be extended to more complicated domains.
“Our approach can be straightforwardly extended to multi-class model by modifying the misclassification objective,” Cordy said. “It can work with both an untargeted objective (model should classify the input in any incorrect) and a targeted objective (model should classify in a specified class).”

Defending against adversarial attacks
Extending their work, the researchers tried to see how their findings could be used to make machine learning models more robust against adversarial attacks. First, they used adversarial retraining, a common defense technique in which an ML model goes through extra training on adversarial examples and their correct labels. In this case, the ML models were retrained on examples generated by C-PGD and MoEvA2.
The researchers’ findings show that adversarial retraining with the two techniques is an effective defense against constrained adversarial attacks. However, MoEvA2 still managed to retain around 85-percent efficiency, which, according to the researchers, suggests that “the large search space that this search algorithm explores preserves its effectiveness.”
The researchers suggest a second defense mechanism, which they call “engineered constraints.” Basically, this method introduces some non-convex constraints in the ML model by adding features that are non-differentiable.
Expectedly, this new method makes the gradient-based adversarial attacks extremely unstable and drops their success rate to near zero. On the other hand, MoEvA2 can still maintain its success rate, but the search space becomes much larger and more complex. As a result, the genetic algorithm requires ten times more generations than before to reach its previous accuracy.
The researchers see potential directions to further build on and improve the techniques.
“As researchers, our ultimate goal is to help protect real-world models against adversarial threats,” Cordy said. “To this aim, our work can be improved in two ways. first, to increase the computational efficiency of adversarial training by mixing feasible examples (produced by our approach) and infeasible examples (produced by classical attacks, which are more efficient than our constrained approach). Second, to facilitate the constraint elicitation phase by developing automated methods to learn the constraints out of available inputs. These two contributions combined would enable proper assessment and improvement of model robustness against realistic attacks.”